 PDF(2687 KB)
PDF(2687 KB)

Erosion Clustering
DU Ming-jing, WU Fu-yu, LI Yu-rui, DONG Yong-quan
ACTA ELECTRONICA SINICA ›› 2024, Vol. 52 ›› Issue (10) : 3459-3471.
PDF(2687 KB)
PDF(2687 KB)
Erosion Clustering
Density-based clustering is a classical algorithm in cluster analysis, which can find non-spherical clusters without specifying the number of clusters in advance. In the real-world scene, there are still some issues, including unclear boundaries between clusters, varying densities of data, and complex cluster shapes. Most existing density-based clustering algorithms do not tackle these problems in a unified way. We counter this difficulty by taking inspiration from the natural erosion phenomenon to present erosion clustering (EC). Firstly, the proposed dynamic density evaluation method is integrated into the erosion strategy, which identifies and removes the data on the cluster boundary layer by layer, revealing the cores of the latent clusters. After that, a mutual-reachability-graph-based clustering is used to group the core data. Finally, the allocation strategy based on the local density peak is designed to associate the eroded data to different clusters. The experimental results on 12 benchmark datasets demonstrate that the clustering performance of the proposed EC algrithm is improved by an average of 96%, 53%, and 36% in the adjusted Rand index, adjusted mutual information, and F 1 score, respectively, comparing with the other seven algrithms.
density-based clustering / cluster analysis / density estimation / local density peak / mutual k-nearest neighbor / erosion strategy {{custom_keyword}} /
| 算法1 侵蚀聚类算法 |
|---|
| 输入:数据集X, 近邻数目k, 侵蚀层数L 输出:聚类结果 y 1. 计算数据间的距离 2. 计算互近邻关系 3. while 4. 依据 5. 执行侵蚀操作 6. 更新 7. end while 8. 依据互可达图 G 划分最终核心数据 9. 执行边界数据分配 |
表1 数据集的统计信息 |
| 数据集 | n/m/c | 数据集 | n/m/c |
|---|---|---|---|
| Square | 1 100/2/2 | Jain | 373/2/2 |
| SF | 4096/2/4 | Handl | 715/2/3 |
| T8 | 7677/2/8 | Shape5 | 3 150/2/5 |
| Zoo | 101/16/7 | Iris | 150/4/3 |
| Dermatology | 366/34/6 | WDBC | 569/30/2 |
| Penbased | 10 992/16/10 | HTRU2 | 17 898/8/2 |
表2 参数设置 |
| 算法 | 参数设置 |
|---|---|
| EC | k: [5:1:50]; L: [2:12] |
| DBSCAN | ε: [0.1:0.25:5.1]; k: [5:1:50] |
| HDBSCAN | k: [5:1:50]; m clSize: [5:5:20] |
| DP | dc : [2%:1%:10%]; α: [0.5:0.5:2.5] |
| DPC-CE | dc : [2%:1%:10%]; α: [0.5:0.5:2.5] |
| DEMOS | k: [5:1:50]; α: [0.5:0.5:2.5] |
| LGD | k: [5:1:50]; τ: [0.5:0.02:0.6]; α: [0.5:0.5:2.5] |
| BP | k: [5:1:50] |
表3 算法在人工数据集上的表现 |
| 算法 | ARI | AMI | F 1 | c | 参数 | ARI | AMI | F 1 | c | 参数 |
|---|---|---|---|---|---|---|---|---|---|---|
| Square | Jain | |||||||||
| EC | 1 | 1 | 1 | 2 | 16/2 | 1 | 1 | 1 | 2 | 16/2 |
| DBSCAN | 1 | 1 | 1 | 2 | 0.1/5 | 1 | 1 | 1 | 1 | 3.1/28 |
| HDBSCAN | 0.528 | 0.602 | 0.856 | 2 | 5/5 | 0.209 | 0.37 | 0.671 | 2 | 5/5 |
| DP | 0.633 | 0.781 | 0.889 | 3 | 3/1 | 0.334 | 0.615 | 0.824 | 5 | 6/2.5 |
| DPC-CE | 1 | 1 | 1 | 2 | 10/2.5 | 0.303 | 0.606 | 0.783 | 5 | 2/2.5 |
| DEMOS | 1 | 1 | 1 | 2 | 30/2.5 | 1 | 1 | 1 | 2 | 9/2 |
| LGD | 1 | 1 | 1 | 2 | 13/0.6/1 | 0.028 | 0.222 | 0.608 | 2 | 5/0.6/1.5 |
| BP | 0.494 | 0.672 | 0.836 | 5 | 50/3 | 0.478 | 0.675 | 0.856 | 5 | 13/3 |
| SF | Handl | |||||||||
| EC | 0.977 | 0.951 | 0.985 | 4 | 16/3 | 0.988 | 0.974 | 0.994 | 3 | 12/2 |
| DBSCAN | 0.135 | 0.482 | 0.476 | 77 | 0.1/5 | 0.72 | 0.664 | 0.655 | 9 | 0.1/5 |
| HDBSCAN | 0.127 | 0.304 | 0.481 | 1 | 21/20 | 0.25 | 0.357 | 0.581 | 1 | 9/15 |
| DP | 0.553 | 0.754 | 0.76 | 8 | 4/2.5 | 0.844 | 0.828 | 0.916 | 4 | 5/1.5 |
| DPC-CE | 0.346 | 0.66 | 0.627 | 15 | 6/2.5 | 0.762 | 0.817 | 0.734 | 2 | 8/2.5 |
| DEMOS | 0.976 | 0.95 | 0.983 | 4 | 17/2.5 | 0.754 | 0.782 | 0.849 | 3 | 9/1.5 |
| LGD | 0.894 | 0.897 | 0.783 | 3 | 25/0.6/1 | 0.762 | 0.818 | 0.734 | 2 | 28/0.58/1 |
| BP | 0.201 | 0.6 | 0.516 | 24 | 30/3 | 0.659 | 0.784 | 0.878 | 5 | 30/3 |
| T8 | Shape5 | |||||||||
| EC | 0.999 | 0.997 | 0.999 | 8 | 24/2 | 0.906 | 0.907 | 0.957 | 5 | 22/3 |
| DBSCAN | 0.934 | 0.925 | 0.916 | 23 | 0.1/10 | 0.474 | 0.719 | 0.666 | 3 | 0.6/5 |
| HDBSCAN | 0.26 | 0.44 | 0.343 | 1 | 50/20 | 0.644 | 0.651 | 0.626 | 2 | 5/20 |
| DP | 0.645 | 0.818 | 0.731 | 25 | 7/2.5 | 0.122 | 0.543 | 0.494 | 75 | 10/1 |
| DPC-CE | 0.421 | 0.734 | 0.633 | 41 | 9/2.5 | 0.177 | 0.523 | 0.604 | 30 | 9/1 |
| DEMOS | 0.908 | 0.946 | 0.79 | 6 | 35/2.5 | 0.475 | 0.726 | 0.671 | 3 | 25/2.5 |
| LGD | 0.88 | 0.895 | 0.662 | 5 | 10/0.6/1.5 | 0.463 | 0.609 | 0.728 | 5 | 5/0.6/1.5 |
| BP | 0.39 | 0.751 | 0.708 | 31 | 46/3 | 0.219 | 0.603 | 0.64 | 20 | 25/3 |
表4 算法在真实数据集上的表现 |
| 算法 | ARI | AMI | F 1 | c | 参数 | ARI | AMI | F 1 | c | 参数 |
|---|---|---|---|---|---|---|---|---|---|---|
| Zoo | Iris | |||||||||
| EC | 0.954 | 0.908 | 0.85 | 6 | 10/2 | 0.904 | 0.879 | 0.967 | 3 | 7/9 |
| DBSCAN | 0.918 | 0.864 | 0.798 | 5 | 1.35/5 | 0.568 | 0.759 | 0.778 | 2 | 0.35/21 |
| HDBSCAN | 0.365 | 0.538 | 0.495 | 2 | 5/15 | 0.001 | 0.017 | 0.497 | 1 | 25/20 |
| DP | 0.745 | 0.775 | 0.542 | 3 | 8/2.5 | 0.72 | 0.781 | 0.883 | 3 | 3/1 |
| DPC-CE | 0.716 | 0.769 | 0.513 | 3 | 9/2.5 | 0.568 | 0.759 | 0.777 | 2 | 10/2.5 |
| DEMOS | 0.16 | 0.311 | 0.492 | 12 | 5/0.5 | 0.568 | 0.759 | 0.777 | 2 | 9/1 |
| LGD | 0.813 | 0.782 | 0.633 | 4 | 5/0.58/1 | 0 | 0 | 0.167 | 1 | 28/0.6/1 |
| BP | 0.9 | 0.866 | 0.732 | 4 | 9/3 | 0.566 | 0.741 | 0.776 | 2 | 30/3 |
| Dermatology | WDBC | |||||||||
| EC | 0.852 | 0.918 | 0.884 | 5 | 8/6 | 0.792 | 0.702 | 0.94 | 2 | 5/10 |
| DBSCAN | 0.432 | 0.651 | 0.578 | 3 | 1.35/25 | 0.309 | 0.331 | 0.778 | 1 | 0.35/21 |
| HDBSCAN | 0.173 | 0.319 | 0.405 | 1 | 9/20 | 0.206 | 0.161 | 0.721 | 1 | 5/20 |
| DP | 0.839 | 0.841 | 0.884 | 10 | 5/2 | 0.08 | 0.267 | 0.381 | 170 | 10/0.5 |
| DPC-CE | 0.837 | 0.798 | 0.803 | 11 | 5/2 | 0.111 | 0.29 | 0.459 | 41 | 9/1 |
| DEMOS | 0.468 | 0.726 | 0.674 | 5 | 5/1.5 | 0 | 0 | 0.385 | 1 | 17/1 |
| LGD | 0.769 | 0.867 | 0.748 | 4 | 21/0.54/1 | 0.713 | 0.602 | 0.918 | 2 | 21/0.6/2 |
| BP | 0.026 | 0.021 | 0.647 | 1 | 30/3 | 0.437 | 0.736 | 0.621 | 23 | 9/3 |
| Penbased | HTRU2 | |||||||||
| EC | 0.776 | 0.847 | 0.851 | 28 | 15/10 | 0.809 | 0.668 | 0.916 | 2 | 36/12 |
| DBSCAN | 0.522 | 0.733 | 0.767 | 11 | 0.35/35 | 0.513 | 0.298 | 0.764 | 2 | 0.1/41 |
| HDBSCAN | 0.112 | 0.386 | 0.38 | 4 | 10/5 | 0.485 | 0.309 | 0.774 | 1 | 23/10 |
| DP | 0.509 | 0.73 | 0.64 | 174 | 7/2.5 | 0.02 | 0.174 | 0.496 | 41 | 4/2.5 |
| DPC-CE | 0.588 | 0.739 | 0.705 | 71 | 3/2.5 | 0.02 | 0.171 | 0.575 | 63 | 10/2.5 |
| DEMOS | 0.728 | 0.832 | 0.824 | 13 | 23/1 | 0.447 | 0.385 | 0.859 | 3 | 41/0.5 |
| LGD | 0.75 | 0.835 | 0.823 | 16 | 46/0.6/1 | 0 | 0 | 0.476 | 1 | 50/0.6/2.5 |
| BP | 0.73 | 0.818 | 0.817 | 19 | 46/3 | 0.397 | 0.365 | 0.687 | 5 | 50/3 |
表5 消融实验结果 |
| 算法 | ARI | AMI | F 1 |
|---|---|---|---|
| EC | 0.913 | 0.896 | 0.945 |
| EC-ASF | 0.892 | 0.866 | 0.913 |
| EC-DM | 0.873 | 0.853 | 0.924 |
| EC-DDF | 0.790 | 0.789 | 0.851 |
| EC-ES | 0.588 | 0.661 | 0.736 |
| EC-ER | 0.828 | 0.826 | 0.895 |
| EC-LDP | 0.616 | 0.702 | 0.814 |
表6 算法在具有噪声的数据集上的表现 |
| 算法 | ARI | AMI | F 1 | c | ARI | AMI | F 1 | c | ARI | AMI | F 1 | c |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Jain+ | Handl+ | T8+ | ||||||||||
| EC | 1 | 1 | 1 | 2+1 | 0.975 | 0.951 | 0.983 | 3+1 | 0.991 | 0.981 | 0.987 | 8+1 |
| DBSCAN | 0.951 | 0.906 | 0.731 | 1+1 | 0.690 | 0.639 | 0.546 | 9+1 | 0.928 | 0.919 | 0.885 | 23+1 |
| HDBSCAN | 0.168 | 0.344 | 0.491 | 2+1 | 0.354 | 0.364 | 0.503 | 1+1 | 0.274 | 0.547 | 0.334 | 1+1 |
| DP | 0.217 | 0.373 | 0.417 | 6+0 | 0.809 | 0.741 | 0.737 | 16+0 | 0.598 | 0.760 | 0.649 | 72+0 |
| DPC-CE | 0.231 | 0.495 | 0.523 | 7+0 | 0.692 | 0.724 | 0.562 | 2+0 | 0.380 | 0.677 | 0.565 | 56+0 |
| DEMOS | 0.877 | 0.839 | 0.683 | 2+0 | 0.692 | 0.724 | 0.562 | 2+0 | 0.814 | 0.848 | 0.780 | 10+0 |
| LGD | 0.067 | 0.209 | 0.449 | 2+0 | 0.694 | 0.725 | 0.565 | 2+0 | 0.822 | 0.855 | 0.600 | 5+0 |
| BP | 0.345 | 0.666 | 0.854 | 5+1 | 0.676 | 0.799 | 0.902 | 5+1 | 0.377 | 0.728 | 0.684 | 34+1 |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
徐晓, 丁世飞, 丁玲. 密度峰值聚类算法研究进展[J]. 软件学报, 2022, 33(5): 1800-1816.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 24 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 25 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 26 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 27 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 28 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 29 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 30 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(2687 KB)
PDF(2687 KB)
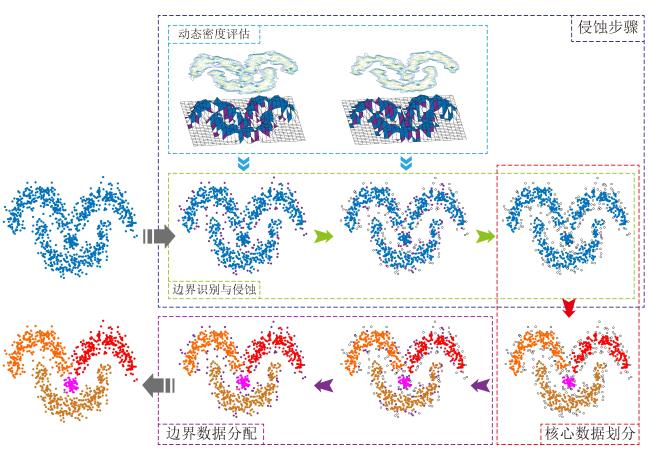
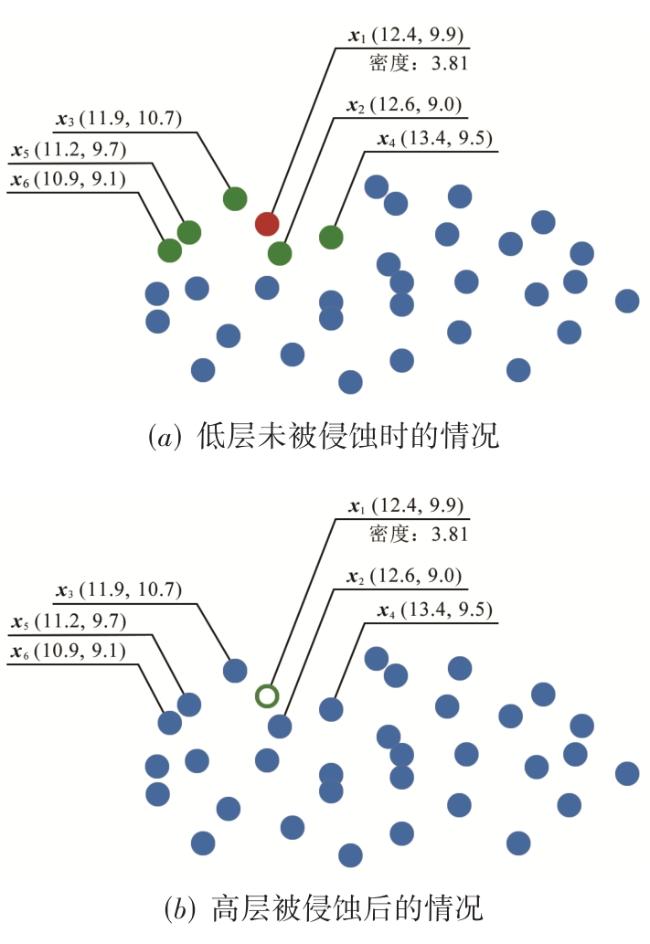
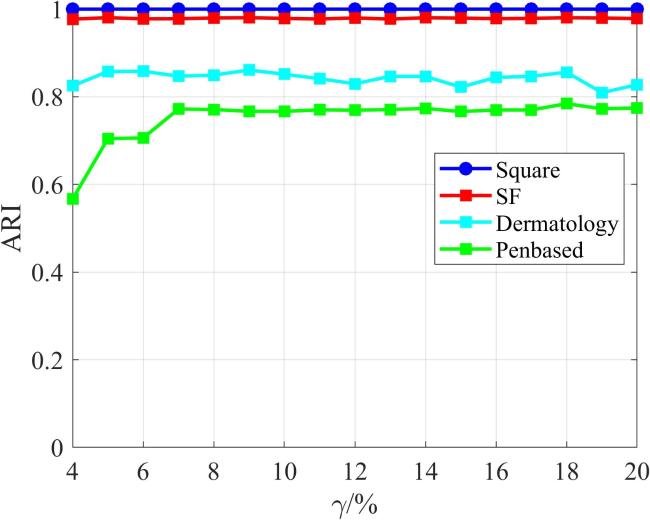
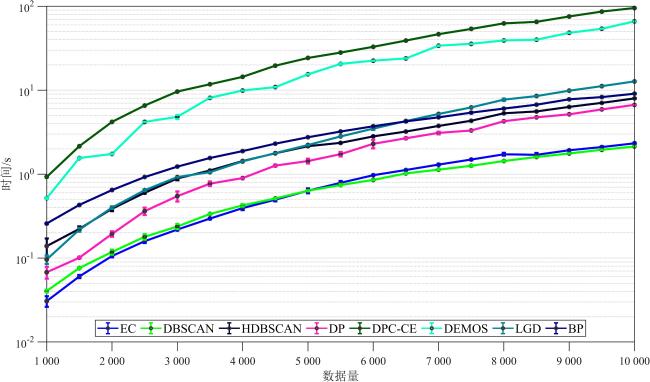
 图1 侵蚀聚类整体结构图2 侵蚀前后的密度
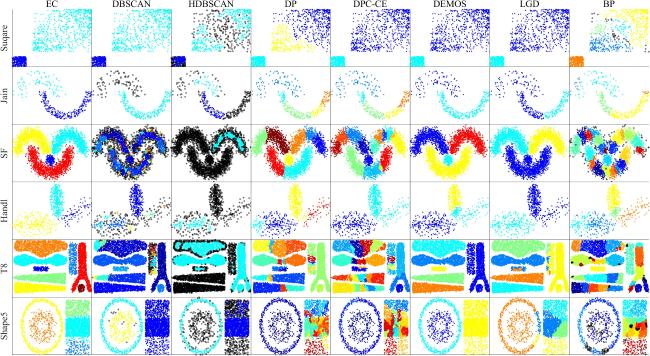
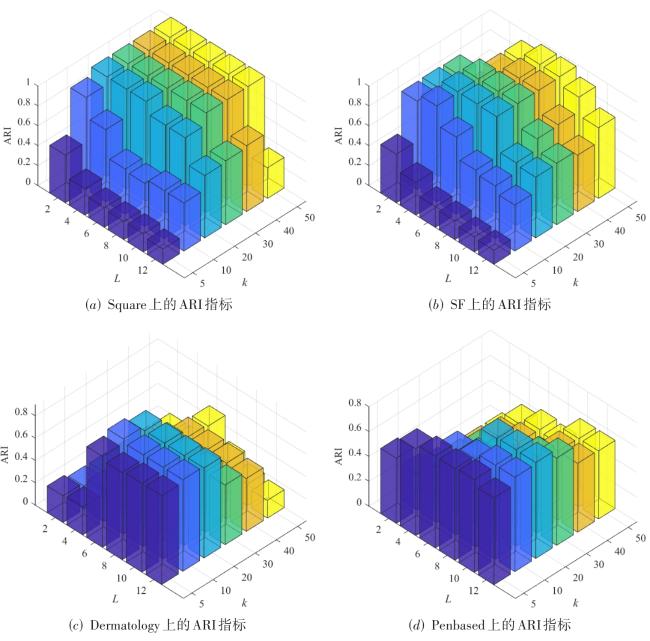
图1 侵蚀聚类整体结构图2 侵蚀前后的密度 表1 数据集的统计信息表2 参数设置图3 人工数据集聚类结果表3 算法在人工数据集上的表现表4 算法在真实数据集上的表现图4 不同L和k下EC的性能变化图5 不同γ值下EC的性能变化图6 运行时间的比较表5 消融实验结果图7 具有噪声的数据集上的可视化效果表6 算法在具有噪声的数据集上的表现
表1 数据集的统计信息表2 参数设置图3 人工数据集聚类结果表3 算法在人工数据集上的表现表4 算法在真实数据集上的表现图4 不同L和k下EC的性能变化图5 不同γ值下EC的性能变化图6 运行时间的比较表5 消融实验结果图7 具有噪声的数据集上的可视化效果表6 算法在具有噪声的数据集上的表现
/
| 〈 |
|
〉 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}