 PDF(1448 KB)
PDF(1448 KB)

融合语言模型的端到端中文语音识别算法
吕坤儒, 吴春国, 梁艳春, 袁宇平, 任智敏, 周柚, 时小虎
电子学报 ›› 2021, Vol. 49 ›› Issue (11) : 2177-2185.
PDF(1448 KB)
PDF(1448 KB)
融合语言模型的端到端中文语音识别算法
An End-to-End Chinese Speech Recognition Algorithm Integrating Language Model
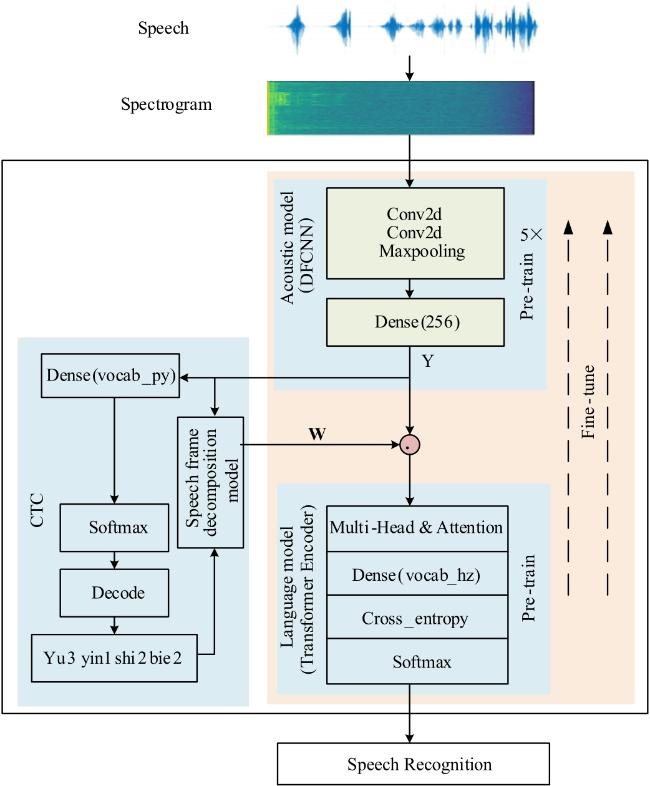
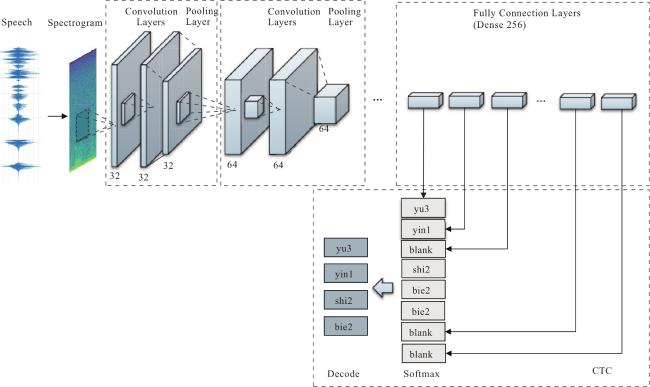
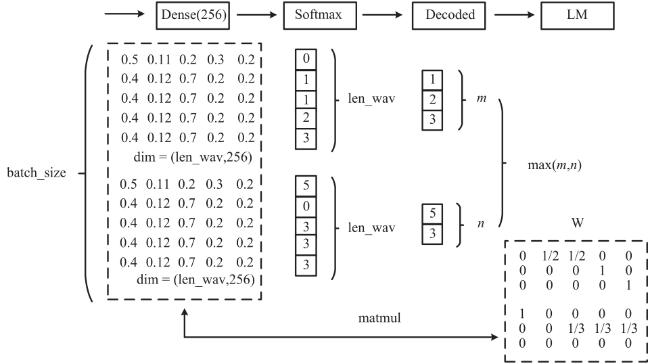
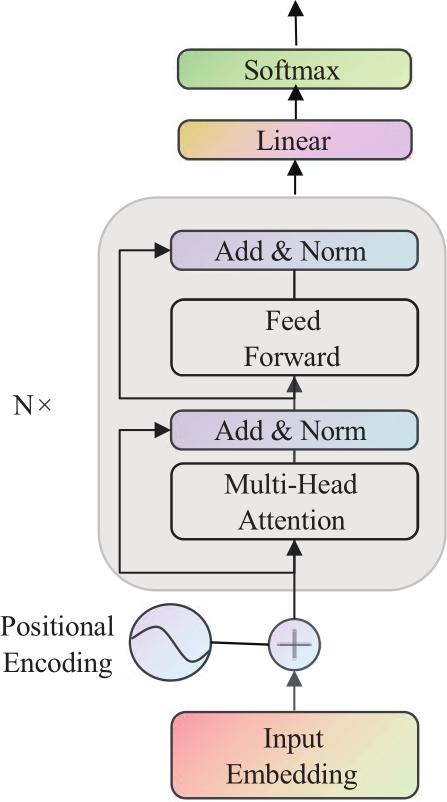
为了解决语音识别模型在识别中文语音时鲁棒性差,缺少语言建模能力而无法有效区分同音字或近音字的不足,本文提出了融合语言模型的端到端中文语音识别算法.算法建立了一个基于深度全序列卷积神经网络和联结时序分类的从语音到拼音的语音识别声学模型,并借鉴Transformer的编码模型,构建了从拼音到汉字的语言模型,之后通过设计语音帧分解模型将声学模型的输出和语言模型的输入相连接,克服了语言模型误差梯度无法传递给声学模型的难点,实现了声学模型和语言模型的联合训练.为验证本文方法,在实际数据集上进行了测试.实验结果表明,语言模型的引入将算法的字错误率降低了21%,端到端的联合训练算法起到了关键作用,其对算法的影响达到了43%.和已有5种主流算法进行比较的结果表明本文方法的误差明显低于其他5种对比模型,与结果最好的DeepSpeech2模型相比字错误率降低了28%.
To address the problems of poor robustness, lack of language modeling ability and inability to distinguish between homophones or near-tone characters effectively in the recognition of Chinese speech, an end-to-end Chinese speech recognition algorithm integrating language model is proposed. Firstly, an acoustic model from speech to Pinyin is established based on Deep Fully Convolutional Neural Network (DFCNN) and Connectionist Temporal Classification (CTC). Then the language model from Pinyin to Chinese character is constructed by using the encoder of Transformer. Finally, the speech frame decomposition model is designed to link the output of the acoustic model with the input of the language model, which overcomes the difficulty that the gradient of loss function cannot be passed from the language model to the acoustic model, and realizes the end-to-end training of the acoustic model and the language model. Real data sets are applied to verify the proposed method. Experimental results show that the introduction of language model reduces the word error rate (WER) of the algorithm by 21%, and the end-to-end integrating training algorithm plays a key role, which improves the performance by 43%. Compared with five up-to-date algorithms, our method achieves a 28% WER, lower than that of the best model among comparison methods—DeepSpeech2.
语音识别 / 联结时序分类 / 语言模型 / 声学模型 / 语音帧分解 {{custom_keyword}} /
speech recognition / CTC / language model / acoustic model / speech frame decomposition {{custom_keyword}} /
| |
|---|
| 输入: 语音帧矩阵L∈ Rlen_wav×vocal,音节序列S∈ Z len_yinjie 输出: 语音帧对应输出音节的权重矩阵W 1: FUNCTION SyllableWeightCal(L, S) 2: W ← 0 3: pos ← 1 4: FORi = 1 to len_wavDO 5: cont ← True 6: begin ← False 7: WHILEcont ANDpos ≤ len_wav 8: IFS(i) = 9: begin ← True 10: W (i,pos) ← 1 11: ELSE IFbegin THEN 12: cont ← False 13: END IF 14: pos ← pos + 1 15: END WHILE 16: END FOR 17: W ← 按行归一化W 18: RETURN W 19: END FUNCTION |
表1 不同模型结构参数 |
| 模型 | 网络结构参数 | 声学建模单元 |
|---|---|---|
| DFCNN | 5×2D_CNN+2×FNN | 汉字 |
| DFCNN +Transformer Encoder | 5×2D_CNN+2×FNN +Transformer Encoder | 带音调音节 |
| BLSTM-DNN-CTC[27] | 5×DNN+3×BLSTM+2×FNN | 汉字 |
| CNN-LSTM -DNN-CTC[14] | 3×CNN+3×LSTM+4×FNN | 汉字 |
| DCNN-DNN-CTC[9] | 10×CNN_maxout +3×FNN_maxout | 汉字 |
| ResNet-BLSTM[28] | 8×CNN(4×Res)+2×BLSTM | 汉字 |
| Deep Speech2[15] | 3×1D_CNN+3×GRU+FNN | 汉字 |
| ECSRILM | 5×2D_CNN+2×FNN +Transformer Encoder | 汉字 |
表2 纵向对比实验结果 |
| 模型结构 | 字错误率(%) |
|---|---|
| DFCNN | 15.06 |
| DFCNN+Transformer Encoder | 20.72 |
| ECSRILM | 11.88 |
| 1 |
杨明浩,高廷丽,陶建华,等.对话意图及语音识别错误对交互体验的影响[J]. 软件学报, 2016, 27(S2): 69 - 75.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
王海坤,潘嘉,刘聪.语音识别技术的研究进展与展望[J]. 电信科学报, 2018, 2: 1 - 11.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 24 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 25 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 26 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 27 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 28 |
胡章芳,徐轩,付亚芹,等.基于ResNet-BLSTM的端到端语音识别[J].计算机工程与应用, 2020, 56(18): 124-130.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(1448 KB)
PDF(1448 KB)


/
| 〈 |
|
〉 |









{kind=link}
{kind=link}
{kind=link}
{kind=link}