 PDF(2130 KB)
PDF(2130 KB)

Optimization Study of the Load Balancing Algorithm in the Multi-Layer Lattice Boltzmann Method
HE Peng, WANG Liang-jun, ZHANG Wu, ZHU Wen-hao
ACTA ELECTRONICA SINICA ›› 2024, Vol. 52 ›› Issue (9) : 3097-3110.
PDF(2130 KB)
PDF(2130 KB)
Optimization Study of the Load Balancing Algorithm in the Multi-Layer Lattice Boltzmann Method
The local encryption technique for multi-layer grids based on the lattice Boltzmann method computes the flow characteristics at different levels through multi-layer grids, which avoids the inefficiency and waste of computational resources in single-layer uniform Cartesian grids. But there is still an undesirable effect on the parallel performance. The load-balancing effect in parallel computing is considered in this paper. Starting from a single-layer grid, we study the load-balancing-based grid partitioning method by considering the computational characteristics of multi-layer grids. At the same time, the grid partitioning is separated from the program implementation, and parallel computation with arbitrary grid partitioning is achieved in both single-layer and multi-layer grids. The relationship between load partitioning and the respective time overheads of the different processes is investigated in a single-layer grid with different parallel strategies for 2D vascular flow. The characteristics of multiscale grids with respect to the order of operations is first discussed for multi-layer grids. Second, three different multi-layer grids are used to verify the computational results of the two-dimensional aerofoils. Finally, the relationship between load balancing and time overhead is further investigated by using three different meshing methods in each grid. Parallel performance tests on a 128-core HPC (High Performance Computing) platform show that the strong scalability can reach up to 60%, and the weak scalability can reach 82.78%. This high scalability result shows the significant improvement of the parallel performance in multi-layer grid computing by improving the load balancing performance.
lattice Boltzmann method / multilayer grids / massive parallel computing / load balancing {{custom_keyword}} /
| 算法1 LBM的计算框架 |
|---|
| 输入:初始流场状态(密度、速度和雷诺数等等); 输出:最终的流场计算结果; 1:初始化; 2:网格生成; 3:碰撞; 4:迁移; 5:计算计算域内的固体边界条件; 6:计算宏观量; 7:计算整体计算域的外边界条件 8:判断是否达到计算条件,如果没有,则返还到步骤3; 9:输出结果并保存文件. |
| 算法2 任意层数下的多层网格LBM的计算框架 |
|---|
| 输入:初始流场状态(密度、速度和雷诺数等)与计算网格(网格层数N,每层网格用k表示); 输出:最终的流场计算结果; 1:初始化,每层网格的常数mark设为0; 2: 3: 4:对第 5:对第 6: 7:判断第l层的mark是否等于2,如果否,则直接跳至步骤10; 8:对第l层网格进行LBM运算,对应的mark加1; 9:交换第l层和第 10: 11: 12:计算第0层网格中的外边界条件; 13: 14:输出计算结果. |
| 算法3 基于负载均衡的单层网格中的网格划分方法 |
|---|
| 输入:计算网格(已完成网格生成步骤,即已确定网格点类型和相对距离); 输出:考虑负载均衡的网格划分结果(在原计算网格上新增一个标记常数,表示该点在并行计算中的进程编号); 1:对网格数为 2:如果整体任务划分给 3:对于常数m和0号进程,令 4:重复步骤3,直到已得到 5:根据mark即可确定全部网格点的进程编号; 6:输出结果并保存文件. |
| 算法4 任意网格划分下的多层网格LBM并行算法 |
|---|
| 输入:初始流场状态(密度、速度和雷诺数等等)、计算网格(网格层数N,每层网格用k表示)和数据传输通道(接收和发送的网格点数量以及坐标); 输出:最终的流场计算结果; 1:根据MPI进程总数 2:根据每一层的网格点坐标,构建不同层网格点的重合关系,即构建粗细网格交换的“缓冲区”; 3:每个MPI进程负责自己的网格区域,参考算法2进行LBM运算; 4:每完成相邻两层的运算后,先基于数据传输通道完成不同进程之间的数据通信过程; 5:进行粗细网格的数据交换; 6:计算第0层网格的外边界条件; 7:判断是否达到计算条件,如果没有,则返还到步骤3; 8:输出结果并保存文件. |
表1 不同分区策略下的相关参数与测试结果 |
| 自定义划分 | 均匀划分 | 复杂的自定义划分 | |
|---|---|---|---|
| 负载(最小/最大)(5进程) | 31 684 /32 079 | 32 000 /32 000 | 32 000 /32 000 |
| 时间开销 (5进程) | 25.41 s | 25.61 s | 29.84 s |
| 最大通信量 (5进程) | 716 | 800 | 64 000 |
| 负载(最小/最大)(50进程) | — | 3 200 /3 200 | 3 200 /3 200 |
| 时间开销 (50进程) | — | 3.13 s | 3.52 s |
| 最大通信量 (50进程) | — | 800 | 6 400 |
| 负载(最小/最大)(100进程) | — | 1 600 /1 600 | 1 600 /1 600 |
| 时间开销 (100进程) | — | 2.24 s | 2.39 s |
| 最大通信量 (100进程) | — | 800 | 3 200 |
表2 不同网格参数下的网格量与时间开销 |
| 网格层数量 | 网格点数量/万 | 时间开销/s | |
|---|---|---|---|
| 二层网格 | 0号层 | 15.1 | 972 |
| 1号层 | 68.8 | ||
| 合计 | 83.9 | ||
| 三层网格 | 0号层 | 15.1 | 3 816 |
| 1号层 | 47.5 | ||
| 2号层 | 134.4 | ||
| 合计 | 195 | ||
| 四层网格 | 0号层 | 15.1 | 17 352 |
| 1号层 | 32.4 | ||
| 2号层 | 69.9 | ||
| 3号层 | 311 | ||
| 合计 | 428 | ||
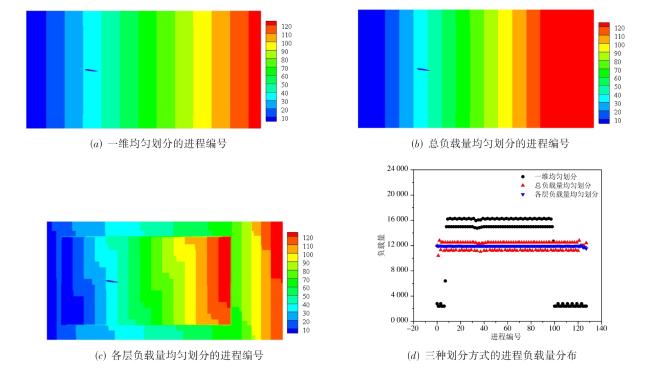
表3 不同划分方式下不同网格参数下的负载量和时间开销 |
| 网格划分方式 | 负载量(最小/最大) | 时间开销(总)/s | 时间开销(运算)/s | 等待时间(占比)/% |
|---|---|---|---|---|
| 一维均匀划分(二层) | 2 400/16 302 | 182.52 | 158.95 | 12.9 |
| 总负载量均匀划分(二层) | 10 396/12 796 | 128.37 | 112.82 | 12.1 |
| 各层负载量均匀划分(二层) | 11 537/11 977 | 108.23 | 103.61 | 4.3 |
| 一维均匀划分(三层) | 2 400/95 266 | 774.83 | 649.13 | 16.2 |
| 总负载量均匀划分(三层) | 48 848/55 372 | 1 064.35 | 552.81 | 48.1 |
| 各层负载量均匀划分(三层) | 50 751/52 385 | 407.68 | 380.94 | 6.6 |
| 一维均匀划分(四层) | 2 400/568 680 | 3 895.86 | 3 409.93 | 12.5 |
| 总负载量均匀划分(四层) | 215 288/230 416 | 4 168.66 | 2 199.20 | 47.2 |
| 各层负载量均匀划分(四层) | 219 243/223 057 | 1 692.02 | 1 623.88 | 4.1 |
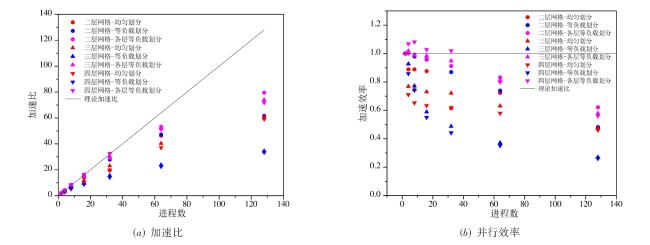
表4 并行性能测试过程中的详细时间开销 (s) |
| 进程数 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
|---|---|---|---|---|---|---|---|
| 均匀划分(二层) | 230.26 | 129.50 | 64.77 | 32.85 | 23.40 | 9.94 | 7.45 |
| 等负载划分(二层) | 196.43 | 98.19 | 50.17 | 25.63 | 14.12 | 8.31 | 6.43 |
| 各层等负载划分(二层) | 201.54 | 100.57 | 50.85 | 26.17 | 13.81 | 7.57 | 5.07 |
| 均匀划分(三层) | 1 018.59 | 663.14 | 340.46 | 174.40 | 88.32 | 50.48 | 33.90 |
| 等负载划分(三层) | 743.71 | 401.07 | 240.98 | 157.97 | 95.43 | 62.64 | 43.13 |
| 各层等负载划分(三层) | 6 94.32 | 340.86 | 175.28 | 88.23 | 45.76 | 26.73 | 18.77 |
| 均匀划分(四层) | 5 300.50 | 3 729.02 | 2 027.44 | 1 044.36 | 533.93 | 285.77 | 179.46 |
| 等负载划分(四层) | 3 041.86 | 1 771.83 | 1 025.21 | 690.95 | 429.81 | 270.02 | 181.78 |
| 各层等负载划分(四层) | 3 072.28 | 1 537.05 | 769.96 | 393.60 | 198.11 | 120.19 | 85.48 |
表5 最佳网格划分策略下的弱可扩展性 |
| 进程 数量 | 0层 负载量 | 1层 负载量 | 2层 负载量 | 时间 开销/s | 弱可扩 展性 |
|---|---|---|---|---|---|
| 2 | 3 324 | 8 320 | 24 236 | 15.96 | 100% |
| 8 | 12 896 | 31 304 | 86 683 | 16.3 | 97.91% |
| 32 | 50 796 | 122 604 | 332 877 | 16.11 | 99.07% |
| 128 | 201 596 | 485 204 | 1 304 062 | 19.28 | 82.78% |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
张凌明, 赵悦, 李鹏程, 等. 基于局部注意力机制的三维牙齿模型分割网络[J]. 电子学报, 2022, 50(3): 681-690.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
王相海, 宋若曦, 曲思洁, 等. 图像多尺度几何分析域隐马尔可夫树模型研究进展[J]. 电子学报, 2022, 50(1): 238-249.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
袁海英, 曾智勇, 成君鹏. 面向灵活并行度的稀疏卷积神经网络加速器[J]. 电子学报, 2022, 50(8): 1811-1818.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(2130 KB)
PDF(2130 KB)

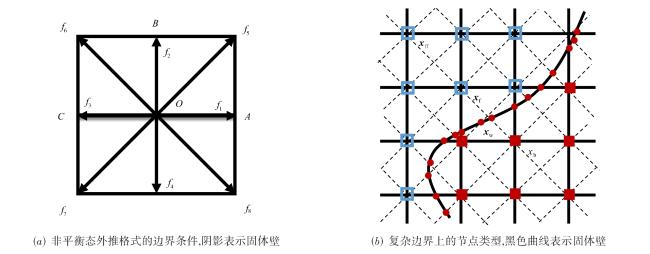
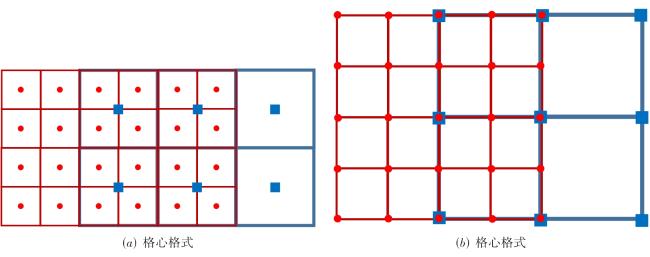
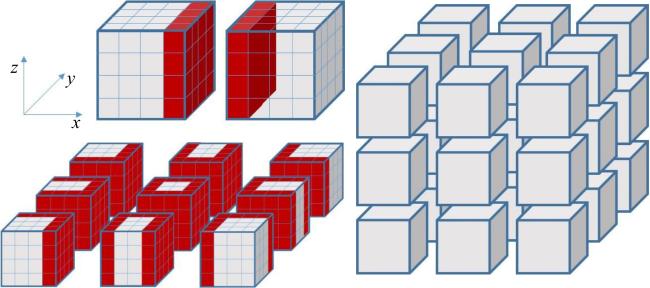
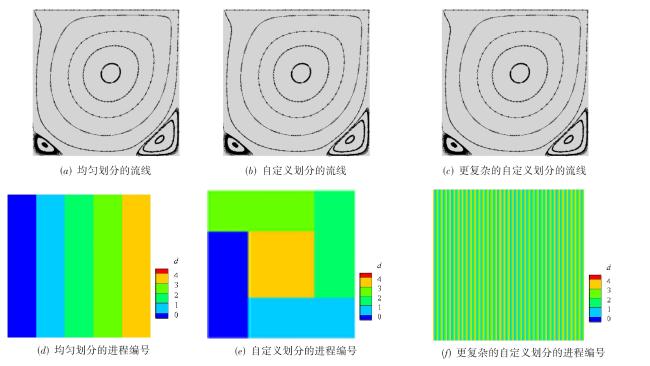
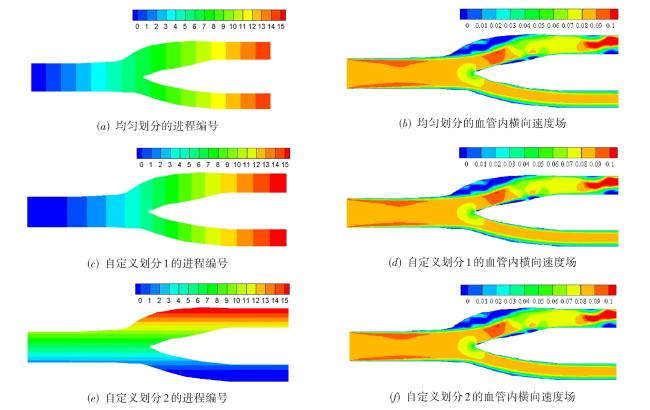
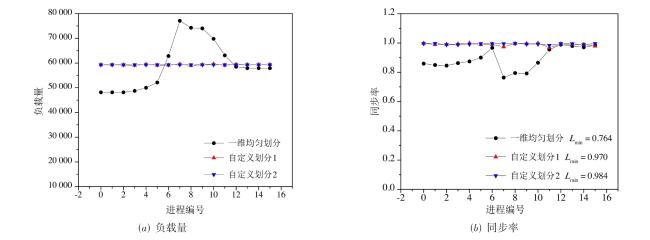
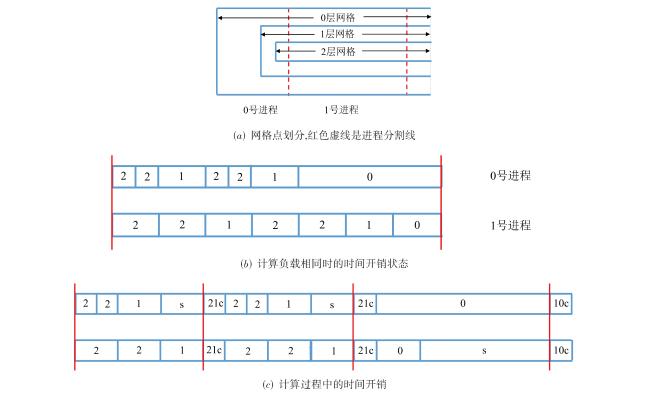
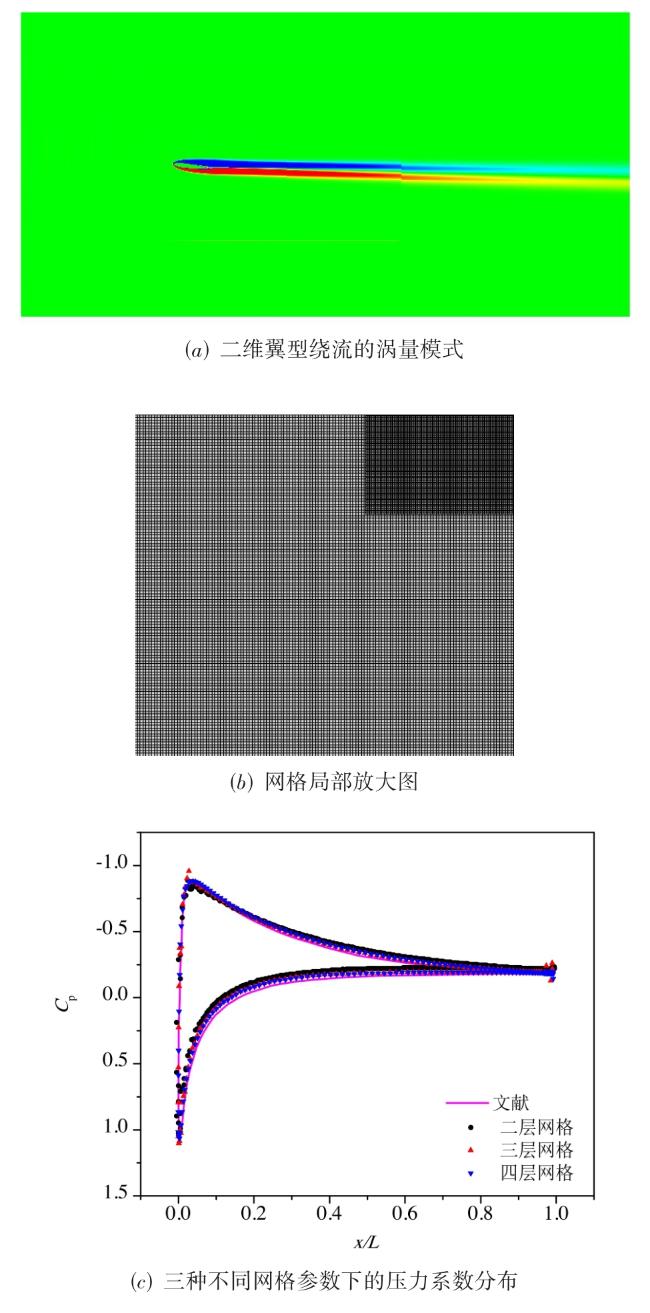
 图1 二维的问题中的平直边界处理与曲边界处理图2 不同格式的多层网格结构图3 多层网格的构建方法图4 常规的1D,2D和3D网格划分方法图5 三种分区策略下的顶盖驱动流计算,黑色曲线表示流线,不同颜色代表不同的进程编号值表1 不同分区策略下的相关参数与测试结果图6 不同网格点划分方式下的血管流计算结果图7 血管流中不同网格点划分状态下的负载量和同步率图8 两层网格中的网格点划分与时间开销(数字表示网格点层级数,c表示不同层级间的数据交换,红色实线表示进程间的通信过程)图9 三层网格的网格点划分、计算负载相同时的时间开销状态与计算过程中的时间开销(数字表示网格点层级数,红色实线表示进程间的通信过程, c表示不同层级间的数据交换,c前数字表示参与交换的层级,s表示等待时间)图10 四层网格下的翼型绕流的涡量模式、网格局部放大图与三种不同网格参数下的压力系数分布表2 不同网格参数下的网格量与时间开销图11 二层网格下的不同划分方式与不同进程的负载量分布表3 不同划分方式下不同网格参数下的负载量和时间开销图12 不同网格结构下的不同划分方式的加速比和并行效率表4 并行性能测试过程中的详细时间开销 (s)表5 最佳网格划分策略下的弱可扩展性
图1 二维的问题中的平直边界处理与曲边界处理图2 不同格式的多层网格结构图3 多层网格的构建方法图4 常规的1D,2D和3D网格划分方法图5 三种分区策略下的顶盖驱动流计算,黑色曲线表示流线,不同颜色代表不同的进程编号值表1 不同分区策略下的相关参数与测试结果图6 不同网格点划分方式下的血管流计算结果图7 血管流中不同网格点划分状态下的负载量和同步率图8 两层网格中的网格点划分与时间开销(数字表示网格点层级数,c表示不同层级间的数据交换,红色实线表示进程间的通信过程)图9 三层网格的网格点划分、计算负载相同时的时间开销状态与计算过程中的时间开销(数字表示网格点层级数,红色实线表示进程间的通信过程, c表示不同层级间的数据交换,c前数字表示参与交换的层级,s表示等待时间)图10 四层网格下的翼型绕流的涡量模式、网格局部放大图与三种不同网格参数下的压力系数分布表2 不同网格参数下的网格量与时间开销图11 二层网格下的不同划分方式与不同进程的负载量分布表3 不同划分方式下不同网格参数下的负载量和时间开销图12 不同网格结构下的不同划分方式的加速比和并行效率表4 并行性能测试过程中的详细时间开销 (s)表5 最佳网格划分策略下的弱可扩展性
/
| 〈 |
|
〉 |







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}