 PDF(1398 KB)
PDF(1398 KB)
 PDF(1398 KB)
PDF(1398 KB)
PDF(1398 KB)
PDF(1398 KB)
面向概念漂移和类不平衡数据流的在线分类算法
Online Classification Algorithm for Concept Drift and Class Imbalance Data Stream
数据流是大数据的重要形式,数据流分类是数据挖掘的重要任务之一,该任务在现实生活中有着巨大的应用前景,因此得到了研究者们的广泛关注.概念漂移和类不平衡是影响数据流分类性能的两个核心问题,但目前大多数算法都只考虑处理两者之一,并且大多数算法过于理想,只能在人工设置的数据流上才能发挥较好的性能,无法适用于复杂的真实数据流.针对这一问题,提出了一种同时处理概念漂移和类不平衡复杂数据流的算法——具有自适应遗忘因子的加权在线顺序极限学习机集成算法.该算法首先融合加权机制和遗忘机制,初步提出具有遗忘机制的加权在线顺序极限学习机算法.为了更好地适应复杂数据流,进一步以初步算法为基分类器,设计包含自适应遗忘因子和概念漂移检测机制的在线集成策略.大量仿真实验表明,所提算法在所有数据集上都取得了最佳的Gmean值,具有更好的概念漂移和类不平衡适应能力,表现出了更稳定、更平衡以及更准确的分类效果.
Data stream is an important form of big data, and data stream classification is one of the most important tasks in data mining. This task finds wide application in our life, so it has been attracting great attention of researchers. Concept drift and class imbalance are two main issues that affect the performance of data stream classification algorithms. However, most solutions only address one of these two issues. Even worse, most algorithms can only achieve good performance on data streams under manual settings and cannot be applied to real complex data streams. To solve this problem, an ensemble algorithm of weighted online sequential extreme learning machine with adaptive forgetting factor is proposed to deal with both conceptual drift and imbalance on complex data streams. The proposed algorithm is a weighted online sequential limit learning machine that integrates a weighting mechanism and a forgetting mechanism. In order to adapt to complex data streams, an online integration strategy including adaptive forgetting factor and concept drift detection mechanism was designed as a classifier. Extensive simulation experiments show that the proposed algorithm achieves the best Gmean value on all data sets, has the ability to deal with concept drift and class imbalance, and presents stable, balanced and accurate classification effects.
数据流分类 / 概念漂移 / 类不平衡 / 在线学习 / 极限学习机 {{custom_keyword}} /
data stream classification / concept drift / class imbalance / online learning / extreme learning machine {{custom_keyword}} /
| |
|---|
| 输入:数据流( X, y), 初始化训练数量m 输出:Acc,Rec, Spe,Gmean,D(Rec,Spe) 1. // 1.初始化阶段 2. 初始化基分类器的结构; 3. 生成M 个不同的基分类器(BC, base classifier) ; 4. 随机生成每个基分类器的输入层权重和偏置; 5. 通过 6. 保存 P 和 β0 到基分类器结构(BC_struct)中; 7. // 结束初始化阶段 8. // 2.在线学习阶段 9. // 2.1.分类阶段 10. 通过 11. 通过 12. 更新Acc, Rec, Spe, Gmean,D(Rec,Spe); 13. // 结束该轮分类; 14. // 2.2.在线学习与更新阶段; 15. 更新集成分类器的混淆矩阵; 16. 更新0类权重; 17. 计算概念漂移指数CDI; 18. 如果CDI <= 0.9 则更新遗忘因子λ; 19.for k=1 to M; 20. 更新 BC_CM k; 21. 更新投票权重 Vk; 22. 更新类别权重修正项CF k; 23. 计算更新权重wk; 24. 更新 Pk 和 βk; 25. // 结束本轮学习 |
表1 实验数据集信息 |
| 数据集 | 实例数 | 特征数 | IR | 漂移类型 |
|---|---|---|---|---|
| Sine_2 | 20k | 4 | 2 | 反转、突变 |
| Sine_4 | 20k | 4 | 4 | 反转、突变 |
| Sine_9 | 20k | 4 | 9 | 反转、突变 |
| Sea_s_2 | 20k | 3 | 2 | 突变型 |
| Sea_s_4 | 20k | 3 | 4 | 突变型 |
| Sea_s_9 | 20k | 3 | 9 | 突变型 |
| Sea_g_2 | 20k | 3 | 2 | 渐变型 |
| Sea_g_4 | 20k | 3 | 4 | 渐变型 |
| Sea_g_9 | 20k | 3 | 9 | 渐变型 |
| Elec | 45312 | 6 | - | 真实数据集 |
| Weather | 18159 | 8 | - | 真实数据集 |
| Sine_100k | 100k | 4 | 4 | 反转、突变 |
| Sine_1M | 1M | 4 | 4 | 反转、突变 |
| Sine_10M | 10M | 4 | 4 | 反转、突变 |
表2 二分类中的混淆矩阵 |
| 预测为'0'类 | 预测为'1'类 | |
|---|---|---|
| 实际为'0'类 | TN | FP |
| 实际为'1'类 | FN | TP |
表3 算法在不同大小数据集上的表现 |
| Sine 20k | Sine 100k | Sine 1M | Sine 10M | |
|---|---|---|---|---|
| Acc | 94.38 | 94.39 | 94.33 | 94.32 |
| Rec | 94.08 | 94.22 | 94.13 | 94.12 |
| Spe | 95.59 | 95.1 | 95.12 | 95.12 |
| Gmean | 94.83 | 94.66 | 94.62 | 94.62 |
| D(Rec,Spe) | 1.51 | 0.88 | 0.99 | 1.00 |
| Time/s | 25.47 | 134.55 | 1291.56 | 12784.87 |
表4 对比算法在不同数据集上的综合性能表现 (%) |
| Datasets | Evaluation | EAFW OSELM | FW OSELM | VW OSELM | W OSELM | FR OSELM | OSELM | LPP | SRP |
|---|---|---|---|---|---|---|---|---|---|
| Sine_2 | Acc | 95.07 | 84.93 | 48.05 | 47.89 | 91.78 | 67.59 | 90.14 | 78.99 |
| Rec | 94.89 | 84.37 | 44.28 | 42.95 | 97.38 | 90.92 | 92.08 | 92.49 | |
| Spe | 95.42 | 86.07 | 55.58 | 57.75 | 80.59 | 20.96 | 86.25 | 52.00 | |
| Gmean | 95.15 | 85.22 | 49.61 | 49.80 | 88.59 | 43.65 | 89.12 | 69.35 | |
| D(Rec,Spe) | 0.53 | 1.70 | 11.30 | 14.80 | 16.79 | 69.96 | 5.83 | 40.49 | |
| Sine_4 | Acc | 94.38 | 84.85 | 44.89 | 44.14 | 92.44 | 80.72 | 92.05 | 84.55 |
| Rec | 94.08 | 84.62 | 41.49 | 39.99 | 98.97 | 96.76 | 94.69 | 97.41 | |
| Spe | 95.59 | 85.76 | 58.48 | 60.76 | 66.26 | 16.47 | 81.45 | 33.05 | |
| Gmean | 94.83 | 85.19 | 49.26 | 49.29 | 80.98 | 39.92 | 87.82 | 56.74 | |
| D(Rec,Spe) | 1.51 | 1.14 | 16.99 | 20.77 | 32.71 | 80.29 | 13.24 | 64.36 | |
| Sine_9 | Acc | 94.08 | 83.53 | 40.82 | 39.45 | 94.32 | 90.28 | 94.49 | 91.23 |
| Rec | 93.98 | 83.19 | 38.24 | 36.49 | 99.79 | 99.22 | 96.91 | 99.48 | |
| Spe | 94.96 | 86.56 | 63.82 | 65.80 | 45.50 | 10.43 | 72.88 | 17.61 | |
| Gmean | 94.47 | 84.86 | 49.40 | 49.00 | 67.38 | 32.17 | 84.04 | 41.86 | |
| D(Rec,Spe) | 0.98 | 3.37 | 25.58 | 29.31 | 54.29 | 88.79 | 24.03 | 81.87 | |
| Sea_s_2 | Acc | 92.25 | 91.64 | 90.16 | 90.53 | 90.28 | 88.71 | 90.15 | 90.76 |
| Rec | 92.3 | 92.57 | 93.66 | 93.59 | 97.51 | 98.03 | 93.24 | 95.67 | |
| Spe | 92.13 | 89.76 | 83.11 | 84.36 | 75.70 | 69.92 | 83.93 | 80.88 | |
| Gmean | 92.21 | 91.15 | 88.23 | 88.86 | 85.92 | 82.79 | 88.46 | 87.96 | |
| D(Rec,Spe) | 0.17 | 2.81 | 10.55 | 9.23 | 21.81 | 28.11 | 9.31 | 14.79 | |
| Sea_s_4 | Acc | 92.5 | 91.54 | 91.28 | 90.82 | 91.69 | 91.24 | 91.56 | 90.15 |
| Rec | 92.77 | 91.86 | 93.02 | 91.95 | 98.57 | 98.74 | 95.15 | 97.68 | |
| Spe | 91.41 | 90.28 | 84.31 | 86.29 | 64.06 | 61.10 | 77.13 | 59.89 | |
| Gmean | 92.09 | 91.07 | 88.56 | 89.08 | 79.46 | 77.67 | 85.67 | 76.49 | |
| D(Rec,Spe) | 1.36 | 1.58 | 8.71 | 5.66 | 34.51 | 37.64 | 18.02 | 37.79 | |
| Sea_s_9 | Acc | 93.68 | 90.62 | 90.34 | 87.68 | 94.30 | 94.08 | 93.47 | 92.18 |
| Rec | 93.97 | 90.68 | 90.86 | 87.63 | 98.91 | 98.95 | 96.77 | 99.44 | |
| Spe | 91.12 | 89.99 | 85.68 | 88.19 | 52.72 | 50.21 | 63.71 | 26.85 | |
| Gmean | 92.53 | 90.33 | 88.23 | 87.91 | 72.21 | 70.49 | 78.52 | 51.67 | |
| D(Rec,Spe) | 2.85 | 0.69 | 5.18 | 0.56 | 46.19 | 48.74 | 33.06 | 72.59 | |
| Sea_g_2 | Acc | 91.59 | 90.82 | 89.77 | 90.07 | 89.84 | 88.63 | 89.34 | 83.64 |
| Rec | 91.55 | 91.62 | 93.36 | 92.66 | 97.17 | 97.94 | 92.49 | 93.14 | |
| Spe | 91.66 | 89.22 | 82.63 | 84.90 | 75.24 | 70.09 | 83.09 | 64.73 | |
| Gmean | 91.6 | 90.41 | 87.83 | 88.70 | 85.50 | 82.85 | 87.66 | 77.65 | |
| D(Rec,Spe) | 0.11 | 2.40 | 10.73 | 7.76 | 21.93 | 27.85 | 9.40 | 28.41 | |
| Sea_g_4 | Acc | 91.54 | 90.68 | 90.68 | 90.02 | 91.48 | 90.97 | 90.89 | 86.64 |
| Rec | 91.59 | 91.02 | 92.40 | 90.93 | 98.48 | 98.76 | 94.80 | 98.09 | |
| Spe | 91.53 | 89.26 | 83.56 | 86.24 | 62.62 | 58.89 | 74.78 | 39.43 | |
| Gmean | 91.46 | 90.14 | 87.87 | 88.55 | 78.53 | 76.26 | 84.20 | 62.19 | |
| D(Rec,Spe) | 0.26 | 1.76 | 8.84 | 4.69 | 35.86 | 39.87 | 20.02 | 58.66 | |
| Sea_g_9 | Acc | 91.44 | 89.49 | 89.01 | 87.38 | 94.01 | 93.81 | 92.65 | 91.83 |
| Rec | 91.53 | 89.64 | 89.56 | 87.40 | 98.76 | 98.95 | 96.23 | 99.51 | |
| Spe | 90.63 | 88.15 | 84.10 | 87.24 | 51.80 | 48.15 | 60.91 | 23.59 | |
| Gmean | 91.08 | 88.89 | 86.79 | 87.32 | 71.52 | 69.02 | 76.56 | 48.45 | |
| D(Rec,Spe) | 0.9 | 1.49 | 5.46 | 0.16 | 46.96 | 50.80 | 35.32 | 75.92 | |
| Elec | Acc | 87.9 | 77.78 | 75.84 | 75.17 | 84.63 | 75.01 | 75.08 | 84.29 |
| Rec | 88.24 | 74.64 | 62.43 | 63.54 | 78.03 | 54.26 | 69.49 | 78.02 | |
| Spe | 87.66 | 80.09 | 85.71 | 83.74 | 89.50 | 90.30 | 79.19 | 88.91 | |
| Gmean | 87.95 | 77.32 | 73.15 | 72.94 | 83.57 | 70.00 | 74.18 | 83.29 | |
| D(Rec,Spe) | 0.58 | 5.45 | 23.28 | 20.20 | 11.47 | 36.04 | 9.70 | 10.89 | |
| Weather | Acc | 80.12 | 73.10 | 72.20 | 70.94 | 78.81 | 76.76 | 69.43 | 75.38 |
| Rec | 80.11 | 84.57 | 85.43 | 86.53 | 59.72 | 62.19 | 54.33 | 54.99 | |
| Spe | 80.12 | 67.83 | 66.11 | 63.77 | 87.59 | 83.46 | 76.38 | 84.75 | |
| Gmean | 80.11 | 75.74 | 75.15 | 74.28 | 72.32 | 72.04 | 64.42 | 68.27 | |
| D(Rec,Spe) | 0.01 | 16.74 | 19.32 | 22.76 | 27.87 | 21.27 | 22.05 | 29.76 |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(1398 KB)
PDF(1398 KB)
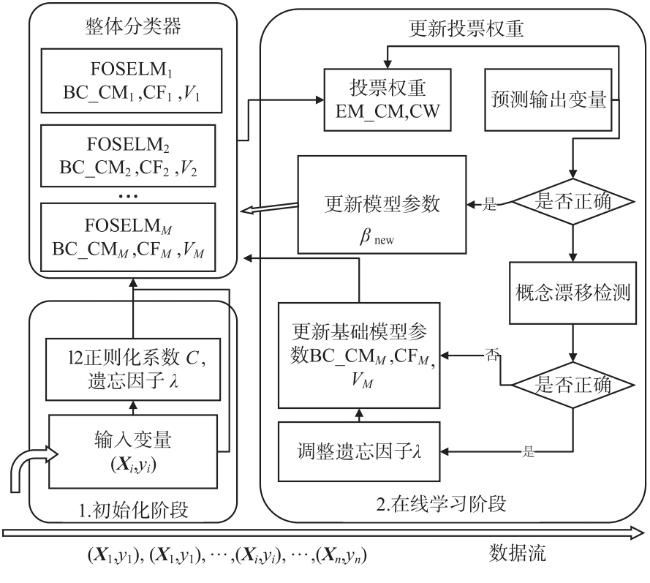
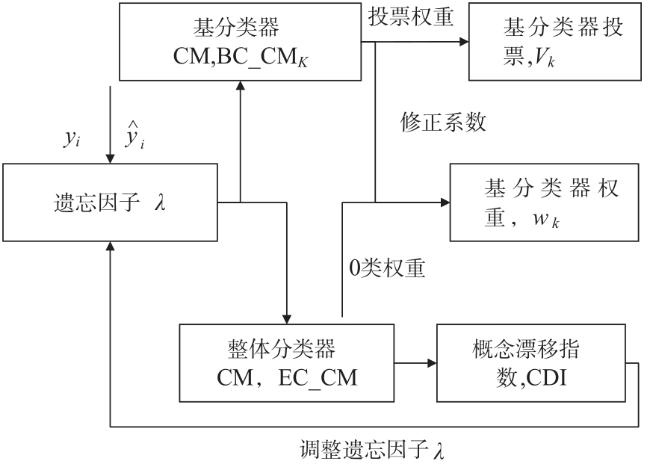
 图1 EAFWOSELM算法的整体框架图2 自适应组件更新机制
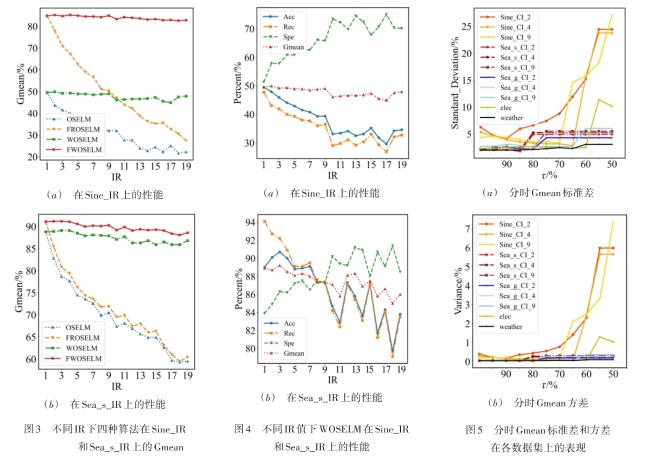
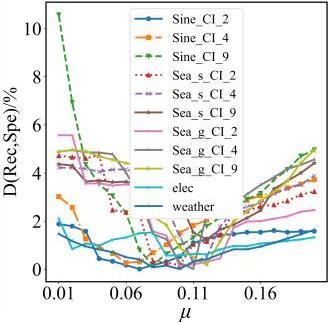
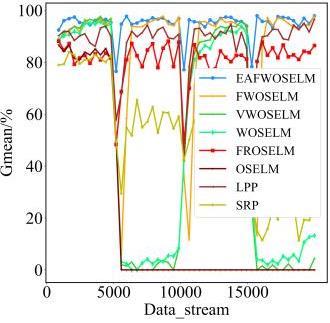
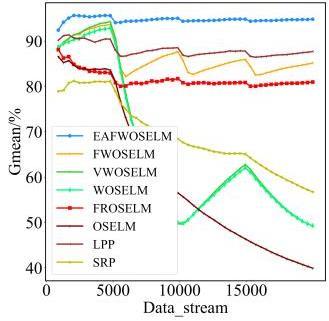
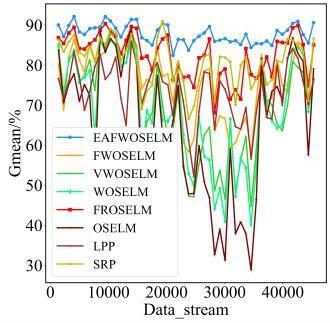
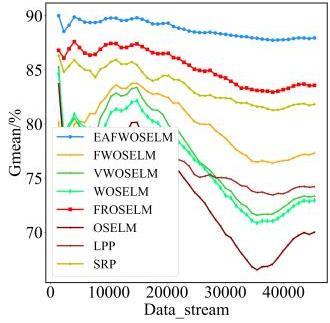
图1 EAFWOSELM算法的整体框架图2 自适应组件更新机制 表1 实验数据集信息表2 二分类中的混淆矩阵图3 不同IR下四种算法在Sine_IR图6 不同μ值下D(Rec,Spe)在各数据集上的表现表3 算法在不同大小数据集上的表现图7 对比算法在Sine_4上的分时Gmean图8 对比算法在Sine_4上的实时Gmean图9 对比算法在Elec上的分时Gmean图10 对比算法在Elec上实时Gmean表4 对比算法在不同数据集上的综合性能表现 (%)
表1 实验数据集信息表2 二分类中的混淆矩阵图3 不同IR下四种算法在Sine_IR图6 不同μ值下D(Rec,Spe)在各数据集上的表现表3 算法在不同大小数据集上的表现图7 对比算法在Sine_4上的分时Gmean图8 对比算法在Sine_4上的实时Gmean图9 对比算法在Elec上的分时Gmean图10 对比算法在Elec上实时Gmean表4 对比算法在不同数据集上的综合性能表现 (%)

/
| 〈 |
|
〉 |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}