 PDF(1656 KB)
PDF(1656 KB)

Skeleton Action Recognition Based on Multi-Stream Spatial Attention Graph Convolutional SRU Network
ZHAO Jun-nan, SHE Qing-shan, MENG Ming, CHEN Yun
ACTA ELECTRONICA SINICA ›› 2022, Vol. 50 ›› Issue (7) : 1579-1585.
PDF(1656 KB)
PDF(1656 KB)
Skeleton Action Recognition Based on Multi-Stream Spatial Attention Graph Convolutional SRU Network
Action recognition with skeleton data has attracted more attention. In order to solve the problems of low reasoning speed and single data mode of most algorithms, a lightweight and efficient method is proposed. The network embeds the graph convolution operator in the simple recurrent unit(SRU) to construct the graph convolutional SRU(GC-SRU), which can capture the spatial-temporal information of data. Meanwhile, to enhance the distinction between nodes, spatial attention network and multi-stream data fusion are used to expand GC-SRU into multi-stream spatial attention graph convolutional SRU(MSAGC-SRU). Finally, the proposed method is evaluated on two public datasets. Experimental results show that the classification accuracy of our method on Northwestern-UCLA reaches 93.1% and the FLOPs of the model is 4.4G. The accuracy on NTU RGB+D reaches 92.7% and 87.3% under the CV and CS evaluation protocols, respectively, and the FLOPs of the model is 21.3G. The proposed model has achieved good trade-off between computational efficiency and classification accuracy.
action recognition / graph convolution / attention mechanism / data fusion {{custom_keyword}} /
表2 Northwestern‑UCLA数据集上消融实验结果 |
| Methods | Accuracy(%) | FLOPs(G) |
|---|---|---|
| SRU | 81.3 | — |
| GC-SRU | 84.8 | 3.0 |
| MSGC-SRU | 90.3 | 3.5 |
| SAGC-SRU | 90.1 | 3.9 |
| MSAGC-SRU | 93.1 | 4.4 |
表3 在Northwestern‑UCLA 上测试不同算法训练和测试1 000次样本的时间 |
| Methods | Training time(s) | Testing time(s) |
|---|---|---|
| SRU | 5.93 | 1.00 |
| GC-SRU | 6.08 | 1.86 |
| MSGC-SRU | 6.38 | 2.04 |
| AGC-LSTM[3] | 14.30 | 4.74 |
| SAGC-SRU | 6.49 | 2.04 |
| MSAGC-SRU | 6.77 | 2.36 |
| 1 |
罗会兰, 童康, 孔繁胜. 基于深度学习的视频中人体动作识别进展综述[J].电子学报, 2019, 47(5): 1162-1173.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
朱红蕾, 朱昶胜, 徐志刚.人体行为识别数据集研究进展[J]. 自动化学报, 2018, 44(6): 978-1004.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
穆高原. 基于深度学习的危险驾驶行为识别研究[D]. 杭州: 杭州电子科技大学, 2020.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(1656 KB)
PDF(1656 KB)
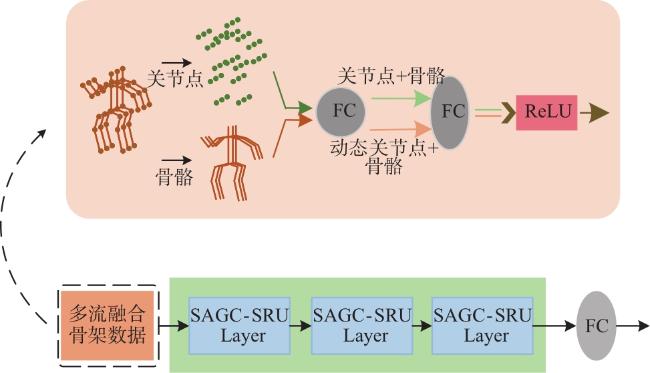
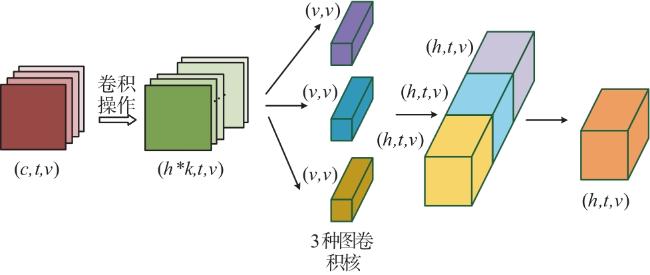
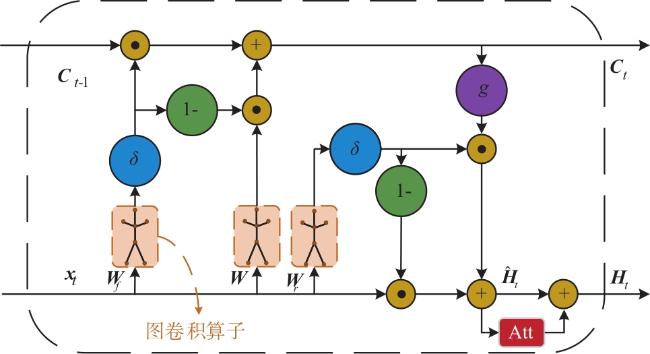
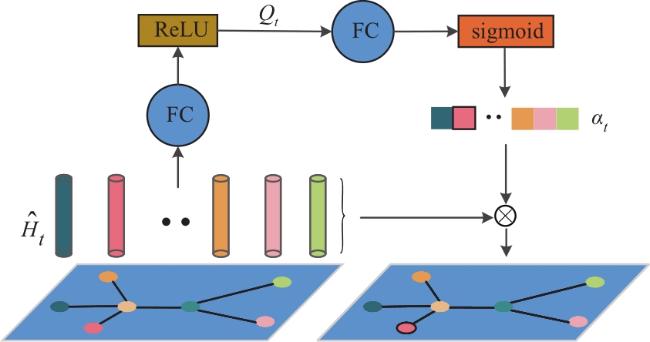
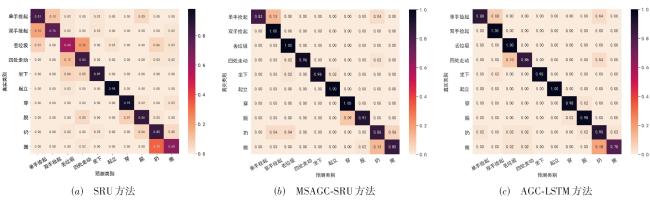
 图1 MSAGC-SRU网络架构图2 GCN可视化过程图3 SAGC-SRU模型结构图4 空间注意力网络
图1 MSAGC-SRU网络架构图2 GCN可视化过程图3 SAGC-SRU模型结构图4 空间注意力网络 表1 Northwestern‑UCLA数据集上实验结果比较表2 Northwestern‑UCLA数据集上消融实验结果表3 在Northwestern‑UCLA 上测试不同算法训练和测试1 000次样本的时间表4 在NTU RGB+D数据集上实验结果比较图5 Northwestern-UCLA数据集上测试结果的混淆矩阵对比图
表1 Northwestern‑UCLA数据集上实验结果比较表2 Northwestern‑UCLA数据集上消融实验结果表3 在Northwestern‑UCLA 上测试不同算法训练和测试1 000次样本的时间表4 在NTU RGB+D数据集上实验结果比较图5 Northwestern-UCLA数据集上测试结果的混淆矩阵对比图
/
| 〈 |
|
〉 |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}