 PDF(1651 KB)
PDF(1651 KB)

High Correct Recognition Rate Classifier Design with Appropriate Rejection Mechanism
YANG Guo-wei, WAN Ming-hua, LAI Zhi-hui, ZHANG Fan-long, WONG Wai-keung
ACTA ELECTRONICA SINICA ›› 2021, Vol. 49 ›› Issue (8) : 1569-1576.
PDF(1651 KB)
PDF(1651 KB)
High Correct Recognition Rate Classifier Design with Appropriate Rejection Mechanism
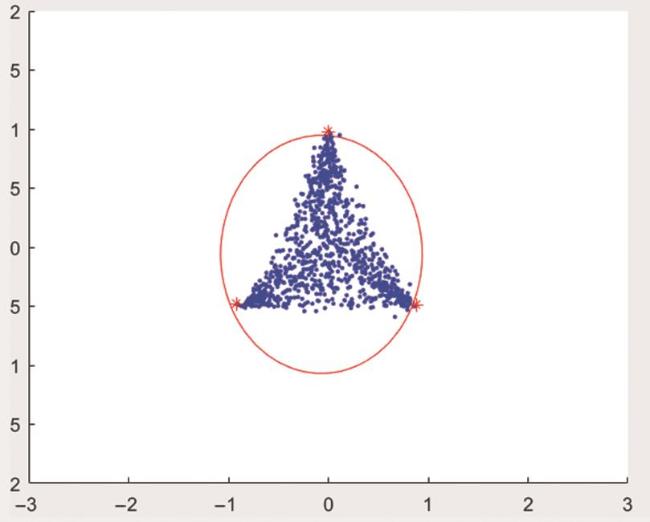
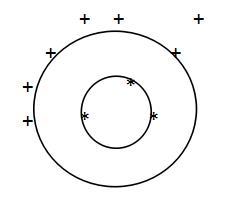
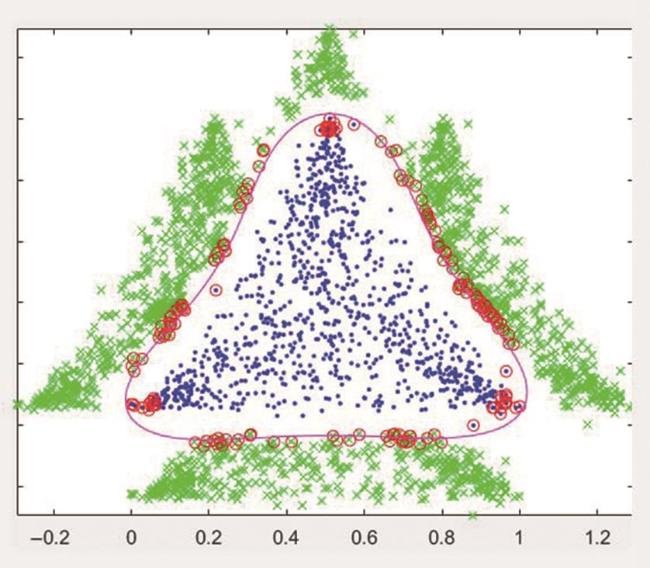
At present, some SVM(Support Vector Machines) classifiers, hypersphere SVM classifier and deep learning classifier with high correct recognition rate still have about 2% false recognition rate and weak incremental learning function. In this paper, a high correct recognition rate classifier designed with appropriate rejection mechanism and incremental learning algorithm is proposed to solve the above problems. The main work include: the construction algorithm of compact packing set of homogeneous feature set; the algorithm for solving the compact packing surface of homogeneous feature region based on homogeneous feature set and compact packing set; the method of setting all the public areas outside the compact packing surface as the rejection area of the classifier; when adding new categories, increasing or decreasing training samples, the above algorithms are incremental learning algorithms. A comparison experiment with uci data sets shows that the correct recognition rate of the classifier is greater than 99.13%, when the rejection rate is less than 1.3%.
classifier / pattern recognition / support vector machine / incremental learning / classification surface / wrapping learning {{custom_keyword}} /
表1 实验数据集表 |
| Dataset | pos | neg | m 1 | m 2 | d |
|---|---|---|---|---|---|
| Iris | 50 | 100 | 45 | 90 | 4 |
| Wine | 59 | 119 | 53 | 107 | 13 |
| Blood | 570 | 178 | 487 | 15 | 4 |
| Cancer | 444 | 239 | 398 | 12 | 9 |
表2 学习算法的几个参量 |
| Dataset | v | v 1 | v 2 |
|---|---|---|---|
| Iris | 10 | 0.1 | 0.1 |
| Wine | 10 | 0.1 | 0.1 |
| Blood | 50 | 0.1 | 0.1 |
| Cancer | 30 | 0.1 | 0.01 |
表3 实验结果 |
| Dataset | SVM | SVDD | SSLM | 深层感知 网络 | 包裹学习(不设置拒识区域) | 包裹学习(设置拒识区域) | |
|---|---|---|---|---|---|---|---|
| 正确识别率 | 拒识率 | ||||||
| Iris | 96.3% | 96.5% | 98.2% | 98.8% | 98.5% | 优化致密参数后100% | 优化致密参数后1.3% |
| 优化致密参数前99.3% | 优化致密参数前1.2% | ||||||
| Wine | 93.75% | 95.34% | 97.1% | 98.3% | 97.7% | 优化致密参数后100% | 优化致密参数后2.1% |
| 优化致密参数前99.1% | 优化致密参数前1.9% | ||||||
| Blood | 68.67% | 71.12% | 71.33% | 77.25% | 72.67% | 优化致密参数后99.32% | 优化致密参数后2.3% |
| 优化致密参数前99.1% | 优化致密参数前1.9% | ||||||
| Blood | 68.67% | 71.12% | 71.33% | 77.25% | 72.67% | 优化致密参数后99.32% | 优化致密参数后2.3% |
| 优化致密参数前99.15% | 优化致密参数前2.1% | ||||||
| Cancer | 94.75% | 93.78% | 95.25% | 98.54% | 97.45% | 优化致密参数后99.15% | 优化致密参数后1.8% |
| 优化致密参数前99.1% | 优化致密参数前1.7% | ||||||
| 1 |
王守觉. 仿生模式识别(拓扑模式识别): 一种模式识别新模型的理论与应用[J]. 电子学报, 2002, 30(10): 1417-1420.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
周志华. 机器学习[M]. 北京: 清华大学出版社, 2016.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
Jayadeva,
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
舒坚, 张学佩, 刘琳岚, 等. 基于深度卷积神经网络的多节点间链路预测方法[J]. 电子学报, 2018, 46(12): 2970-2977.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(1651 KB)
PDF(1651 KB)

/
| 〈 |
|
〉 |







{kind=link}
{kind=link}
{kind=link}