 PDF(1884 KB)
PDF(1884 KB)

Breast Cancer Pathological Image Classification Model via Combining Multi-View Transformer Coding and Online Fusion Mutual Learning
LI Guang-li, YE Yi-yuan, WU Guang-ting, LI Chuan-xiu, LÜ Jing-qin, ZHANG Hong-bin
ACTA ELECTRONICA SINICA ›› 2024, Vol. 52 ›› Issue (7) : 2369-2381.
PDF(1884 KB)
PDF(1884 KB)
Breast Cancer Pathological Image Classification Model via Combining Multi-View Transformer Coding and Online Fusion Mutual Learning
Breast cancer is the most common cancer in women. The single neural network used in breast cancer pathological image classification has the following defects: the convolutional neural network (CNN) lacks the ability to extract global context information while the Transformer lacks the ability to depict local lesion details. To alleviate the problem, a novel model, named multi-view Transformer coding and online fusion mutual learning (MVT-OFML), is proposed for breast cancer pathological image classification. First, ResNet-50 is employed to extract local features in images. Then, a new multi-view Transformer (MVT) coding module is designed to capture the global context information. Finally, a novel online fusion mutual learning (OFML) framework based on the Logits and middle feature layers is designed to implement the bi-directional knowledge transfer between ResNet-50 and the MVT coding module. This makes the two networks complement each other to complete breast cancer pathological image classification. Experiments validated on BreakHis and BACH show that compared to the best baseline, the performance improvements of accuracy are 0.90% and 2.26%, respectively, whereas the corresponding improvements of average F 1 score are 4.75% and 3.21%, respectively.
breast cancer / pathological image classification / multi-view Transformer / convolution neural network / online fusion mutual learning {{custom_keyword}} /
表1 经过Mixup 数据增强之后的BreakHis数据集分布情况 |
| 数据集 | 训练 | 测试 | ||
|---|---|---|---|---|
| 良性图像 | 恶性图像 | 良性图像 | 恶性图像 | |
| 原始数据集 | 1 736 | 3 800 | 744 | 1 629 |
| 增强数据集 | 6 944 | 15 200 | 744 | 1 629 |
表2 经过Mixup 数据增强之后的BACH数据集分布情况 |
| 数据集 | 训练 | 测试 | ||||||
|---|---|---|---|---|---|---|---|---|
| 正常 | 良性 | 原位癌 | 浸润性癌 | 正常 | 良性 | 原位癌 | 浸润性癌 | |
| 原始数据集 | 70 | 70 | 70 | 70 | 30 | 30 | 30 | 30 |
| 增强数据集 | 280 | 280 | 280 | 280 | 30 | 30 | 30 | 30 |
表3 BreakHis数据集上MVT-OFML模型与主流方法的2分类性能对比 |
| 主干网络或方法 | 发表年份 | 放大倍数/倍 | 准确率/% | 精确率/% | 召回率/% | F 1分数/% |
|---|---|---|---|---|---|---|
| IDSNet [25] | 2020 | 40 | 91.50 | 90.55 | 91.00 | 90.54 |
| 100 | 90.40 | 91.23 | 90.56 | 90.78 | ||
| 200 | 95.30 | 95.33 | 95.66 | 95.39 | ||
| 400 | 86.70 | 89.35 | 88.42 | 89.47 | ||
| DCET-Net [18] | 2021 | 40 | 99.00 | 99.47 | 97.38 | 98.41 |
| 100 | 98.08 | 94.79 | 98.91 | 96.81 | ||
| 200 | 99.34 | 97.66 | 97.82 | 98.82 | ||
| 400 | 98.72 | 98.22 | 97.65 | 97.93 | ||
| RANet-ADSVM [13] | 2022 | 40 | 91.96 | 93.83 | 94.91 | 94.36 |
| 100 | 96.83 | 98.52 | 98.30 | 98.32 | ||
| 200 | 98.05 | 98.92 | 99.15 | 99.13 | ||
| 400 | 90.30 | 93.17 | 93.56 | 93.35 | ||
| VIT-DeiT [17] | 2022 | 40 | 99.43 | 99.38 | 99.46 | 99.40 |
| 100 | 98.34 | 98.31 | 98.51 | 98.35 | ||
| 200 | 98.27 | 98.32 | 98.27 | 98.23 | ||
| 400 | 98.82 | 98.57 | 98.78 | 98.65 | ||
| MVT-OFML | 2023 | 40 | 99.77 | 99.75 | 99.71 | 99.77 |
| 100 | 99.56 | 99.74 | 99.54 | 99.44 | ||
| 200 | 99.76 | 99.65 | 99.43 | 99.62 | ||
| 400 | 99.45 | 99.30 | 99.69 | 99.33 | ||
| 提升情况 | 40 | 0.34↑ | 0.37↑ | 0.25↑ | 0.37↑ | |
| 100 | 1.22↑ | 1.43↑ | 1.03↑ | 1.09↑ | ||
| 200 | 1.40↑ | 1.33↑ | 1.16↑ | 1.39↑ | ||
| 400 | 0.63↑ | 0.73↑ | 0.96↑ | 0.91↑ | ||
表4 MVT-OFML模型在BreakHis数据集上与其他主流方法的分类性能对比 |
| 主干网络或方法 | 发表年份 | 放大倍数/倍 | 准确率/% | 精确率/% | 召回率/% | F 1分数/% |
|---|---|---|---|---|---|---|
| Deep-Net [11] | 2020 | 40 | 94.43 | 95.25 | 95.55 | 95.39 |
| 100 | 94.45 | 94.64 | 94.64 | 94.42 | ||
| 200 | 92.27 | 90.71 | 92.24 | 91.42 | ||
| 400 | 91.15 | 90.74 | 91.09 | 90.75 | ||
| AnoGAN [26] | 2021 | 40 | 99.15 | 99.64 | 99.46 | 99.78 |
| 100 | 97.09 | 98.07 | 98.49 | 98.22 | ||
| 200 | 87.58 | 88.19 | 92.82 | 90.62 | ||
| 400 | 87.30 | 82.77 | 92.50 | 88.23 | ||
| BHC-Net [27] | 2022 | 40 | 94.71 | 95.25 | 95.55 | 95.39 |
| 100 | 94.60 | 94.51 | 94.64 | 94.42 | ||
| 200 | 92.35 | 90.71 | 92.24 | 91.42 | ||
| 400 | 91.50 | 90.74 | 91.09 | 90.75 | ||
| BreaST-Net [28] | 2022 | 40 | 96.00 | — | — | 95.80 |
| 100 | 92.60 | — | — | 92.40 | ||
| 200 | 93.50 | — | — | 93.60 | ||
| 400 | 91.50 | — | — | 93.20 | ||
| MVT-OFML | 2023 | 40 | 99.19 | 98.93 | 98.88 | 98.46 |
| 100 | 99.05 | 97.44 | 98.90 | 97.77 | ||
| 200 | 99.60 | 97.88 | 99.30 | 99.33 | ||
| 400 | 99.63 | 96.19 | 99.54 | 98.45 | ||
| 提升情况 | 40 | 3.19↑ | — | — | 2.66↑ | |
| 100 | 6.45↑ | — | — | 5.37↑ | ||
| 200 | 6.10↑ | — | — | 5.73↑ | ||
| 400 | 8.31↑ | — | — | 5.25↑ | ||
表5 MVT-OFML模型在BACH数据集上与其他主流方法的性能对比 (%) |
| 主干网络或方法 | 发表年份 | 准确率 | 精确率 | 召回率 | F 1分数 |
|---|---|---|---|---|---|
| Patch+Vote [29] | 2019 | 85.00 | 86.77 | 81.91 | 84.23 |
| Hybrid DNN [30] | 2020 | 95.29 | 94.46 | 94.43 | 94.31 |
| 3E-Net [31] | 2021 | 96.68 | 95.46 | 95.45 | 95.46 |
| TransMIL[22] | 2021 | 85.83 | 86.90 | 84.69 | 85.78 |
| MA-MIDN[23] | 2021 | 93.57 | 96.18 | 94.26 | 95.18 |
| MSMV-PFENet [32] | 2022 | 94.80 | 95.20 | 94.89 | 94.79 |
| MVT-OFML | 2023 | 98.94 | 98.56 | 98.48 | 98.67 |
| 提升情况 | 2.26↑ | 3.10↑ | 3.03↑ | 3.21↑ | |
表6 在BreakHis 数据集上的消融分析实验结果 (%) |
| 模型 | Mixup | ResNet-50 | Transformer | 多视角编码 | EC | AFC | 准确率 | F 1分数 |
|---|---|---|---|---|---|---|---|---|
| A | × | √ | × | × | × | × | 86.58 | 87.26 |
| B | × | × | √ | × | × | × | 84.33 | 84.95 |
| C | × | √ | √ | × | × | × | 88.75 | 88.69 |
| D | × | √ | √ | √ | × | × | 93.56 | 94.07 |
| E | × | √ | √ | √ | √ | × | 94.33 | 94.34 |
| F | × | √ | √ | √ | × | √ | 96.64 | 96.38 |
| G | × | √ | √ | √ | √ | √ | 97.12 | 97.00 |
| MVT-OFML | √ | √ | √ | √ | √ | √ | 98.65 | 98.83 |
表7 特定中间层特征的消融分析实验结果 (%) |
| 模型 | Mixup | ResNet-50 | Transformer | 多视角编码 | EC | AFC | 准确率 | F 1分数 |
|---|---|---|---|---|---|---|---|---|
| F | × | √ | √ | √ | × | AFC1 | 95.78 | 95.01 |
| F | × | √ | √ | √ | × | AFC2 | 96.31 | 96.17 |
| F | × | √ | √ | √ | × | AFC3 | 96.64 | 96.38 |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
宋杰, 肖亮, 练智超, 等. 基于深度学习的数字病理图像分割综述与展望[J]. 软件学报, 2021, 32(5): 1427-1460.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
范虹, 张程程, 侯存存, 等. 结合双树复小波变换和改进密度峰值快速搜索聚类的乳腺MR图像分割[J]. 电子学报, 2019, 47(10): 2149-2157.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
蒲秀娟, 刘浩伟, 韩亮, 等. 使用深度学习与海马体异构特征融合的阿尔茨海默病分类方法[J]. 电子学报, 2023, 51(11): 3305-3319.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
田永林, 王雨桐, 王建功, 等. 视觉Transformer研究的关键问题: 现状及展望[J]. 自动化学报, 2022, 48(4): 957-979.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 24 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 25 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 26 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 27 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 28 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 29 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 30 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 31 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 32 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 33 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 34 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(1884 KB)
PDF(1884 KB)
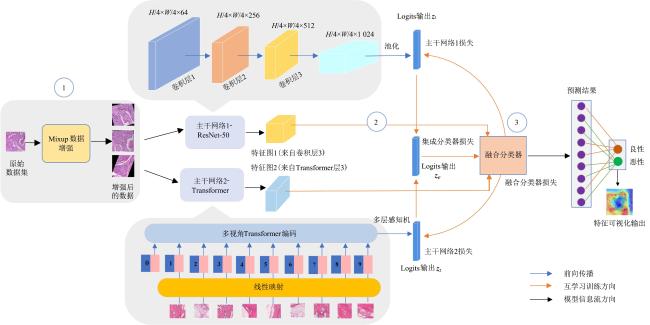
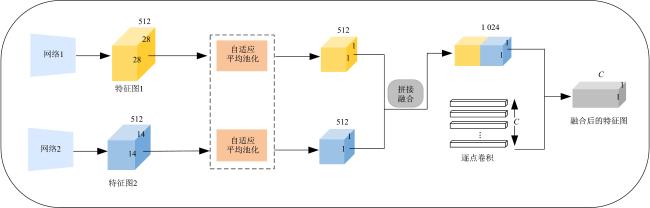
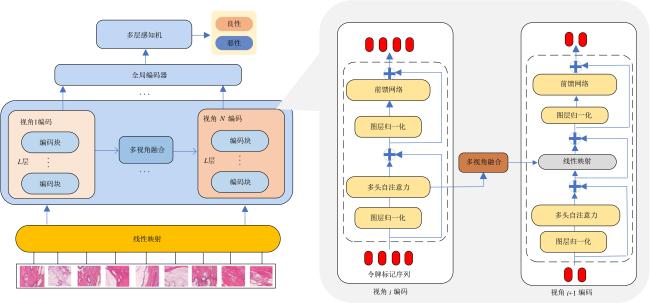
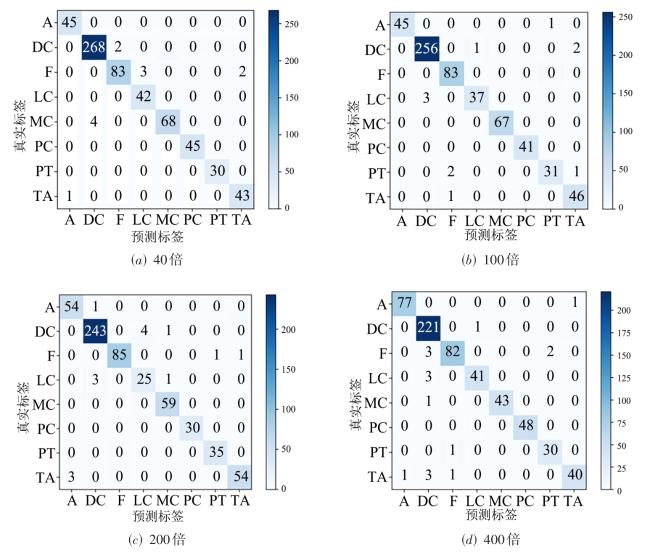
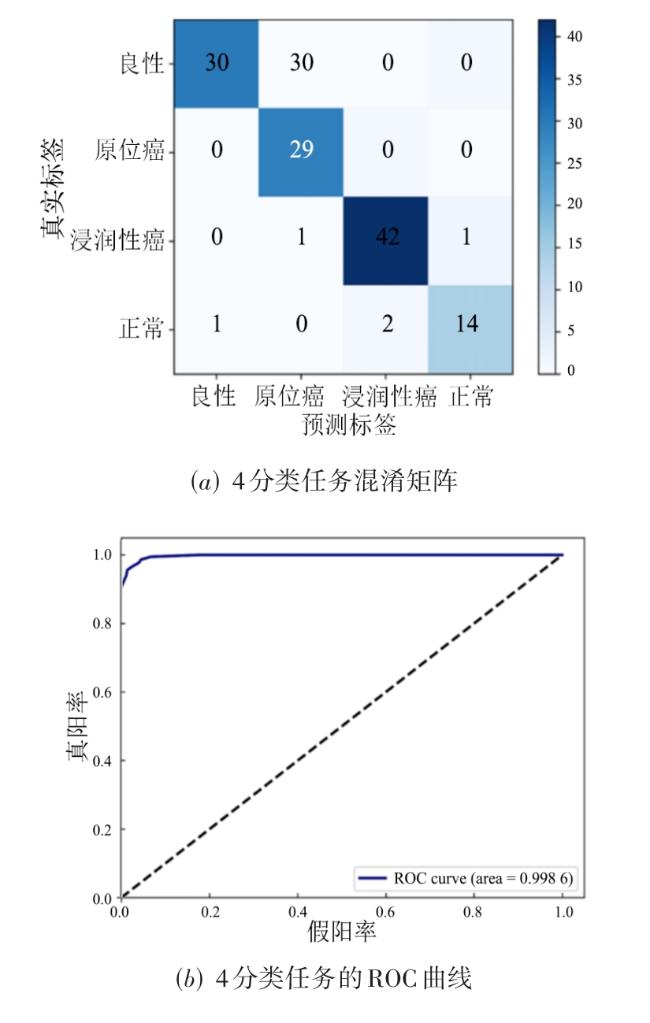
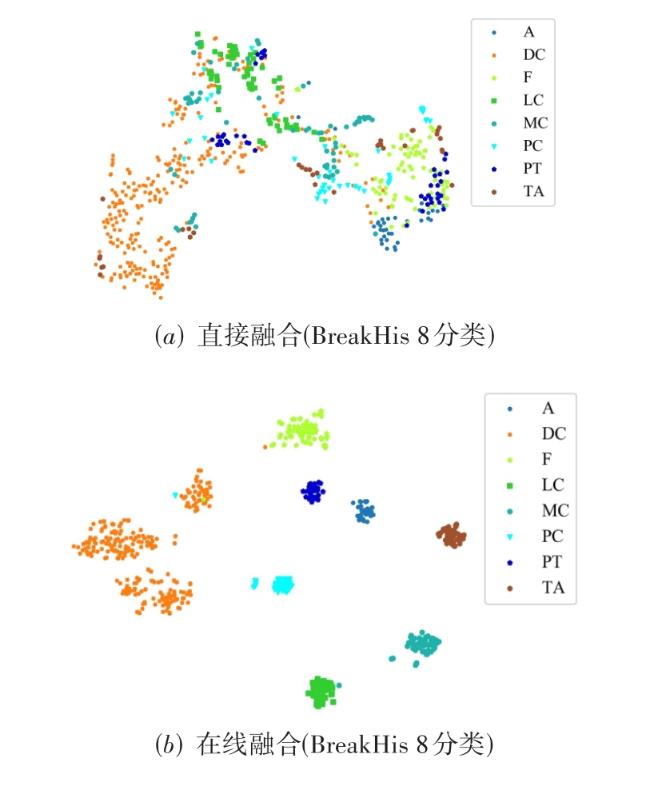
 图1 MVT-OFML模型总体图图2 融合分类器图3 多视角Transformer编码模块实现细节
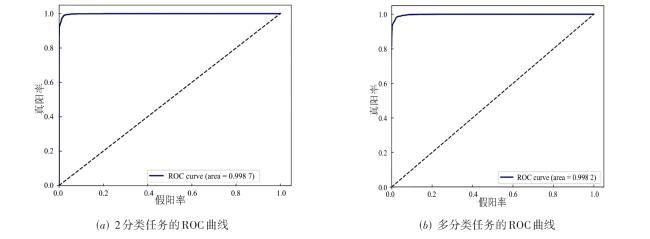
图1 MVT-OFML模型总体图图2 融合分类器图3 多视角Transformer编码模块实现细节 表1 经过Mixup 数据增强之后的BreakHis数据集分布情况表2 经过Mixup 数据增强之后的BACH数据集分布情况表3 BreakHis数据集上MVT-OFML模型与主流方法的2分类性能对比图4 MVT-OFML模型在BreakHis数据集上的ROC曲线表4 MVT-OFML模型在BreakHis数据集上与其他主流方法的分类性能对比图5 MVT-OFML模型在BreakHis数据集上8分类任务不同放大倍数的混淆矩阵表5 MVT-OFML模型在BACH数据集上与其他主流方法的性能对比 (%)图6 MVT-OFML模型在BACH数据集上的结果表6 在BreakHis 数据集上的消融分析实验结果 (%)表7 特定中间层特征的消融分析实验结果 (%)图7 t-SNE可视化结果图8 Grad-CAM可视化结果
表1 经过Mixup 数据增强之后的BreakHis数据集分布情况表2 经过Mixup 数据增强之后的BACH数据集分布情况表3 BreakHis数据集上MVT-OFML模型与主流方法的2分类性能对比图4 MVT-OFML模型在BreakHis数据集上的ROC曲线表4 MVT-OFML模型在BreakHis数据集上与其他主流方法的分类性能对比图5 MVT-OFML模型在BreakHis数据集上8分类任务不同放大倍数的混淆矩阵表5 MVT-OFML模型在BACH数据集上与其他主流方法的性能对比 (%)图6 MVT-OFML模型在BACH数据集上的结果表6 在BreakHis 数据集上的消融分析实验结果 (%)表7 特定中间层特征的消融分析实验结果 (%)图7 t-SNE可视化结果图8 Grad-CAM可视化结果
/
| 〈 |
|
〉 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}