 PDF(1627 KB)
PDF(1627 KB)

Algorithms and Analysis of Circle-Avoidance ROFC-LF with Unequal Error Protection for Underwater Acoustic Networks
LIU Xiu-xiu, DU Xiu-juan, HAN Duo-liang
ACTA ELECTRONICA SINICA ›› 2024, Vol. 52 ›› Issue (8) : 2591-2606.
PDF(1627 KB)
PDF(1627 KB)
Algorithms and Analysis of Circle-Avoidance ROFC-LF with Unequal Error Protection for Underwater Acoustic Networks
With the development of smart ocean, the transmission of multimedia data in underwater acoustic networks (UANs) has received much attention from scholars. The highly dynamic topology of UANs leads to incomplete data transmission between neighboring nodes, and the different portions of compressed data such as underwater images or videos have different effects on their reconstruction quality. Hence, UANs require coding mechanisms with unequal error protection (UEP) to encode and decode multimedia data. The recursive online fountain code with limited feedback (ROFC-LF) has the advantages of low overhead, less feedback and simple compiled codes, which is suitable for UANs. Combined with the characteristics of underwater acoustic channels, such as narrow bandwidth, long delay and energy limitation, this paper systematically analyzes the problem of the cycles existing in the build-up phase of ROFC-LF and proposes two optimization objectives to address the cycle problem as well as the UEP problem. In addition, a circle-avoidance ROFC-LF with UEP is presented for UANs. This coding mechanism reduces the number of useless encoded packets due to the presence of cycles in the largest component during the the build-up phase, which in turn decreases the energy consumption. To achieve the UEP property, a weighted-selection strategy is used in the build-up phase, whereas a priority strategy is employed in the completion phase. The proposed coding mechanism is analyzed based on the random graph theory, and the theoretical results are consistent with the simulation experimental results. The results show that the proposed coding mechanism can quickly recover important data while reducing the number of coded packets, and is suitable for transmitting multimedia data of varying importance in UANs with dynamically changing network topology.
underwater acoustic networks / recursive online fountain code with limited feedback / unequal error protection / circle-avoidance / weighted-selection / data priority {{custom_keyword}} /
| 算法1 避环算法 |
|---|
| 输入: 存储最大组件原始包序号数组为 输出: 最后选中的2个原始包的序号 1. 首先, 2. FOR 3. FOR 4. IF 5. 6. END IF 7. END FOR 8. END FOR 9. IF 10. goto line (1) 11. END IF |
表1 |
| | | | | |
|---|---|---|---|---|
| 0.3 | 1 036 | 16 | 1 038 | 16 |
| 0.4 | 1 040 | 15 | 1 031 | 15 |
| 0.5 | 1 054 | 14 | 1 030 | 14 |
| 0.55 | 1 062 | 13 | 1 028 | 13 |
| 0.65 | 1 087 | 11 | 1 026 | 11 |
| 算法2 不等差错保护的避环ROFC-LF编解码过程 |
|---|
| 输入: 输出: 编码包数量,反馈包数量 1. WHILE 未成功解码DO 2. 建立阶段 3. WHILE 发送方未收到含“达到最大组件”反馈DO 4. 根据 5. 执行算法1 6. 2个原始包编码,发送该编码包,记录编码包数量;重构最大连通组件;判断2个原始包序号是否属于最大组件,然后决定2个原始包的序号是否存储到 7. IF 最大组件大小 8. 接收方发送含“已达到最大组件”反馈包,反馈包数量加1 9. END IF 10. END WHILE 11. WHILE 解码的原始包数量 12. 在所有原始包中随机选择1个原始包,发送度1的编码包,记录编码包数量;接收方解码并更新已解码的原始包数量 13. END WHILE 14. 接收方向发送方发送含“原始包解码状态”和“最大组件已解码”的反馈包,反馈包数量加1 15. 完成阶段 16. 发送方根据最大组件解码成功的反馈包信息,更新未成功解码的原始包集合 17. 根据原始包划分的等级集合,不等差错保护的避环ROFC-LF编码机制将集合 18. FOR 19. IF 集合 20. 根据度1和度2编码包各自所占概率,从集合 21. IF 连续两次的解码比例差 22. 接收方发送包含“原始包解码状态”的反馈包,反馈包数量加1 23. END IF 24. END IF 25. END FOR 26.END WHILE |
表3 原始包数量为1 000时,概率 |
| | 0.008 | 0.009 | 0.01 | 0.03 | 0.05 | 0.07 | 0.08 | 0.09 | 0.1 | 0.15 | 0.2 | 0.4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| | 410 | 404 | 366 | 367 | 365 | 368 | 358 | 357 | 357 | 347 | 340 | 313 |
| | 264 | 248 | 194 | 192 | 195 | 195 | 200 | 201 | 201 | 206 | 219 | 242 |
| | 801 | 777 | 730 | 710 | 711 | 716 | 703 | 708 | 708 | 698 | 700 | 692 |
| | 1 070 | 1 063 | 1 054 | 1 048 | 1 056 | 1 050 | 1 046 | 1 049 | 1 044 | 1 050 | 1 051 | 1 043 |
表4 原始包数量为500时,概率 |
| | 0.008 | 0.009 | 0.01 | 0.02 | 0.03 | 0.05 | 0.07 | 0.08 | 0.1 |
|---|---|---|---|---|---|---|---|---|---|
| | 210 | 204 | 207 | 191 | 188 | 188 | 182 | 179 | 173 |
| | 149 | 135 | 129 | 114 | 110 | 104 | 100 | 103 | 107 |
| | 427 | 411 | 402 | 374 | 366 | 363 | 352 | 357 | 352 |
| | 567 | 567 | 547 | 546 | 549 | 547 | 541 | 541 | 543 |
表5 划分2个等级集合时, 两种编码机制对比实验 |
| 编码机制 | 编码包数量 | 反馈包数量 | 恢复MID需要的编码包数量 |
|---|---|---|---|
| UEPCAROFC-LF | 1 048 | 13 | 832 |
| UEPROFC-LF | 1 114 | 13 | 894 |
表6 不等差错保护的避环ROFC-LF和OFC-UEP对比实验 |
| 参数 | OFC-UEP 分析 | OFC-UEP 仿真 | UEPROFC 分析 | UEPCAROFC-LF仿真 |
|---|---|---|---|---|
| | 0.75 | 0.73 | 0.75 | 0.723 |
| | 0.35 | 0.37 | 0.35 | 0.377 |
| | 1.848 | 1.815 | 1.848 | 1.776 |
| | 1.231 | 1.227 | 1.231 | 1.255 |
| | 1 097上界 | 1 042 | 868 | 832 |
| | 1 256上界 | 1 226 | 1 063 | 1 048 |
表7 MID占比对编码包数量的影响 |
| MID占比 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 |
|---|---|---|---|---|---|
| | 1 095 | 1 058 | 1 054 | 1 054 | 1 048 |
| | 1 195 | 1 204 | 1 212 | 1 219 | 1 222 |
表8 划分10个等级集合时,两种编码机制对比实验 |
| 编码机制 | 编码包数量 | 反馈包数量 | 恢复MID需要的编码包数量 |
|---|---|---|---|
| UEPCAROFC-LF | 1 132 | 25 | 786 |
| UEPROFC-LF | 1 297 | 25 | 952 |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
蔡雅琼. 基于感知质量驱动的水下图像压缩与非对等保护研究[D]. 厦门: 厦门大学, 2018.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
宋鑫, 倪淑燕, 张喆, 等. 面向不等差错保护的低误码平台LT编码算法[J]. 通信学报, 2022, 43(6): 85-97.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
田远. 分布式不等差错保护喷泉码的研究与应用[D]. 广州: 华南理工大学, 2017.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
邓克岩. 基于喷泉码的不等差错保护传输方案研究[D]. 兰州: 兰州大学, 2017.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
李亚芳. LT码及其在不等差错保护方案中的研究[D]. 郑州: 郑州大学, 2017.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
黄太奇, 易本顺, 姚渭箐, 等. 基于规则变量节点度和扩展窗喷泉码的不等差错保护算法[J]. 电子与信息学报, 2015, 37(8): 1931-1936.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
石东新, 杨占昕. 不等差错保护的系统Raptor码[J]. 华中科技大学学报(自然科学版), 2016, 44(5): 47-53.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
王慧. 自适应不等差错保护喷泉编码策略研究[D]. 西安: 西安电子科技大学, 2021.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
邓在辉, 同小军, 甘良才. 改进的块复制不等差错保护喷泉码[J]. 数据采集与处理, 2015, 30(3): 591-598.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 24 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 25 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 26 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 27 |
柳秀秀, 杜秀娟, 韩多亮. 水声网络按序递归与限制反馈的在线喷泉码算法与分析[J]. 电子学报, 2023, 51(7): 1734-1740.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 28 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 29 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 30 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 31 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(1627 KB)
PDF(1627 KB)
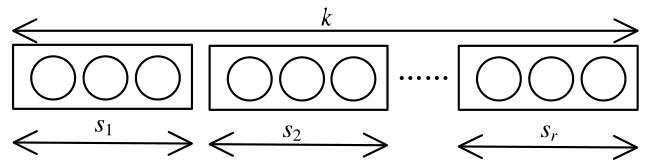
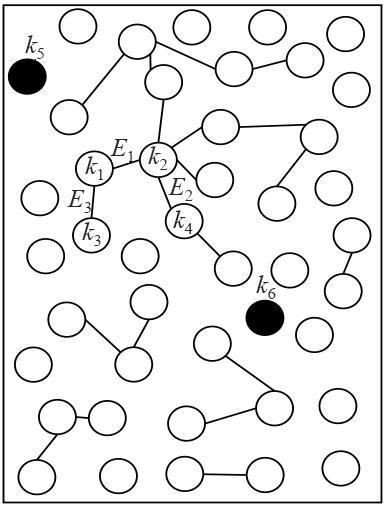
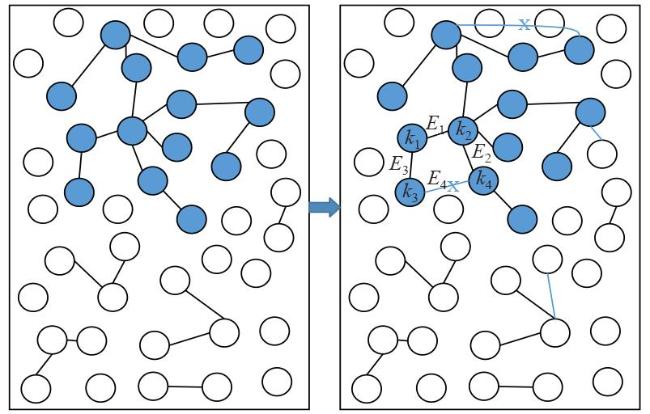
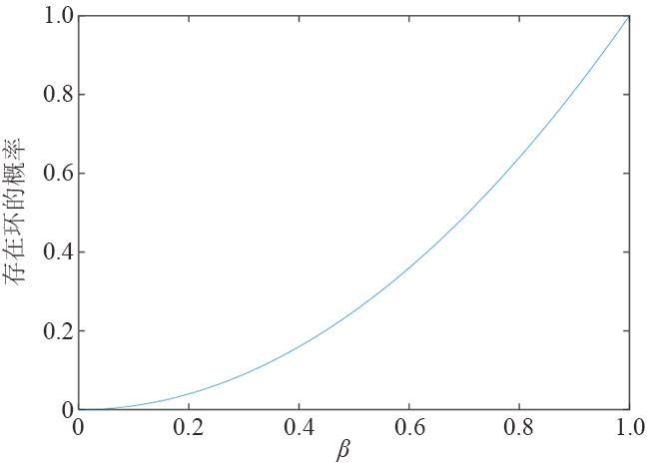
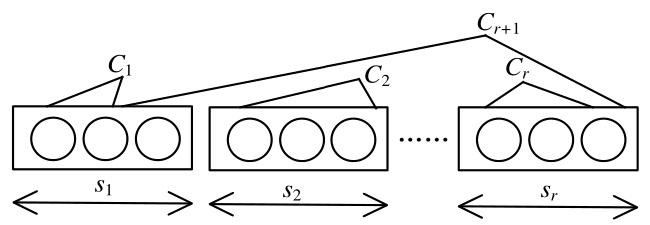
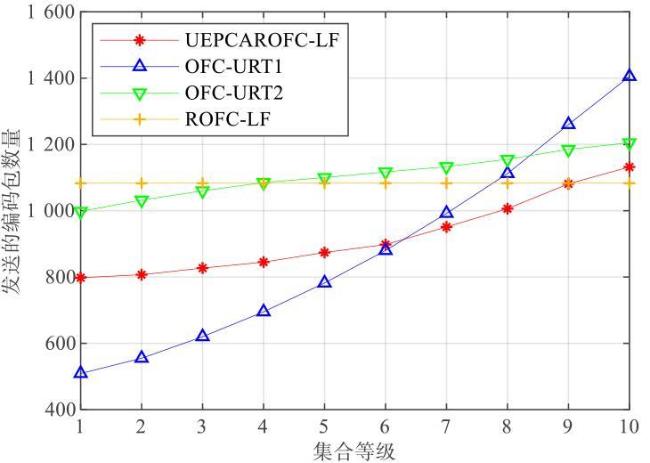
 图1 等级集合图2 解码图图3 存在环的最大组件图4 下一个编码包使得最大组件产生环的概率
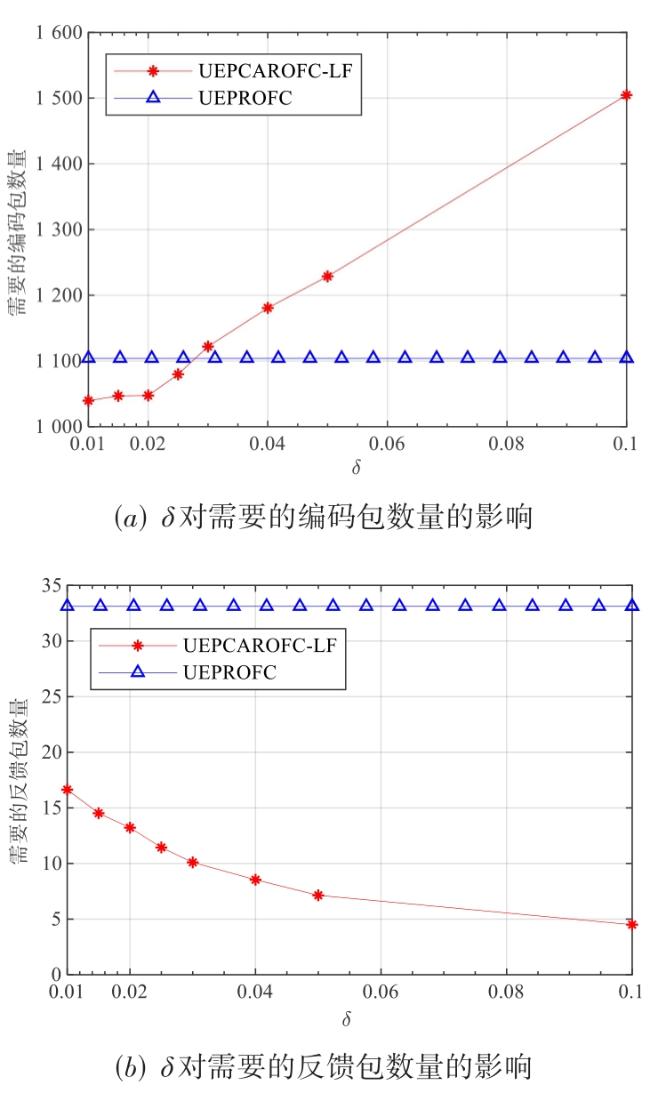
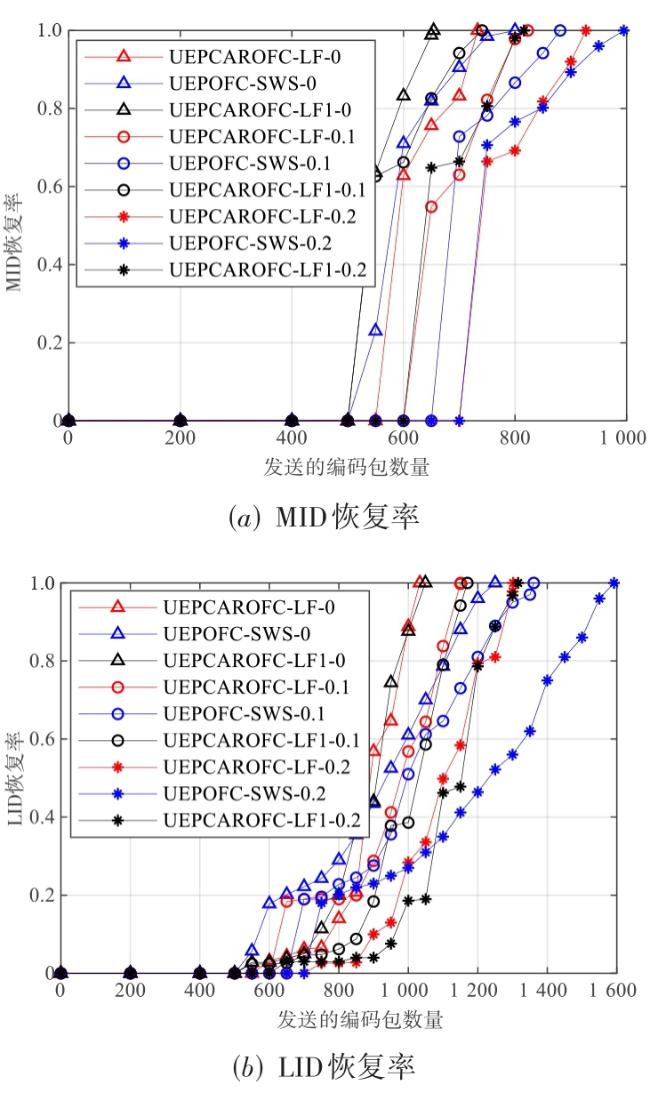
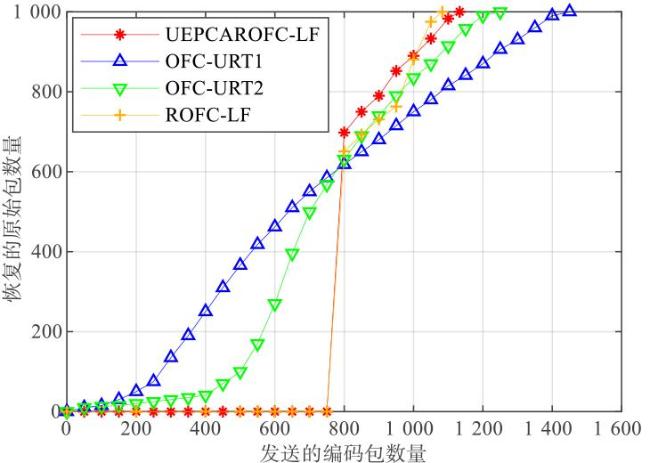
图1 等级集合图2 解码图图3 存在环的最大组件图4 下一个编码包使得最大组件产生环的概率 表1 β 0对两种编码机制的编码包和反馈包数量的影响图5 编码包集合图6 湖试的试验场景图7 δ对需要的编码包和反馈包数量的影响表3 原始包数量为1 000时,概率 q 3对编解码的影响表4 原始包数量为500时,概率 q 3对编解码的影响表5 划分2个等级集合时, 两种编码机制对比实验表6 不等差错保护的避环ROFC-LF和OFC-UEP对比实验图8 发送的编码包数量对恢复MID和LID的影响表7 MID占比对编码包数量的影响表8 划分10个等级集合时,两种编码机制对比实验图9 发送的编码包数量与恢复的原始包数量之间关系图10 等级集合恢复速度与发送的编码包数量之间关系
表1 β 0对两种编码机制的编码包和反馈包数量的影响图5 编码包集合图6 湖试的试验场景图7 δ对需要的编码包和反馈包数量的影响表3 原始包数量为1 000时,概率 q 3对编解码的影响表4 原始包数量为500时,概率 q 3对编解码的影响表5 划分2个等级集合时, 两种编码机制对比实验表6 不等差错保护的避环ROFC-LF和OFC-UEP对比实验图8 发送的编码包数量对恢复MID和LID的影响表7 MID占比对编码包数量的影响表8 划分10个等级集合时,两种编码机制对比实验图9 发送的编码包数量与恢复的原始包数量之间关系图10 等级集合恢复速度与发送的编码包数量之间关系
/
| 〈 |
|
〉 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}