 PDF(2505 KB)
PDF(2505 KB)

Autoimmune Dynamic Attack Generation Method Based on Reinforcement Learning
LI Teng, TANG Zhi-liang, MA Zhuo, MA Jian-feng
ACTA ELECTRONICA SINICA ›› 2023, Vol. 51 ›› Issue (11) : 3033-3041.
PDF(2505 KB)
PDF(2505 KB)
Autoimmune Dynamic Attack Generation Method Based on Reinforcement Learning
The approach of launching network attacks through optimal pathways has become a significant factor affecting the internal network security of various enterprises and organizations. Existing methods for exploring optimal attack pathways within internal networks mostly rely on attack graphs and often neglect the relationship between attack costs and benefits. Methods that utilize the Q-learning algorithm to address attack pathways suffer from low utilization of network vulnerability information. To address these issues, this paper draws inspiration from the biological immune system and proposes a reinforcement learning-based dynamic self-immune attack generation method. This method simulates network attacks by intruders on an internal network, efficiently uncovering vulnerabilities within the internal network, thereby achieving self-immune defense. The proposed approach first acquires and processes internal network information, attaches weights to directed edges in the attack graph, and then employs an improved Q-learning algorithm to discover optimal attack pathways. It successfully identifies all optimal attack pathways, providing attack graphs and an analysis of host vulnerabilities within these pathways. Theoretical analysis and experimental results demonstrate that this method not only efficiently and accurately identifies optimal attack pathways but also resolves issues such as ring loops and multiple optimal attack pathways. By making full use of internal network vulnerabilities, it enhances self-immune security defenses.
optimal attack path / reinforcement learning / attack graph / path planning / intranet security {{custom_keyword}} /
表1 Q‐learning算法中Q‐table |
| Q-table | | | |
|---|---|---|---|
| | | | |
| | | | |
| | | | |
| … | … | … | … |
| 算法1 改进后Q-learning算法 |
|---|
| 输入:起始节点、目标节点、奖励矩阵、网络拓扑信息、学习率、ε-贪婪算法参数 输出:最优攻击路径 初始化Q-table for e = 1 to episodes: 初始化状态s; repeat: 根据价值函数Q,通过策略(ε-贪婪算法)在状态s下选择动作 执行动作 until s 为终止条件 if(指定范围遍历Q-table,节点长度趋于稳定): break for; end for |
| 1 |
胡浩, 叶润国, 张红旗, 等. 基于攻击预测的网络安全态势量化方法[J]. 通信学报, 2017, 38(10): 122-134.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
闫峰, 刘淑芬, 冷煌. 基于转换的攻击图分析方法研究[J]. 电子学报, 2014, 42(12): 2477-2480.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
叶子维, 郭渊博, 王宸东, 等. 攻击图技术应用研究综述[J]. 通信学报, 2017, 38(11): 121-132.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
臧艺超, 周天阳, 朱俊虎, 等. 领域独立智能规划技术及其面向自动化渗透测试的攻击路径发现研究进展[J]. 电子与信息学报, 2020, 42(9): 2095-2107.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
李庆朋, 王布宏, 王晓东, 等. 基于最优攻击路径的网络安全增强策略研究[J]. 计算机科学, 2013, 40(4): 152-154.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
杨本毅. 基于攻击图的渗透测试方法[J]. 电子科技, 2019, 32(10): 75-78.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
曾庆伟, 张国敏, 邢长友, 等. 基于分层强化学习的智能化攻击路径发现方法[J]. 计算机科学, 2023, 50(7): 308-316.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
李腾, 曹世杰, 尹思薇, 等. 应用Q学习决策的最优攻击路径生成方法[J]. 西安电子科技大学学报, 2021, 48(1): 160-167.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
胡昌振, 陈韵, 吕坤. 一种基于Q学习的最佳攻击路径规划方法: CN107317756A[P]. 2017-11-03.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
胡玮. 网络拓扑自动发现[D]. 成都: 电子科技大学, 2012.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
刘杰, 王清贤, 罗军勇. 一种基于ICMP的逻辑层网络拓扑发现与分析方法[J]. 计算机应用, 2008, 28(6): 1498-1500.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 24 |
陈晋音, 胡书隆, 邢长友, 等. 面向智能渗透攻击的欺骗防御方法[J]. 通信学报, 2022, 43(10): 106-120.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 25 |
张涛, 张文涛, 代凌, 等. 基于序贯博弈多智能体强化学习的综合模块化航空电子系统重构方法[J]. 电子学报, 2022, 50(4): 954-966.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 26 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(2505 KB)
PDF(2505 KB)
 表1 Q‐learning算法中Q‐table
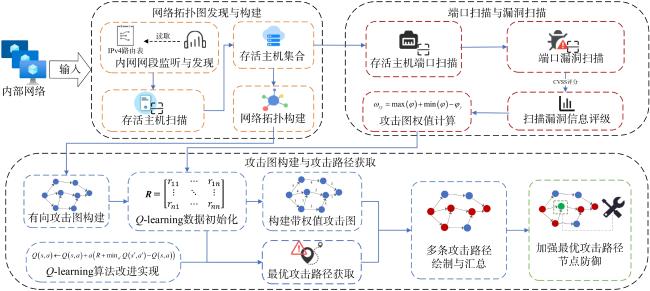
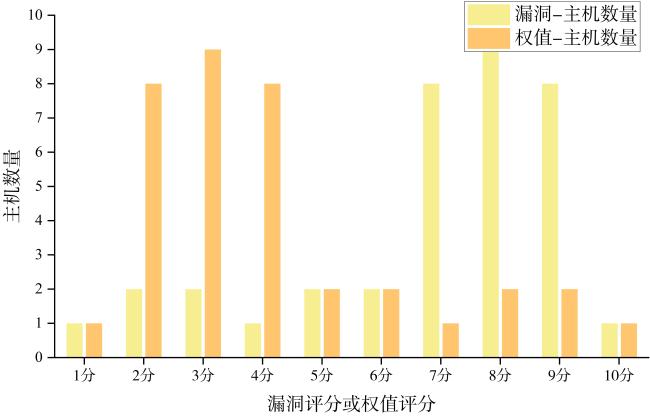
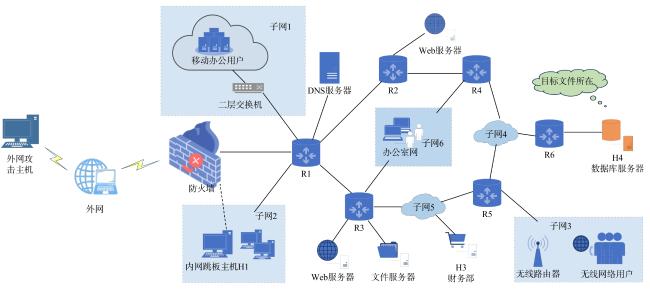
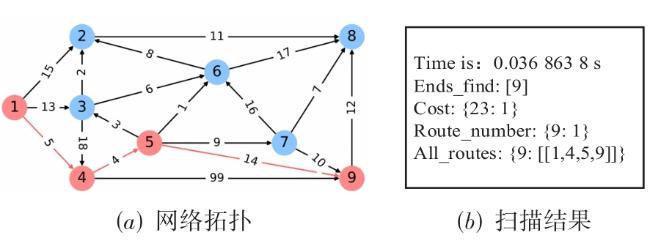
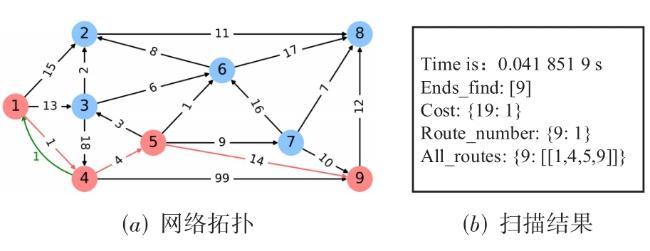
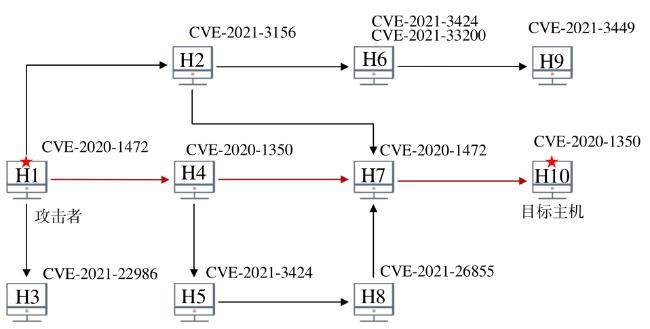
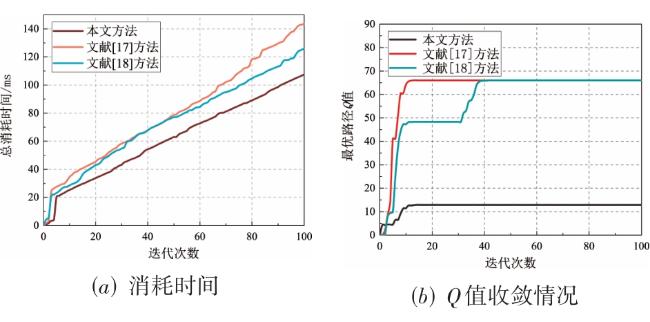
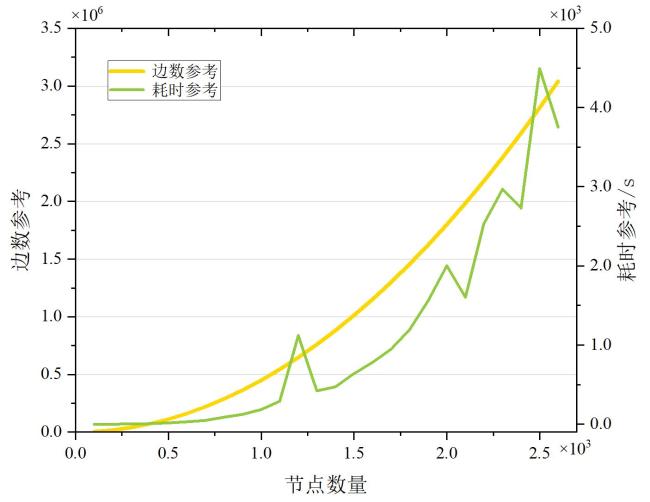
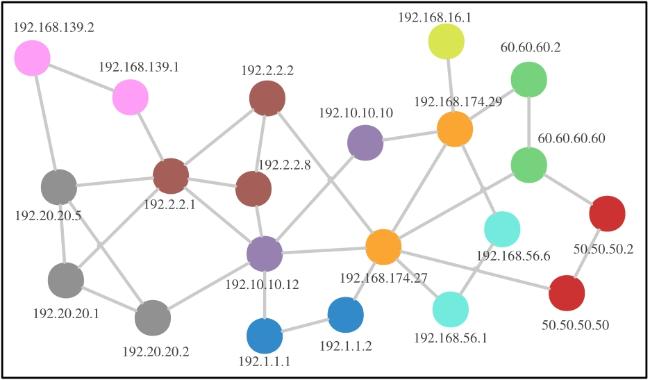
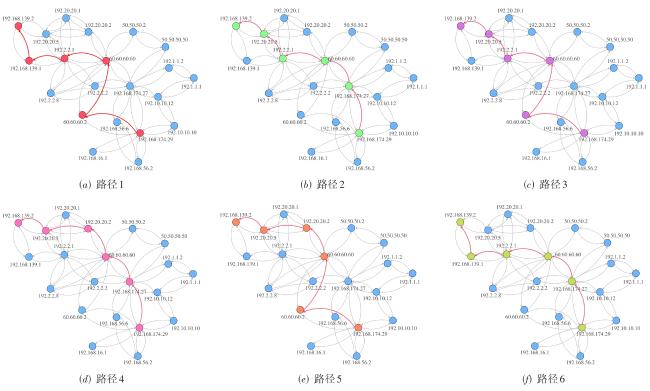
表1 Q‐learning算法中Q‐table 图1 基于强化学习的自免疫动态攻击生成方法总体设计图2 漏洞映射权值数据图3 最优攻击路径方案实验网络拓扑图4 单条最优攻击路径实验图5 多条最优攻击路径实验图6 存在环路最优攻击路径实验图7 效率对比网络拓扑图8 效率对比实验结果图9 Q-learning效率实验结果图10 网络拓扑图图11 构建攻击图结果
图1 基于强化学习的自免疫动态攻击生成方法总体设计图2 漏洞映射权值数据图3 最优攻击路径方案实验网络拓扑图4 单条最优攻击路径实验图5 多条最优攻击路径实验图6 存在环路最优攻击路径实验图7 效率对比网络拓扑图8 效率对比实验结果图9 Q-learning效率实验结果图10 网络拓扑图图11 构建攻击图结果
/
| 〈 |
|
〉 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}