 PDF(782 KB)
PDF(782 KB)

Cryptojacking Malware Hunting: A Method Based on Ensemble Learning of Hierarchical Threat Intelligence Feature
ZHENG Rui, WANG Qiu-yun, LIN Zhuo-pang, JING Rong-qi, JIANG Zheng-wei, FU Jian-ming, WANG Shu-wei
ACTA ELECTRONICA SINICA ›› 2022, Vol. 50 ›› Issue (11) : 2707-2715.
PDF(782 KB)
PDF(782 KB)
Cryptojacking Malware Hunting: A Method Based on Ensemble Learning of Hierarchical Threat Intelligence Feature
Cryptojacking malware is a new type of malware that has emerged in recent years and poses a significant threat to user host security. By studying static features of cryptojacking malware, a detection method is proposed based on integrating hierarchical threat intelligence features. We train cryptojacking malware detectors using the raw byte feature, PE(Portable Executable) parsing feature, and cryptocurrency mining operation feature, respectively. Then, the ensemble learning is used for combining these detectors to form a cryptojacking malware detector from the perspective of hierarchical threat intelligence. In the experiments, the simulated lab dataset and the simulated real-world dataset are used for performance evaluation. The experimental results show that the proposed method acquires 97.01% accuracy rate, which gets improvements of 6.13% relative to the baseline method.
cryptojacking malware / threat intelligence / machine learning / ensemble learning / deep learning / blockchain / opcode {{custom_keyword}} /
表1 字节码特征层的特征类别 |
| 特征类别 | 特征数学形式 | 特征维度 |
|---|---|---|
| 原始字节 | 一维矩阵 | 1000 kB |
| 灰度图片 | 二维矩阵 | 163 pixel×65 pixel |
| 熵直方图 | 一维/二维矩阵 | 512/16×32 |
表2 PE结构信息的组成 |
| 特征 | 特征维度 |
|---|---|
| 一般文件信息 | 10 |
| PE头信息 | 62 |
| 节区特征 | 255 |
| 函数导出表 | 128 |
| PE文件熵特征 | 256 |
| PE文件字节统计特征 | 256 |
表3 挖矿操作执行特征层部分特征描述 |
| 特征分组 | 特征代码 | 特征描述 |
|---|---|---|
| 挖矿动作特征 | cpu_count | "cpu"字符出现的次数 |
| gpu_count | "gpu"字符出现的次数 | |
| opcode_var | 所有代码片段中opcode个数的方差 | |
| pool_name_count | 出现矿池地址的次数 | |
| 恶意软件基本属性 | size_X | 可执行节的平均长度 |
| rsrc_num | PE文件中资源节的个数 | |
| 字符规则特征 | paths_count | 系统文件路径匹配的个数 |
| yargen_count | 使用Yara gen工具生成的Yara 规则的匹配次数 | |
| 免杀特征 | av_count | Anti-virus名称字符命中的个数 |
表4 不同特征对应的机器学习模型的主要结构与参数 |
| 特征 | 模型结构 |
|---|---|
| EH | Conv60*(2,2) + Conv200*(2,2) + Dense(500) |
| EH | Dense(1500) + Dense(1000) + Dense(500) |
| GI | 2*[Conv32(3,3)] + 2*[Conv64(3,3)] +2*[Conv128(3,3)] |
| RB | Embedding+Conv1D(128)*λConv1D(128) |
| PF | LightGBM: 100 trees, 31 leaves per tree |
| CF | GBDT: depth=4; # of leaves=20 |
表5 随机森林(RF)与逻辑回归(LR)取得性能领先组合个数 |
| 组合类别 | 集成方法 | 领先组合数 |
|---|---|---|
| 威胁情报分层组合 | LR | 4 |
| RF | 0 | |
| 其他组合 | LR | 12 |
| RF | 4 |
表6 Datacon2020数据集的数量分布 |
| 实验 | 数据集A | 数据集B | ||
|---|---|---|---|---|
| CMal | Not CMal | CMal | Not CMal | |
| 原始 | 2000 | 4000 | 5898 | 11759 |
| Opcode | 1885 | 3699 | 5823 | 11120 |
表7 模型方法在训练数据集上执行交叉验证测试的结果 |
表8 部分层次集成组合模型在模拟实验室数据集的测试结果 |
| 特征组合 | 准确率 | 精确率 | 召回率 | D-score |
|---|---|---|---|---|
| CF+PF+EHm | 0.9895 | 0.9954 | 0.9730 | 96.89 |
| CF+PF+RB | 0.9893 | 0.9944 | 0.9735 | 96.85 |
| CF+PF+GI | 0.9892 | 0.9939 | 0.9735 | 96.80 |
| CF+PF+EHc | 0.9892 | 0.9949 | 0.9725 | 96.79 |
| RB+EHm+GI | 0.9815 | 0.9933 | 0.9510 | 94.49 |
表9 单机器学习模型方法在模拟真实环境数据集上测试的结果 |
表10 层次特征集成方法在模拟真实世界数据集上的检测效果 |
| 特征组合 | 准确率 | 精确率 | 召回率 | D-score |
|---|---|---|---|---|
| CF+PF+RB | 0.9701 | 0.9761 | 0.9334 | 91.19 |
| CF+PF+GI | 0.9700 | 0.9755 | 0.9335 | 91.15 |
| CF+PF+EHc | 0.9694 | 0.9750 | 0.9322 | 90.97 |
| CF+PF+EHm | 0.9690 | 0.9714 | 0.9346 | 90.89 |
| CF+EHc+EHm | 0.9647 | 0.9706 | 0.9223 | 89.58 |
| PF+EHm+GI | 0.9635 | 0.9615 | 0.9279 | 89.33 |
| EHc+EHm+GI | 0.9457 | 0.9517 | 0.8823 | 83.88 |
表11 两类特征层次组合在模拟真实世界数据集上的检测效果 |
| 集成方法 | Acc | Pre | Recall | D-score |
|---|---|---|---|---|
| CF+PF | 0.9700 | 0.9727 | 0.9364 | 91.18 |
| PF+RB | 0.9660 | 0.9685 | 0.9283 | 89.99 |
| CF+RB | 0.9685 | 0.9773 | 0.9273 | 90.68 |
| EHm+EHc | 0.9433 | 0.9393 | 0.8874 | 83.28 |
| EHm+GI | 0.9427 | 0.9352 | 0.8903 | 83.19 |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
安天.六小时处置挖矿蠕虫的内网大规模感染事件[EB/OL]. (2019-09-25)[2021-09-15].
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
Microsoft Threat Intelligence Center. Threat actor leverages coin miner techniques to stay under the radar-here's how to spot them[EB/OL]. (2020-11-30)[2021-09-20].
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
感谢奇安信公司开源了供科学研究的挖矿恶意软件数据集.



 PDF(782 KB)
PDF(782 KB)
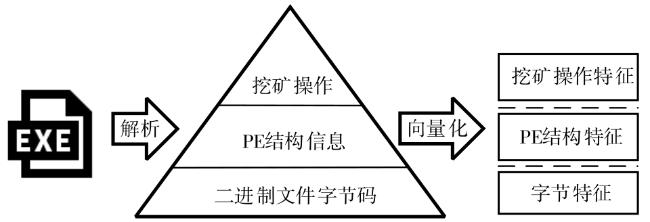
 图1 挖矿恶意软件的分层特征提取
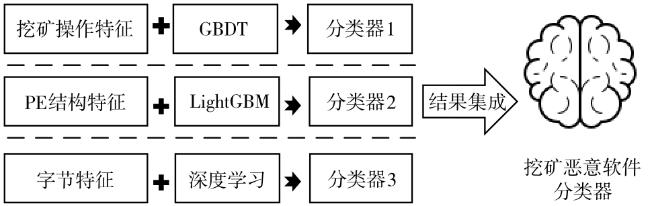
图1 挖矿恶意软件的分层特征提取 表1 字节码特征层的特征类别表2 PE结构信息的组成表3 挖矿操作执行特征层部分特征描述图2 机器学习方法及其集成学习表4 不同特征对应的机器学习模型的主要结构与参数表5 随机森林(RF)与逻辑回归(LR)取得性能领先组合个数表6 Datacon2020数据集的数量分布表7 模型方法在训练数据集上执行交叉验证测试的结果表8 部分层次集成组合模型在模拟实验室数据集的测试结果表9 单机器学习模型方法在模拟真实环境数据集上测试的结果表10 层次特征集成方法在模拟真实世界数据集上的检测效果表11 两类特征层次组合在模拟真实世界数据集上的检测效果表12 机器学习模型时间消耗对比 (s)
表1 字节码特征层的特征类别表2 PE结构信息的组成表3 挖矿操作执行特征层部分特征描述图2 机器学习方法及其集成学习表4 不同特征对应的机器学习模型的主要结构与参数表5 随机森林(RF)与逻辑回归(LR)取得性能领先组合个数表6 Datacon2020数据集的数量分布表7 模型方法在训练数据集上执行交叉验证测试的结果表8 部分层次集成组合模型在模拟实验室数据集的测试结果表9 单机器学习模型方法在模拟真实环境数据集上测试的结果表10 层次特征集成方法在模拟真实世界数据集上的检测效果表11 两类特征层次组合在模拟真实世界数据集上的检测效果表12 机器学习模型时间消耗对比 (s)
/
| 〈 |
|
〉 |





{kind=link}
{kind=link}