 PDF(4602 KB)
PDF(4602 KB)

Cross-Layer Attention Feature Interaction and Multi-Scale Channel Attention Network for Single Image Dehazing
SUN Hang, FU Qiu-yue, LI Bo-hui, DAN Zhi-ping, YU Mei, WAN Jun
ACTA ELECTRONICA SINICA ›› 2024, Vol. 52 ›› Issue (11) : 3711-3726.
PDF(4602 KB)
PDF(4602 KB)
Cross-Layer Attention Feature Interaction and Multi-Scale Channel Attention Network for Single Image Dehazing
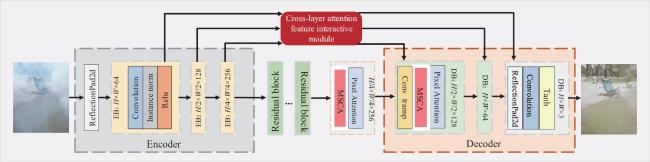
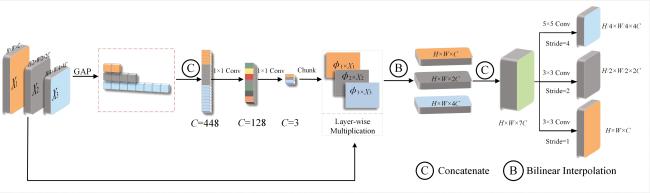
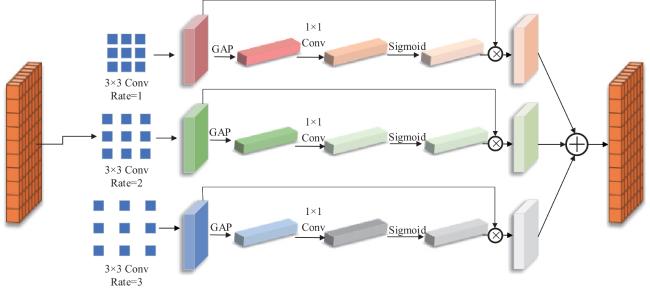
In recent years, U-shaped convolutional neural networks (CNNs) have achieved remarkable progress in image dehazing. However, most U-shaped dehazing networks directly pass encoder features to the decoder at the corresponding scale, ignoring effective utilization of multi-scale features. In addition, channel attention widely used in dehazing networks is restricted by receptive fields, failing to sufficiently leverage contextual information, which adversely affects learning of channel weights. To address the above issues, this paper proposes a novel dehazing algorithm with cross-layer attentive feature interaction and multi-scale channel attention. Specifically, the cross-layer attentive feature interaction module learns hierarchical weights for multi-scale encoder features, and aggregates these cross-layer features for transfer to the decoder, thereby reducing feature dilution during the dehazing network's reconstruction of clear images. Moreover, to uncover channel information that is critical for dehazing networks, we devise a multi-scale channel attention mechanism that extracts multi-scale features by dilated convolutions with different dilation rates, forming a parallel learning scheme of channel attention with multi-scale contexts for more effective weight allocation for dehazing network features. Experimental results demonstrate that the proposed dehazing algorithm achieves better objective metrics and visual performance compared to 12 existing methods on 4 public datasets. The code for this paper has been uploaded tohttp://github.com/bohuisir/AAFMAF.
image dehazing / cross-layer attention feature interaction / feature dilution / multi-scale channel attention / dilated convolution {{custom_keyword}} /
表1 在自然场景数据集上PSNR和SSIM的对比 |
| Method | SOTS-Outdoor | Dense-Haze | NH-Haze | |||
|---|---|---|---|---|---|---|
| PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | |
| (TPAMI 10) DCP | 15.55 | 0.815 | 10.85 | 0.404 | 11.30 | 0.605 |
| (ICCV 17) AOD-Net | 19.63 | 0.861 | 13.30 | 0.469 | 13.22 | 0.613 |
| (CVPR 19) EPDN | 22.57 | 0.863 | 16.24 | 0.536 | 18.35 | 0.784 |
| (WACV19)GCANet | 21.71 | 0.891 | 13.16 | 0.483 | 14.84 | 0.446 |
| (CVPR 20)MSBDN | 32.16 | 0.976 | 14.84 | 0.494 | 19.63 | 0.804 |
| (AAAI 20) FFA | 33.57 | 0.984 | 16.26 | 0.545 | 20.40 | 0.806 |
| (CVPR 21) AECR-Net | 30.90 | 0.968 | 15.10 | 0.451 | 18.64 | 0.750 |
| (CVPRW 21) TBN | 30.56 | 0.967 | 16.36 | 0.582 | 21.66 | 0.843 |
| (Tip 22)SGID | 30.20 | 0.975 | 13.09 | 0.519 | 16.42 | 0.682 |
| (TCSVT 22)TMS-GAN | 32.58 | 0.964 | 16.15 | 0.526 | 20.94 | 0.811 |
| (CVPRW 23) ITB | 32.66 | 0.970 | 16.31 | 0.561 | 21.67 | 0.838 |
| Ours | 33.70 | 0.977 | 17.42 | 0.603 | 22.78 | 0.845 |
表2 在自然场景数据集上UIQI和RMSE的对比 |
| Method | SOTS-Outdoor | Dense-Haze | NH-Haze | |||
|---|---|---|---|---|---|---|
| UIQI | RMSE | UIQI | RMSE | UIQI | RMSE | |
| (TPAMI 10) DCP | 0.844 | 9.66 | 0.234 | 10.34 | 0.354 | 10.23 |
| (ICCV 17) AOD-Net | 0.951 | 9.34 | 0.317 | 10.25 | 0.531 | 10.01 |
| (CVPR 19) EPDN | 0.946 | 9.76 | 0.678 | 10.09 | 0.705 | 9.91 |
| (WACV19)GCANet | 0.798 | 8.34 | 0.497 | 10.35 | 0.530 | 10.20 |
| (CVPR 20)MSBDN | 0.980 | 4.99 | 0.537 | 10.13 | 0.906 | 9.57 |
| (AAAI 20) FFA | 0.989 | 5.01 | 0.669 | 10.01 | 0.898 | 9.59 |
| (CVPR 21) AECR-Net | 0.900 | 6.29 | 0.443 | 10.11 | 0.840 | 10.01 |
| (CVPRW 21) TBN | 0.901 | 6.09 | 0.688 | 9.94 | 0.935 | 9.21 |
| (Tip 22)SGID | 0.899 | 6.23 | 0.467 | 10.15 | 0.820 | 9.57 |
| (TCSVT 22)TMS-GAN | 0.974 | 5.88 | 0.679 | 10.11 | 0.924 | 9.47 |
| (CVPRW 23) ITB | 0.991 | 5.13 | 0.683 | 9.90 | 0.932 | 9.33 |
| Ours | 0.996 | 4.97 | 0.727 | 9.85 | 0.937 | 8.82 |
表3 在StateHaze⁃1k遥感数据集不同雾浓度数据集上PSNR和SSIM的对比 |
| Method | Thin fog | Moderate fog | Thick fog | |||
|---|---|---|---|---|---|---|
| PSNR/dB | SSIM | PSNR/dB | SSIM | PSNR/dB | SSIM | |
| (TPAMI 10) DCP | 13.45 | 0.701 | 9.78 | 0.591 | 10.89 | 0.572 |
| (ICCV 17) AOD-Net | 18.62 | 0.851 | 17.91 | 0.882 | 15.21 | 0.739 |
| (CVPR 19) EPDN | 21.74 | 0.882 | 24.05 | 0.910 | 19.73 | 0.786 |
| (WACV19)GCANet | 18.71 | 0.791 | 20.58 | 0.799 | 17.73 | 0.724 |
| (CVPR 20) MSBDN | 20.09 | 0.832 | 22.94 | 0.873 | 18.67 | 0.733 |
| (AAAI 20) FFA | 23.75 | 0.903 | 26.50 | 0.941 | 22.03 | 0.840 |
| (CVPR 21) AECR-Net | 22.90 | 0.879 | 24.03 | 0.879 | 20.61 | 0.812 |
| (CVPR 21)TBN | 24.52 | 0.897 | 27.42 | 0.944 | 21.56 | 0.837 |
| (Tip 22) SGID | 23.34 | 0.907 | 23.95 | 0.935 | 19.20 | 0.823 |
| Huang.w/o SAR | 21.74 | 0.816 | 22.09 | 0.827 | 22.12 | 0.784 |
| (WACV 20)Huang.SAR | 24.16 | 0.906 | 25.31 | 0.926 | 25.07 | 0.864 |
| (TCSVT 22)TMS-GAN | 23.45 | 0.909 | 26.13 | 0.931 | 21.85 | 0.831 |
| (CVPRW 23) ITB | 24.61 | 0.912 | 27.48 | 0.944 | 22.10 | 0.839 |
| Ours | 25.67 | 0.921 | 27.55 | 0.946 | 23.37 | 0.863 |
表4 在StateHaze⁃1k遥感数据集不同雾浓度数据集上UIQI和RMSE的对比 |
| Method | Thin fog | Moderate fog | Thick fog | |||
|---|---|---|---|---|---|---|
| UIQI | RMSE | UIQI | RMSE | UIQI | RMSE | |
| (TPAMI 10) DCP | 0.762 | 10.01 | 0.594 | 10.19 | 0.608 | 10.09 |
| (ICCV 17) AOD-Net | 0.859 | 9.64 | 0.822 | 9.96 | 0.724 | 9.98 |
| (CVPR 19) EPDN | 0.936 | 9.31 | 0.944 | 8.63 | 0.887 | 9.68 |
| (WACV19)GCANet | 0.948 | 9.26 | 0.932 | 9.41 | 0.922 | 9.44 |
| (CVPR 20) MSBDN | 0.927 | 9.53 | 0.948 | 9.14 | 0.887 | 9.68 |
| (AAAI 20) FFA | 0.968 | 8.37 | 0.973 | 7.96 | 0.946 | 9.06 |
| (CVPR 21) AECR-Net | 0.953 | 9.06 | 0.947 | 8.67 | 0.915 | 9.60 |
| (CVPR 21)TBN | 0.969 | 8.46 | 0.977 | 7.72 | 0.938 | 9.18 |
| (Tip 22) SGID | 0.963 | 8.86 | 0.972 | 8.97 | 0.939 | 9.62 |
| (TCSVT 22)TMS-GAN | 0.968 | 9.02 | 0.967 | 8.24 | 0.939 | 9.23 |
| (CVPRW 23) ITB | 0.974 | 8.41 | 0.978 | 7.42 | 0.945 | 9.10 |
| Ours | 0.976 | 8.30 | 0.979 | 7.37 | 0.957 | 8.80 |
表5 在SOTS⁃Outdoor数据集上PSNR和SSIM结果 |
| Model | PSNR/dB | SSIM |
|---|---|---|
| Base | 29.55 | 0.963 |
| Base+CLA | 31.42 | 0.964 |
| Base+CLA+CA | 33.52 | 0.975 |
| Base+CLA+ECA | 33.53 | 0.975 |
| Base+CLA+MSCA | 33.70 | 0.977 |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
张智, 易华挥, 郑锦. 聚焦小目标的航拍图像目标检测算法[J]. 电子学报, 2023, 51(4): 944-955.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
高继蕊, 李华锋, 张亚飞, 等. 双注意力引导的细节和结构信息融合图像去雾网络[J]. 电子学报, 2023, 51(1): 160-171.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
但志平, 方帅领, 孙航, 等. 基于双判别器异构CycleGAN框架下多阶通道注意力校准的室外图像去雾[J].电子学报, 2023, 51(9): 2558-2571.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 24 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 25 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 26 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 27 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 28 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 29 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 30 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 31 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 32 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 33 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 34 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 35 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 36 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 37 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 38 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 39 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 40 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 41 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 42 |
WOO S,
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 43 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 44 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 45 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 46 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 47 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 48 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 49 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 50 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 51 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 52 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 53 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 54 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 55 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 56 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(4602 KB)
PDF(4602 KB)
 图1 CLMSA-Net整体框架图2 跨层注意力特征交互模块图3 多尺度注意力机制
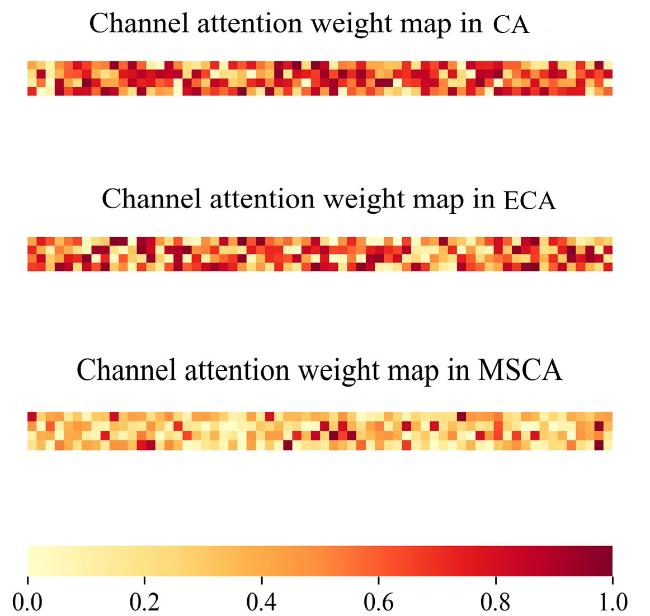
图1 CLMSA-Net整体框架图2 跨层注意力特征交互模块图3 多尺度注意力机制 表1 在自然场景数据集上PSNR和SSIM的对比表2 在自然场景数据集上UIQI和RMSE的对比表3 在StateHaze⁃1k遥感数据集不同雾浓度数据集上PSNR和SSIM的对比表4 在StateHaze⁃1k遥感数据集不同雾浓度数据集上UIQI和RMSE的对比图4 Reside-Outdoor合成数据集可视化结果图5 Dense-haze浓雾数据集可视化结果图6 NH-haze非均匀雾数据集可视化结果图7 StateHaze-1k遥感数据集薄-中-厚雾可视化结果表5 在SOTS⁃Outdoor数据集上PSNR和SSIM结果图8 MSCA通道注意力权重图
表1 在自然场景数据集上PSNR和SSIM的对比表2 在自然场景数据集上UIQI和RMSE的对比表3 在StateHaze⁃1k遥感数据集不同雾浓度数据集上PSNR和SSIM的对比表4 在StateHaze⁃1k遥感数据集不同雾浓度数据集上UIQI和RMSE的对比图4 Reside-Outdoor合成数据集可视化结果图5 Dense-haze浓雾数据集可视化结果图6 NH-haze非均匀雾数据集可视化结果图7 StateHaze-1k遥感数据集薄-中-厚雾可视化结果表5 在SOTS⁃Outdoor数据集上PSNR和SSIM结果图8 MSCA通道注意力权重图
/
| 〈 |
|
〉 |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}