 PDF(2714 KB)
PDF(2714 KB)

Feature-Space Optimization-Inspired and Self-Attention Enhanced Neural Network Reconstruction Algorithm for Image Compressive Sensing
CHEN Wen-jun, YANG Chun-ling
ACTA ELECTRONICA SINICA ›› 2022, Vol. 50 ›› Issue (11) : 2629-2637.
PDF(2714 KB)
PDF(2714 KB)
Feature-Space Optimization-Inspired and Self-Attention Enhanced Neural Network Reconstruction Algorithm for Image Compressive Sensing
The existing optimization-inspired networks for image compressive sensing(ICS) implement information optimization and flow in the pixel domain following the traditional algorithms, which does not make full use of the information in the image feature maps extracted by the convolutional neural network. This paper proposes the idea of constructing information flow in the feature domain. A feature-space optimization-inspired network(FSOINet) is designed to implement this idea. Considering the small receptive field of the convolution operation, this paper introduces the self-attention module into FSOINet to efficiently utilize the non-local self-similarity of images to further improve the reconstruction quality, which is named FSOINet+. In addition, this paper proposes a training strategy that applies transfer learning to the ICS reconstruction network training for different sampling rates to improve the network learning efficiency and reconstruction quality. Experimental results show that the proposed method is superior to the existing state-of-the-art ICS methods in peak signal to noise ratio(PSNR), structural similarity index measure(SSIM) and the visual effect. Compared with OPINENet+ on the Set11 dataset, FSOINet and FSOINet+ have an average PSNR improvement of 1.04dB/1.27dB respectively.
image compressive sensing / deep learning / convolutional neural networks / self-attention / image reconstruction / transfer learning {{custom_keyword}} /
表1 Set11数据集中各采样率不同算法重构图像PSNR(dB)/SSIM对比 |
| 方法 | 采样率 | |||||
|---|---|---|---|---|---|---|
| 0.01 | 0.05 | 0.1 | 0.3 | 0.5 | 平均 | |
| GSR | 16.78/0.4520 | 22.79/0.7155 | 26.64/0.8562 | 34.77/0.9466 | 38.76/0.9721 | 27.95/0.7885 |
| SCSNet | 21.04/0.5562 | 25.85/0.7839 | 28.52/0.8616 | 34.64/0.9511 | 39.01/0.9769 | 29.81/0.8259 |
| CSNet+ | 21.02/0.5566 | 25.86/0.7846 | 28.34/0.8508 | 34.30/0.9490 | 38.52/0.9749 | 29.61/0.8232 |
| SPLNet | 21.22/0.5552 | 26.59/0.8177 | 29.49/0.8874 | 35.79/0.9603 | 40.27/0.9815 | 30.67/0.8404 |
| OPINENet+ | 20.02/0.5362 | 26.36/0.8186 | 29.81/0.8904 | 36.04/0.9600 | 40.19/0.9800 | 30.48/0.8370 |
| BCSNet | 20.81/0.5427 | 26.50/0.7893 | 29.36/0.8650 | 35.40/0.9527 | —— | —— |
| AMP-Net | 20.20/0.5425 | 26.17/0.8128 | 29.40/0.8876 | 36.03/0.9623 | 40.34/0.9821 | 30.43/0.8375 |
| MADUN | —— | —— | 29.91/0.8986 | 36.94/0.9676 | 40.77/0.9832 | —— |
| FSOINet* | 21.73/0.5937 | 27.36/0.8415 | 30.44/0.9018 | 37.00/0.9665 | 41.08/0.9832 | 31.52/0.8573 |
| FSOINet | 21.88/0.5958 | 27.30/0.8387 | 30.57/0.9020 | 37.00/0.9664 | 41.10/0.9833 | 31.57/0.8572 |
| FSOINet+ | 21.91/0.5984 | 27.47/0.8437 | 30.81/0.9056 | 37.30/0.9678 | 41.29/0.9837 | 31.76/0.8600 |
表2 各采样率不同算法在不同数据集上重构图像PSNR(dB)/SSIM对比 |
| 数据集 | 方法 | 采样率 | 平均 | ||||
|---|---|---|---|---|---|---|---|
| 0.01 | 0.05 | 0.1 | 0.3 | 0.5 | |||
| BSDS68 | CSNet+ | 21.71/0.5249 | 25.04/0.6845 | 26.89/0.7756 | 31.66/0.9152 | 35.42/0.9614 | 28.14/0.7723 |
| SCSNet | 21.88/0.5250 | 24.98/0.6843 | 27.13/0.7785 | 31.76/0.9173 | 35.67/0.9640 | 28.28/0.7738 | |
| SPLNet | 22.33/0.5242 | 25.87/0.7198 | 27.85/0.8094 | 32.77/0.9303 | 36.86/0.9708 | 29.13/0.7907 | |
| AMP-Net | 22.28/0.5315 | 25.77/0.7204 | 27.85/0.8113 | 32.84/0.9321 | 36.82/0.9715 | 29.11/0.7934 | |
| OPINENet+ | 21.88/0.5162 | 25.66/0.7136 | 27.81/0.8040 | 32.50/0.9236 | 36.32/0.9658 | 28.83/0.7846 | |
| FSOINet | 22.80/0.5435 | 26.24/0.7328 | 28.28/0.8185 | 33.28/0.9345 | 37.36/0.9728 | 29.59/0.8004 | |
| FSOINet+ | 22.83/0.5441 | 26.27/0.7340 | 28.39/0.8210 | 33.37/0.9352 | 37.47/0.9732 | 29.67/0.8015 | |
| Urban100 | CSNet+ | 19.27/0.4812 | 22.63/0.6792 | 24.64/0.7741 | 29.90/0.9162 | 33.55/0.9572 | 26.00/0.7616 |
| SCSNet | 19.28/0.4798 | 22.63/0.6774 | 24.93/0.7827 | 30.12/0.9193 | 33.92/0.9601 | 26.18/0.7639 | |
| SPLNet | 19.55/0.4873 | 23.55/0.7301 | 26.19/0.8290 | 32.11/0.9405 | 36.41/0.9737 | 27.56/0.7921 | |
| AMP-Net | 19.62/0.4969 | 23.45/0.7290 | 26.04/0.8283 | 32.19/0.9418 | 36.33/0.9737 | 27.53/0.7939 | |
| OPINENet+ | 19.38/0.4872 | 23.70/0.7363 | 26.61/0.8362 | 32.58/0.9414 | 36.62/0.9727 | 27.78/0.7948 | |
| FSOINet | 20.05/0.5257 | 24.66/0.7761 | 27.62/0.8623 | 33.88/0.9541 | 37.91/0.9788 | 28.82/0.8194 | |
| FSOINet+ | 20.14/0.5331 | 24.80/0.7805 | 28.05/0.8718 | 34.29/0.9569 | 38.31/0.9800 | 29.12/0.8245 | |
表3 不同采样率不同算法在Set11与BSDS68上的复杂度对比 |
| 方法 | 参数量 | 0.5采样率 | 0.1采样率 | ||
|---|---|---|---|---|---|
| Set11 | BSDS68 | Set11 | BSDS68 | ||
| 平均运行时间/s | |||||
| SPLNet | 1.388M | 0.0061 | 0.0076 | 0.0090 | 0.0089 |
| AMPNet | 1.529M | 0.0562 | 0.0671 | 0.0564 | 0.0649 |
| OPINENet+ | 1.095M | 0.0087 | 0.0126 | 0.0134 | 0.0132 |
| FSOINet | 1.061M | 0.0198 | 0.0184 | 0.0215 | 0.0190 |
| FSOINet+ | 1.086M | 0.0294 | 0.0264 | 0.0283 | 0.0258 |
表4 0.5采样率下不同模块的消融实验 |
| 模型设置 | 测试集PSNR/dB | ||||
|---|---|---|---|---|---|
| FSIM | DDM | WSEM | Set11 | BSDS68 | Urban100 |
| √ | × | × | 40.22 | 36.82 | 36.31 |
| × | √ | × | 39.65 | 36.36 | 35.38 |
| √ | √ | × | 41.10 | 37.36 | 37.91 |
| √ | √ | √ | 41.29 | 37.47 | 38.31 |
表5 不同训练策略的FSOINet在Set11上的重构图像PSNR(dB)/SSIM |
| 训练策略 | 0.01采样率 | 0.1采样率 | 0.3采样率 |
|---|---|---|---|
| 随机初始化训练40 epoch | 21.77/0.5920 | 30.31/0.8995 | 36.74/0.9651 |
| 随机初始化训练100 epoch | 21.81/0.5940 | 30.51/0.9021 | 36.96/0.9660 |
| 迁移学习40 epoch | 21.88/0.5958 | 30.57/0.9020 | 37.00/0.9664 |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
禤韵怡, 杨春玲. 基于帧间组稀疏的两阶段递归增强视频压缩感知重构网络[J]. 电子学报, 2021, 49(3): 435-442.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
裴翰奇, 杨春玲, 魏志超, 曹燕. 基于SPL迭代思想的图像压缩感知重构神经网络[J]. 电子学报, 2021, 49(6): 1195-1203.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 24 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 25 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 26 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(2714 KB)
PDF(2714 KB)
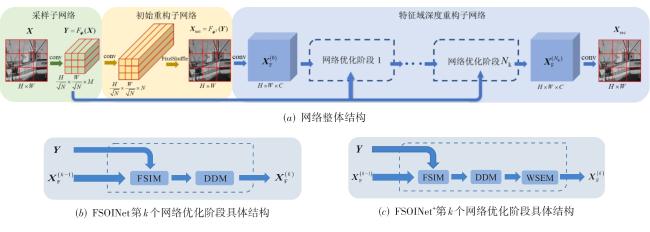
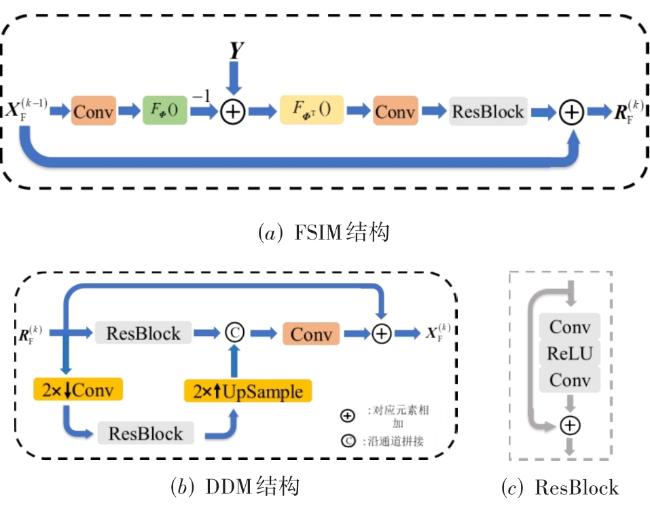
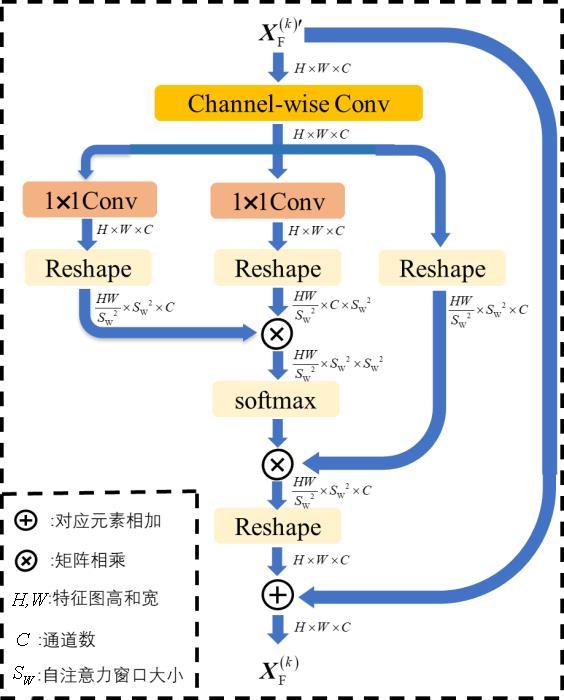
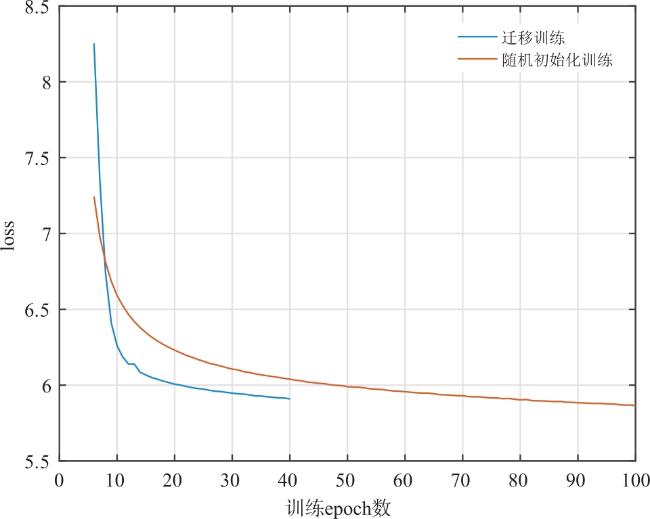
 图1 网络整体结构框架图2 特征域信息补充模块与双尺度去噪模块实现细节图3 WSEM结构
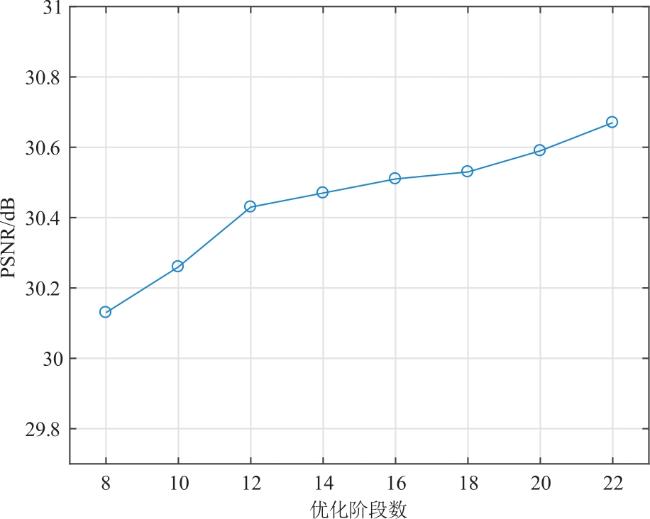
图1 网络整体结构框架图2 特征域信息补充模块与双尺度去噪模块实现细节图3 WSEM结构 表1 Set11数据集中各采样率不同算法重构图像PSNR(dB)/SSIM对比表2 各采样率不同算法在不同数据集上重构图像PSNR(dB)/SSIM对比图4 0.1采样率下图像Barbara(Set11)的重构图像视觉效果对比图5 0.3采样率下图像image_054(Urban100)的重构图像视觉效果对比表3 不同采样率不同算法在Set11与BSDS68上的复杂度对比图6 0.1采样率不同优化阶段数在Set11上的平均重构结果表4 0.5采样率下不同模块的消融实验图7 0.1采样率下不同参数初始化策略的训练loss曲线图表5 不同训练策略的FSOINet在Set11上的重构图像PSNR(dB)/SSIM
表1 Set11数据集中各采样率不同算法重构图像PSNR(dB)/SSIM对比表2 各采样率不同算法在不同数据集上重构图像PSNR(dB)/SSIM对比图4 0.1采样率下图像Barbara(Set11)的重构图像视觉效果对比图5 0.3采样率下图像image_054(Urban100)的重构图像视觉效果对比表3 不同采样率不同算法在Set11与BSDS68上的复杂度对比图6 0.1采样率不同优化阶段数在Set11上的平均重构结果表4 0.5采样率下不同模块的消融实验图7 0.1采样率下不同参数初始化策略的训练loss曲线图表5 不同训练策略的FSOINet在Set11上的重构图像PSNR(dB)/SSIM
/
| 〈 |
|
〉 |







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}