 PDF(1498 KB)
PDF(1498 KB)

Dental Model Segmentation Network Based on Local Attention Mechanism
ZHANG Ling-ming, ZHAO Yue, LI Peng-cheng, LIU Yang, GAO Chen-qiang
ACTA ELECTRONICA SINICA ›› 2022, Vol. 50 ›› Issue (3) : 681-690.
PDF(1498 KB)
PDF(1498 KB)
Dental Model Segmentation Network Based on Local Attention Mechanism
Accurate tooth segmentation from 3D dental model is the basis of computer-aided-design (CAD) for orthodontic treatment. Due to the relatively coarse modeling of local feature, existing 3D shape segmentation networks cannot effectively extract more detailed local feature on teeth boundaries. This issue will further result in over-segmentation or under-segmentation on boundaries. In this paper, a 3D dental model segmentation network based on local attention mechanism is proposed to improve segmentation performance on teeth boundaries. Firstly, multi-scale local spaces are constructed for 3D mesh data of raw dental model. Secondly, attention weights are learned based on the spatial distribution and feature differences of meshes for each local space. Finally, a local feature aggregation is applied based on learned attention weights of meshes to make the network automatically focus on more representive mesh features in each local space. The proposed network is evaluated on a real-patient datasets, and the experimental results show that our network can more clearly and accurately segment teeth boundaries when compared with existing methods.
3D mesh data / oral scanning data / 3D dental model / tooth segmentation / attention mechanism {{custom_keyword}} /
表1 本文网络与现有方法在3折交叉验证下的分割准确率对比 (均值 |
表2 本文网络与现有方法在3折交叉验证下的分割交并比对比 |
| 模型 | T0 | T1 | T2 | T3 | T4 | T5 | T6 | T7 | mIoU |
|---|---|---|---|---|---|---|---|---|---|
| PointNet[5] | 0.826 | 0.413 | 0.495 | 0.528 | 0.619 | 0.621 | 0.567 | 0.684 | 0.590 |
| PointNet++[7] | 0.863 | 0.719 | 0.741 | 0.734 | 0.787 | 0.757 | 0.705 | 0.776 | 0.760 |
| PointCNN[6] | 0.849 | 0.696 | 0.731 | 0.725 | 0.786 | 0.748 | 0.651 | 0.721 | 0.738 |
| MeshSegNet[4] | 0.911 | 0.811 | 0.821 | 0.814 | 0.838 | 0.840 | 0.811 | 0.847 | 0.837 |
| 本文方法 | 0.915 | 0.848 | 0.877 | 0.856 | 0.880 | 0.868 | 0.831 | 0.848 | 0.865 |
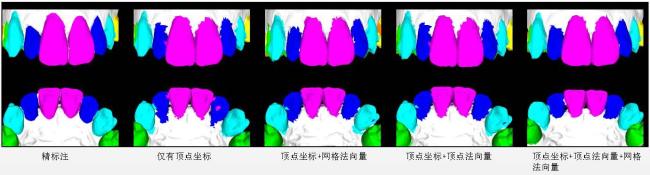
表3 本文网络在不同输入组合下的分割指标 |
| 输入组合 | Accuracy | mIoU |
|---|---|---|
| 顶点坐标 | 0.887 | 0.752 |
| 顶点坐标+网格法向量 | 0.919 | 0.820 |
| 顶点坐标+顶点法向量 | 0.934 | 0.851 |
| 顶点坐标+顶点法向量+网格法向量 | 0.943 | 0.865 |
表4 本文网络使用不同模块的分割指标 |
| 模型 | Accuracy | mIoU |
|---|---|---|
| 仅空间信息增强 | 0.910 | 0.802 |
| 仅局部注意机制 | 0.926 | 0.835 |
| 完整网络结构 | 0.943 | 0.865 |
表5 本文网络在不同网格分辨率下的分割指标 |
| 分辨率 | Accuracy | mIoU |
|---|---|---|
| | 0.884 | 0.768 |
| | 0.916 | 0.815 |
| | 0.927 | 0.841 |
| | 0.943 | 0.865 |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
罗会兰, 张云. 基于深度网络的图像语义分割综述[J]. 电子学报, 2019, 47(10): 2211‑2220.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
梁新宇, 林洗坤, 权冀川, 肖铠鸿. 基于深度学习的图像实例分割技术研究进展[J]. 电子学报, 2020, 48(12): 2476‑2486.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 24 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 25 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 26 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 27 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 28 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 29 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 30 |
彭秀平, 仝其胜, 林洪彬, 等. 一种面向散乱点云语义分割的深度残差-特征金字塔网络框架[J].自动化学报, 2021, 47(12): 2831‑2840.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 31 |
盖杉, 王俊生. 基于深度学习的非局部注意力增强网络图像去雨算法研究[J]. 电子学报, 2020, 48(10): 1899‑ 1908.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 32 |
唐海桃, 薛嘉宾, 韩纪庆. 一种多尺度前向注意力模型的语音识别方法[J]. 电子学报, 2020, 48(07): 1255‑1260.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 33 |
张志昌, 曾扬扬, 庞雅丽. 融合语义角色和自注意力机制的中文文本蕴含识别[J]. 电子学报, 2020, 48(11): 2162‑2169.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(1498 KB)
PDF(1498 KB)
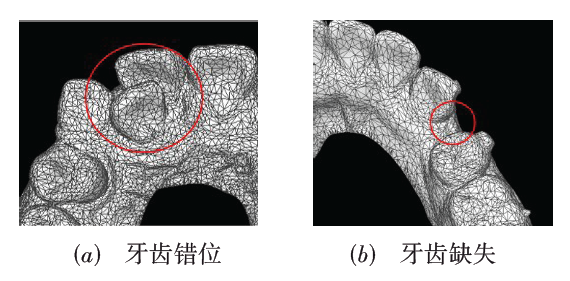
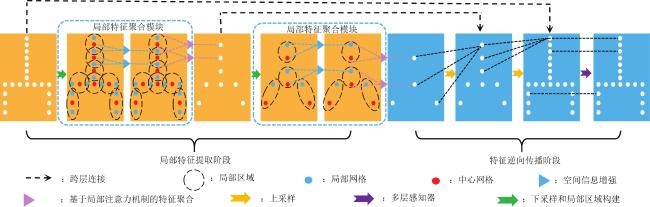
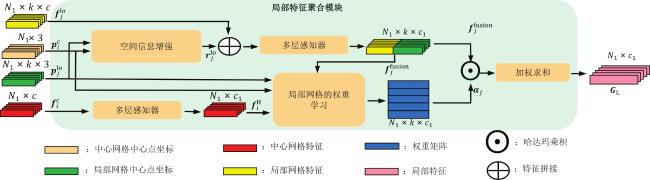
 图1 三维牙齿模型中牙齿错位和缺牙示意图图2 本文网络的整体结构示意图图3 局部特征聚合模块框图
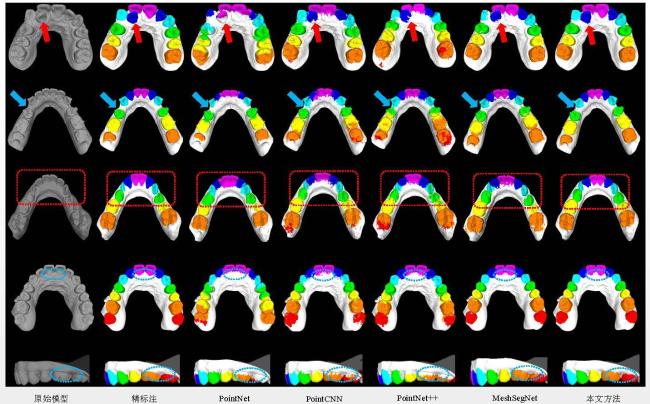
图1 三维牙齿模型中牙齿错位和缺牙示意图图2 本文网络的整体结构示意图图3 局部特征聚合模块框图 表1 本文网络与现有方法在3折交叉验证下的分割准确率对比 (均值±标准差)表2 本文网络与现有方法在3折交叉验证下的分割交并比对比图4 本文网络与四种对比网络的分割结果可视化对比表3 本文网络在不同输入组合下的分割指标图5 不同输入组合的分割结果可视化对比表4 本文网络使用不同模块的分割指标图6 本文网络使用不同模块的分割结果可视化对比表5 本文网络在不同网格分辨率下的分割指标
表1 本文网络与现有方法在3折交叉验证下的分割准确率对比 (均值±标准差)表2 本文网络与现有方法在3折交叉验证下的分割交并比对比图4 本文网络与四种对比网络的分割结果可视化对比表3 本文网络在不同输入组合下的分割指标图5 不同输入组合的分割结果可视化对比表4 本文网络使用不同模块的分割指标图6 本文网络使用不同模块的分割结果可视化对比表5 本文网络在不同网格分辨率下的分割指标
/
| 〈 |
|
〉 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}