 PDF(1676 KB)
PDF(1676 KB)

Boundary Feature Fusion and Foreground Guidance for Camouflaged Object Detection
LIU Wen-xi, ZHANG Jia-bang, LI Yue-zhou, LAI Yu, NIU Yu-zhen
ACTA ELECTRONICA SINICA ›› 2024, Vol. 52 ›› Issue (7) : 2279-2290.
PDF(1676 KB)
PDF(1676 KB)
Boundary Feature Fusion and Foreground Guidance for Camouflaged Object Detection
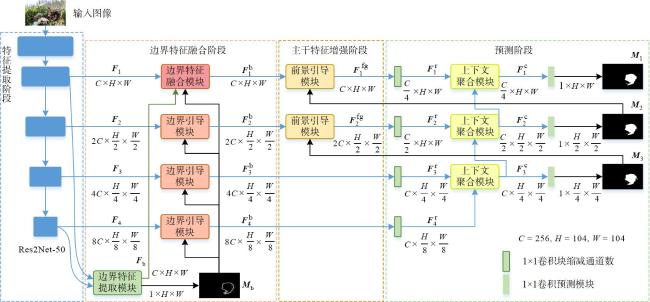
Camouflage object detection aims to detect highly concealed objects hidden in complex environments, and has important application value in many fields such as medicine and agriculture. The existing methods that combine boundary priors excessively emphasize boundary area and lack the ability to represent the internal information of camouflaged objects, resulting in inaccurate detection of the internal area of the camouflaged objects by the model. At the same time, existing methods lack effective mining of foreground features of camouflaged objects, resulting in the background area being mistakenly detected as camouflaged object. To address the above issues, this paper proposes a camouflage object detection method based on boundary feature fusion and foreground guidance, which consists of several stages such as feature extraction, boundary feature fusion, backbone feature enhancement and prediction. In the boundary feature fusion stage, the boundary features are first obtained through the boundary feature extraction module and the boundary mask is predicted. Then, the boundary feature fusion module effectively fuses the boundary features and boundary mask with the lowest level backbone features, thereby enhancing the camouflage object’s boundary position and internal region features. In addition, a foreground guidance module is designed to enhance the backbone features using the predicted camouflage object mask. The camouflage object mask predicted by the previous layer of features is used as the foreground attention of the current layer features, and performing spatial interaction on the features to enhance the network’s ability to recognize spatial relationships, thereby enabling the network to focus on fine and complete camouflage object areas. A large number of experimental results in this paper on four widely used benchmark datasets show that the proposed method outperforms the 19 mainstream methods compared, and has stronger robustness and generalization ability for camouflage object detection tasks.
camouflaged object detection / boundary prior / foreground guidance / boundary features / boundary mask / spatial interaction {{custom_keyword}} /
表1 在测试集上的结果 |
| 方法 | CHAMELEON | CAMO | COD10K | NC4K | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| | | | MAE | | | | MAE | | | | MAE | | | | MAE | |
| SINet | 0.872 | 0.936 | 0.806 | 0.034 | 0.745 | 0.804 | 0.644 | 0.092 | 0.776 | 0.864 | 0.631 | 0.043 | 0.808 | 0.871 | 0.723 | 0.058 |
| PFNet | 0.882 | 0.931 | 0.81 | 0.033 | 0.782 | 0.841 | 0.695 | 0.085 | 0.800 | 0.877 | 0.660 | 0.040 | 0.829 | 0.887 | 0.745 | 0.053 |
| MGL | 0.893 | 0.917 | 0.812 | 0.031 | 0.775 | 0.812 | 0.673 | 0.088 | 0.814 | 0.851 | 0.666 | 0.035 | 0.833 | 0.867 | 0.739 | 0.053 |
| UGTR | 0.888 | 0.910 | 0.794 | 0.031 | 0.784 | 0.822 | 0.684 | 0.086 | 0.817 | 0.852 | 0.666 | 0.036 | 0.839 | 0.874 | 0.746 | 0.052 |
| LSR | 0.890 | 0.935 | 0.822 | 0.030 | 0.787 | 0.838 | 0.696 | 0.080 | 0.804 | 0.880 | 0.673 | 0.037 | 0.840 | 0.895 | 0.766 | 0.048 |
| C2FNet | 0.888 | 0.935 | 0.828 | 0.032 | 0.796 | 0.854 | 0.719 | 0.080 | 0.813 | 0.890 | 0.686 | 0.036 | 0.838 | 0.897 | 0.762 | 0.049 |
| SINetV2 | 0.888 | 0.942 | 0.816 | 0.030 | 0.820 | 0.882 | 0.743 | 0.070 | 0.815 | 0.887 | 0.680 | 0.037 | 0.847 | 0.903 | 0.770 | 0.048 |
| ERRNet | 0.877 | 0.927 | 0.805 | 0.036 | 0.761 | 0.817 | 0.660 | 0.088 | 0.780 | 0.867 | 0.629 | 0.044 | — | — | — | — |
| CubeNet | 0.873 | 0.928 | 0.786 | 0.037 | 0.788 | 0.838 | 0.682 | 0.085 | 0.795 | 0.865 | 0.643 | 0.041 | — | — | — | — |
| BgNet | 0.894 | 0.943 | 0.823 | 0.029 | 0.831 | 0.884 | 0.762 | 0.065 | 0.826 | 0.898 | 0.703 | 0.034 | 0.855 | 0.908 | 0.784 | 0.045 |
| FAPNet | 0.893 | 0.940 | 0.825 | 0.028 | 0.815 | 0.865 | 0.734 | 0.076 | 0.822 | 0.888 | 0.694 | 0.036 | 0.851 | 0.899 | 0.775 | 0.047 |
| OCENet | 0.897 | 0.940 | 0.833 | 0.027 | 0.802 | 0.852 | 0.723 | 0.080 | 0.827 | 0.894 | 0.707 | 0.033 | 0.853 | 0.902 | 0.785 | 0.045 |
| BSANet | 0.895 | 0.946 | 0.841 | 0.027 | 0.794 | 0.851 | 0.717 | 0.079 | 0.818 | 0.891 | 0.699 | 0.034 | 0.841 | 0.897 | 0.771 | 0.048 |
| BGNet | 0.901 | 0.943 | 0.85 | 0.027 | 0.812 | 0.870 | 0.749 | 0.073 | 0.831 | 0.901 | 0.722 | 0.033 | 0.851 | 0.907 | 0.788 | 0.044 |
| Liu | 0.882 | 0.937 | 0.829 | 0.029 | 0.808 | 0.877 | 0.750 | 0.070 | 0.820 | 0.892 | 0.710 | 0.031 | 0.845 | 0.903 | 0.786 | 0.044 |
| DBFN | 0.892 | 0.944 | 0.831 | 0.03 | 0.822 | 0.878 | 0.749 | 0.069 | 0.821 | 0.893 | 0.698 | 0.034 | — | — | — | — |
| GRN | 0.862 | 0.934 | 0.816 | 0.036 | 0.766 | 0.841 | 0.737 | 0.09 | 0.798 | 0.873 | 0.691 | 0.039 | — | — | — | — |
| ZoomNet | 0.902 | 0.943 | 0.845 | 0.023 | 0.820 | 0.877 | 0.752 | 0.066 | 0.838 | 0.888 | 0.729 | 0.029 | 0.853 | 0.896 | 0.784 | 0.043 |
| SegMaR | 0.906 | 0.951 | 0.860 | 0.025 | 0.815 | 0.874 | 0.753 | 0.071 | 0.833 | 0.899 | 0.724 | 0.034 | 0.841 | 0.896 | 0.781 | 0.046 |
| 本文方法 | 0.907 | 0.949 | 0.861 | 0.024 | 0.835 | 0.886 | 0.775 | 0.065 | 0.842 | 0.905 | 0.739 | 0.029 | 0.862 | 0.911 | 0.801 | 0.041 |
表2 消融实验结果 |
| 方法 | CAMO | NC4K | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 实验 | 边界特征提取模块 | 边界引导 模块 | 边界特征融合模块 | 前景引导 模块 | | | | MAE | | | | MAE |
| (1) | × | × | × | × | 0.816 | 0.866 | 0.743 | 0.074 | 0.857 | 0.904 | 0.788 | 0.044 |
| (2) | √ | × | 不使用边界掩码 | × | 0.822 | 0.873 | 0.752 | 0.068 | 0.858 | 0.906 | 0.792 | 0.043 |
| (3) | √ | √ | 替换为边界引导模块 | × | 0.823 | 0.876 | 0.760 | 0.070 | 0.859 | 0.908 | 0.794 | 0.042 |
| (4) | √ | √ | √ | × | 0.827 | 0.880 | 0.761 | 0.070 | 0.860 | 0.910 | 0.796 | 0.043 |
| (5) | √ | √ | 替换为边界引导模块 | √ | 0.828 | 0.882 | 0.766 | 0.068 | 0.860 | 0.909 | 0.796 | 0.042 |
| (6) | 替换文献[9]的模块 | √ | 替换为边界引导模块 | √ | 0.821 | 0.872 | 0.751 | 0.072 | 0.859 | 0.906 | 0.794 | 0.043 |
| (7) | 替换文献[10]的模块 | √ | 替换为边界引导模块 | √ | 0.821 | 0.868 | 0.753 | 0.071 | 0.859 | 0.907 | 0.794 | 0.043 |
| (8) | √ | √ | √ | √ | 0.835 | 0.886 | 0.775 | 0.065 | 0.862 | 0.911 | 0.801 | 0.041 |
表3 3个层次特征预测掩码指标 |
| 不同层次特征预测掩码 | CAMO | NC4K | ||||||
|---|---|---|---|---|---|---|---|---|
| | | | MAE | | | | MAE | |
| 深层特征预测掩码 | 0.827 | 0.879 | 0.751 | 0.070 | 0.848 | 0.901 | 0.766 | 0.048 |
| 较深层特征预测掩码 | 0.834 | 0.885 | 0.77 | 0.066 | 0.859 | 0.908 | 0.792 | 0.043 |
| 浅层特征预测掩码(本文方法) | 0.835 | 0.886 | 0.775 | 0.065 | 0.862 | 0.911 | 0.801 | 0.041 |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
刘金平, 吴娟娟, 张荣, 等. 基于结构重参数化与多尺度深度监督的COVID-19胸部CT图像自动分割[J]. 电子学报, 2023, 51(5): 1163-1171.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
李维刚, 叶欣, 赵云涛, 等. 基于改进YOLOv3算法的带钢表面缺陷检测[J]. 电子学报, 2020, 48(7): 1284-1292.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
师奕兵, 罗清旺, 王志刚, 等. 基于多元接收线圈的管道局部缺陷检测方法研究[J]. 电子学报, 2018, 46(1): 197-202.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
陶显, 侯伟, 徐德. 基于深度学习的表面缺陷检测方法综述[J]. 自动化学报, 2021, 47(5): 1017-1034.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
罗会兰, 袁璞, 童康. 基于深度学习的显著性目标检测方法综述[J]. 电子学报, 2021, 49(7): 1417-1427.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
陈星宇, 叶锋, 黄添强, 等. 融合小型深度生成模型的显著性检测[J]. 电子学报, 2021, 49(4): 768-774.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
王正文, 宋慧慧, 樊佳庆, 等. 基于语义引导特征聚合的显著性目标检测网络[J]. 自动化学报, 2023, 49(11): 2386-2395.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
刘研, 张开华, 樊佳庆, 等. 渐进聚合多尺度场景上下文特征的伪装物体检测[J]. 计算机学报, 2022, 45(12): 2637-2651.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 24 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 25 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 26 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 27 |
郑云飞, 王晓兵, 张雄伟, 等. 基于金字塔知识的自蒸馏HRNet目标分割方法[J]. 电子学报, 2023, 51(3): 746-756.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 28 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 29 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 30 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 31 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 32 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 33 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 34 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 35 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 36 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 37 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 38 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 39 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 40 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 41 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(1676 KB)
PDF(1676 KB)
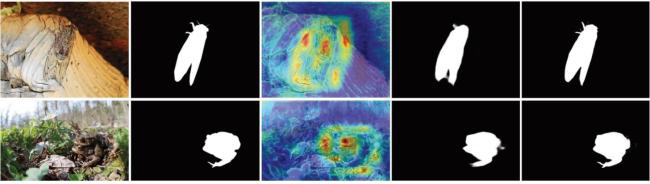
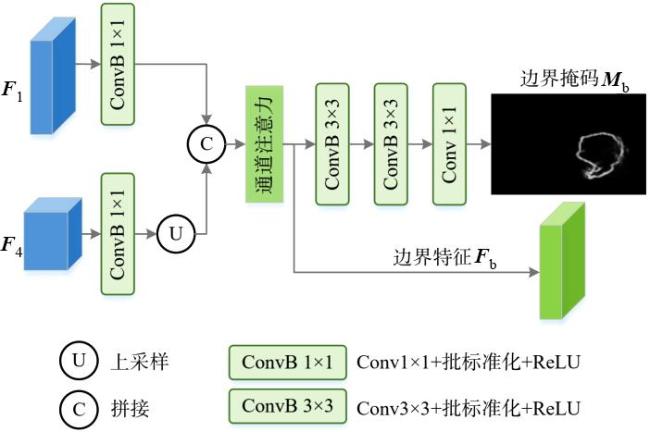
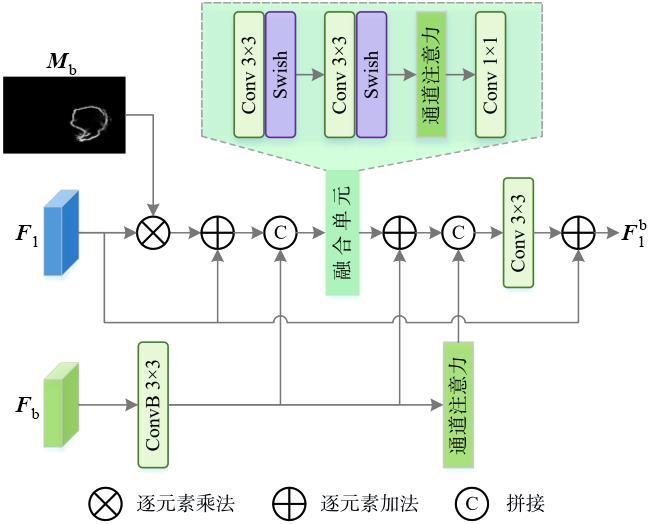
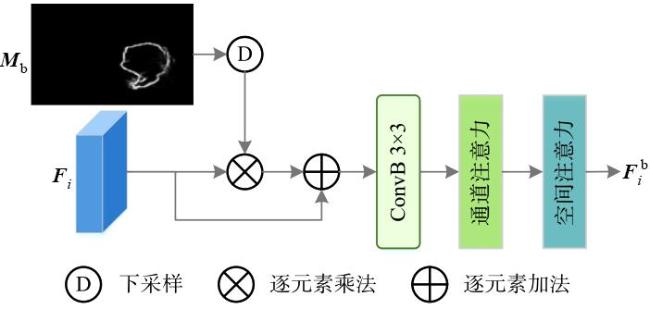
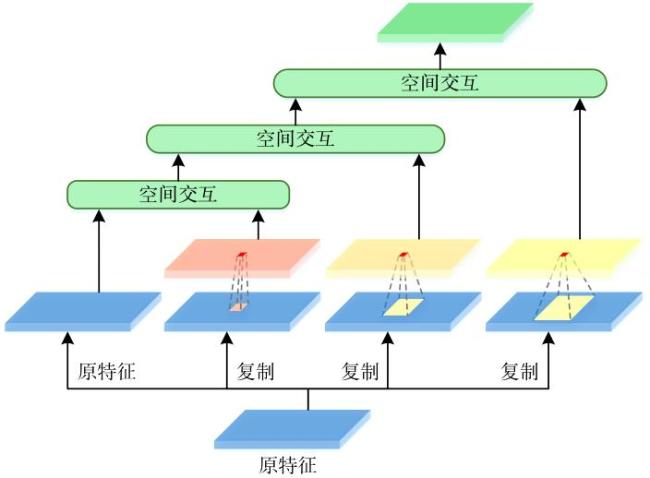
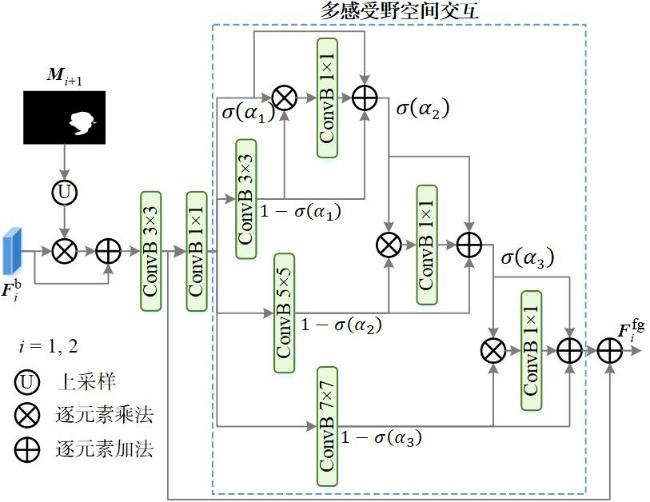
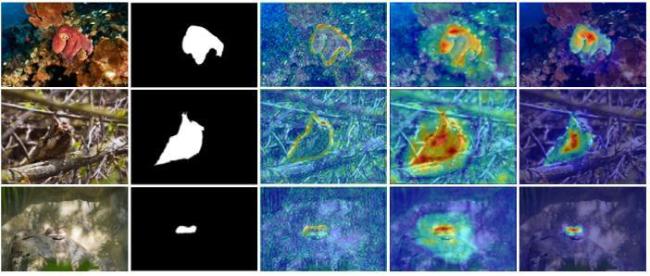
 图1 边界特征热力图和网络深层特征预测的伪装目标掩码示例图图2 基于边界特征融合和前景引导的伪装目标检测网络整体结构图图3 边界特征提取模块结构图图4 边界特征融合模块结构图图5 边界引导模块结构图图6 多感受野空间交互原理图图7 前景引导模块结构图
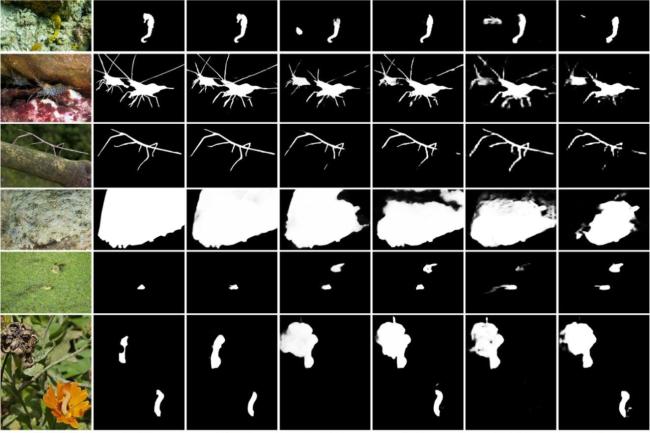
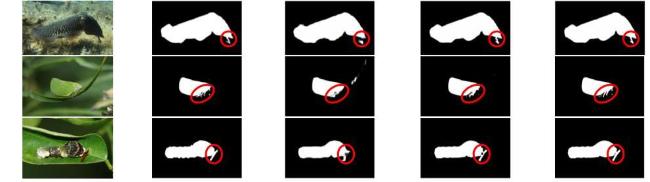
图1 边界特征热力图和网络深层特征预测的伪装目标掩码示例图图2 基于边界特征融合和前景引导的伪装目标检测网络整体结构图图3 边界特征提取模块结构图图4 边界特征融合模块结构图图5 边界引导模块结构图图6 多感受野空间交互原理图图7 前景引导模块结构图 表1 在测试集上的结果图8 不同方法的视觉效果对比表2 消融实验结果图9 本文方法的热力图视觉效果对比表3 3个层次特征预测掩码指标图10 3个层次特征预测的伪装目标掩码示例图
表1 在测试集上的结果图8 不同方法的视觉效果对比表2 消融实验结果图9 本文方法的热力图视觉效果对比表3 3个层次特征预测掩码指标图10 3个层次特征预测的伪装目标掩码示例图
/
| 〈 |
|
〉 |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}