 PDF(1027 KB)
PDF(1027 KB)
 PDF(1027 KB)
PDF(1027 KB)
PDF(1027 KB)
PDF(1027 KB)
混合帝国竞争算法求解带多行程批量配送的多工厂集成调度问题
Hybrid Imperialist Competitive Algorithm for Solving Multi-Factory Integrated Scheduling Problem with Multi-Trip Batch Delivery
针对供应链中一类广泛存在的带多行程批量配送的多工厂集成调度问题(Multi-Factory Integrated Scheduling Problem with Multi-Trip Batch Delivery,MFISP_MTBD),建立其数学模型并提出基于贝叶斯统计推断的混合帝国竞争算法(Hybrid Bayesian statistical inference-based Imperialist Competitive Algorithm,HBICA)进行求解.根据MFISP_MTBD问题特性,结合多行程标签机制设计新型编解码策略,并基于该策略构造新型启发式规则以提高初始解的质量.为有效保留优质解的模式信息,采用贝叶斯概率模型学习机制替换标准帝国竞争算法中的同化机制.为更加明确地引导搜索方向,算法每代均利用各帝国中的精英国家(即精英解或个体)重构贝叶斯概率模型,进而对其采样生成新种群.利用9种有效邻域操作动态构造各帝国中每个国家的局部搜索,并对由各帝国内部相邻国家间竞争所确定的强势国家(即获胜国)执行其局部搜索,进而对各帝国中的殖民国家(即该帝国内的最强国家)依次执行所有弱势国家的局部搜索.仿真实验和算法比较验证了所提算法可有效求解MFISP_MTBD.
Aiming at a kind of widely existing multi-factory integrated scheduling problem with multi-trip batch delivery(MFISP_MTBD) in the supply chain, this paper establishes the mathematical model, and a hybrid Bayesian statistical inference-based imperialist competitive algorithm(HBICA) is proposed to solve it. According to the characteristics of the MFISP_MTBD, a new encoding and decoding strategy based on multi-trip labeling mechanism is proposed, on this basis, a new heuristic rule is constructed to improve the quality of the initial solution. To effectively preserve the pattern information of the high-quality solution, the Bayesian probability model learning mechanism is used to replace the assimilation mechanism in the imperial competition algorithm. Afterwards, each generation of the algorithm reconstructs the Bayesian probability model by using the elite countries(i.e. elite solution or individual) in each empire to guide the search direction explicitly, and new population is generated by sampling it. The local search for each country in each empire is dynamically constructed by 9 effective neighborhood operations. Local search is carried out on the strong country(i.e. the winning country) determined by the competition among neighboring countries within the empire, and local search of weak countries is carried out in turn for the colonial countries in each empire(i.e. the strongest countries in the empire). Simulation experiments and comparisons on different instances demonstrate that the proposed algorithm can effectively solve MFISP_MTBD.
多工厂供应链 / 多行程配送 / 集成调度 / 贝叶斯统计推断 / 帝国竞争算法 {{custom_keyword}} /
multi-factory supply chain / multi-trip delivery / integrated scheduling / Bayesian statistical inference / imperialist competitive algorithm {{custom_keyword}} /
表1 符号表 |
| 符号 | 说明 |
|---|---|
| | 工件或客户下标, |
| | 工厂编号 |
| | 车辆编号 |
| | 车辆行程编号 |
| | 各工厂加工产生的总功耗 |
| | 单位电价 |
| | 工件 |
| | 车辆的自重 |
| | 车辆在客户 |
| | 客户 |
| | |
| | 工件 |
| | 车辆与加速度、滚动阻力、重力等相关的油耗系数 |
| | 车辆与空气密度和车辆前表面积等相关的油耗系数 |
| | 车辆在客户 |
| | 配送阶段产生的总油耗 |
| | 单位油价 |
| | 工件 |
| | 违约超时的惩罚系数 |
| | 如果工件 |
| | 如果工件 |
| | 若客户 |
| | 若客户 |
表2 ICA、ED_ICA、B_ICA与HBICA的有效性对比结果 |
| 问题规模 | ICA | ED_ICA | B_ICA | HBICA |
|---|---|---|---|---|
| AVG | AVG | AVG | AVG | |
| 20×4 | 14 450.9 | 14 988.0 | 14 340.5 | 14 199.9 |
| 25×4 | 14 494.4 | 15 357.3 | 13 815.2 | 13 873.7 |
| 30×4 | 26 201.7 | 26 782.9 | 25 864.8 | 25 596.4 |
| 35×5 | 31 427.5 | 32 927.3 | 30 487.5 | 30 053.6 |
| 40×5 | 30 568.0 | 31 770.0 | 29 822.2 | 28 684.1 |
| 45×5 | 38 818.3 | 40 691.0 | 38 403.7 | 36 964.1 |
| 50×5 | 35 008.1 | 36 311.2 | 34 476.0 | 33 051.3 |
| 55×5 | 43 688.4 | 48 533.1 | 42 848.4 | 40 734.6 |
| 60×5 | 39 830.7 | 41 186.8 | 38 931.9 | 36 048.2 |
| 70×6 | 55 374.2 | 57 541.4 | 53 308.9 | 49 980.1 |
| 75×6 | 58 836.0 | 60 235.3 | 56 007.4 | 51 461.8 |
| 80×6 | 66 920.6 | 68 368.6 | 65 620.3 | 61 159.9 |
| 85×6 | 72 998.5 | 75 846.1 | 70 183.5 | 65 691.7 |
| 90×6 | 81 412.9 | 84 581.4 | 79 584.2 | 74 158.8 |
| 95×6 | 92 680.9 | 95 428.5 | 89 531.7 | 82 419.5 |
| 100×7 | 103 939.1 | 106 037.4 | 100 467.0 | 95 075.9 |
| 110×7 | 105 511.1 | 107 240.7 | 101 652.1 | 94 401.1 |
| 120×7 | 107 714.9 | 110 023.9 | 102 244.8 | 92 399.4 |
| 130×8 | 114 532.1 | 115 963.7 | 111 945.5 | 104 564.7 |
| 140×8 | 130 273.5 | 130 546.4 | 126 380.4 | 117 835.0 |
| 150×8 | 145 919.3 | 147 666.2 | 139 694.2 | 129 909.8 |
| 160×9 | 141 979.5 | 142 290.3 | 133 988.9 | 123 245.0 |
| 170×9 | 158 330.2 | 159 327.2 | 146 520.4 | 135 854.0 |
| 180×9 | 162 768.5 | 163 943.6 | 151 614.8 | 141 274.3 |
| 160×10 | 143 235.6 | 144 221.7 | 135 621.1 | 125 496.7 |
| 170×10 | 152 592.7 | 153 493.5 | 148 342.6 | 139 855.0 |
| 180×10 | 145 698.1 | 145 956.9 | 135 022.7 | 126 678.4 |
| Average | 85 748.4 | 87 305.9 | 82 100.8 | 76 691.4 |
| NB | 0 | 0 | 1 | 27 |
表3 HBICA与3种有效算法的对比结果 |
| 问题规模 | IWOA | HGA | TS | HBICA |
|---|---|---|---|---|
| AVG | AVG | AVG | AVG | |
| 20×4 | 14 268.2 | 14 414.9 | 14 354.4 | 14 199.9 |
| 25×4 | 13 961.2 | 13 862.3 | 14 080.1 | 13 873.7 |
| 30×4 | 26 025.5 | 25 769.6 | 25 820.0 | 25 596.4 |
| 35×5 | 31 076.8 | 30 842.0 | 30 187.0 | 30 053.6 |
| 40×5 | 30 139.5 | 29 559.6 | 28 858.1 | 28 684.1 |
| 45×5 | 39 016.5 | 37 960.4 | 36 910.6 | 36 964.1 |
| 50×5 | 34 448.4 | 33 998.9 | 33 250.6 | 33 051.3 |
| 55×5 | 43 948.9 | 42 758.1 | 41 259.7 | 40 734.6 |
| 60×5 | 38 744.0 | 38 069.4 | 36 709.2 | 36 048.2 |
| 70×6 | 54 328.0 | 52 822.6 | 50 091.9 | 49 980.1 |
| 75×6 | 55 981.9 | 55 393.9 | 51 828.6 | 51 461.8 |
| 80×6 | 65 762.8 | 64 385.1 | 60 943.9 | 61 159.9 |
| 85×6 | 71 195.4 | 69 467.9 | 66 918.4 | 65 691.7 |
| 90×6 | 80 101.6 | 77 252.1 | 73 970.9 | 74 158.8 |
| 95×6 | 89 302.6 | 87 123.2 | 83 528.2 | 82 419.5 |
| 100×7 | 99 500.5 | 99 212.0 | 97 535.8 | 95 075.9 |
| 110×7 | 103 555.3 | 100 595.5 | 96 217.9 | 94 401.1 |
| 120×7 | 103 871.5 | 101 820.3 | 96 041.8 | 92 399.4 |
| 130×8 | 111 969.6 | 110 147.8 | 105 902.3 | 104 564.7 |
| 140×8 | 125 733.7 | 123 363.5 | 118 681.5 | 117 835.0 |
| 150×8 | 142 677.4 | 137 137.8 | 132 839.5 | 129 909.8 |
| 160×9 | 138 169.1 | 131 364.5 | 126 731.4 | 123 245.0 |
| 170×9 | 153 361.2 | 143 737.1 | 143 447.1 | 135 854.0 |
| 180×9 | 158 705.4 | 150 812.5 | 145 711.6 | 141 274.3 |
| 160×10 | 137 840.0 | 132 938.2 | 128 748.5 | 125 496.7 |
| 170×10 | 149 058.4 | 146 947.9 | 142 150.4 | 139 855.0 |
| 180×10 | 141 476.2 | 134 507.9 | 131 902.1 | 126 678.4 |
| Average | 83 489.6 | 80 972.8 | 78 319.3 | 76 691.4 |
| NB | 0 | 1 | 3 | 24 |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
詹文法, 邵志伟. 一种集成电路测试流程分级动态调整方法[J]. 电子学报, 2020, 48(8): 1623-1630.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
何小娟, 曾建潮. 基于Bayesian统计推理的分布估计算法求解柔性作业车间调度问题[J]. 系统工程理论与实践, 2012, 32(2): 380-388.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
姚友杰, 钱斌, 董钰明, 等. 基于EDA的绿色零等待作业车间调度问题求解[J]. 电子学报, 2021, 49(2): 225-232.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
杨晓林, 胡蓉, 钱斌, 等. 增强分布估计算法求解低碳分布式流水线调度[J]. 控制理论与应用, 2019, 36(5): 803-815.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
李明, 雷德明. 基于新型帝国竞争算法的高维多目标柔性作业车间调度[J]. 控制理论与应用, 2019, 36(6): 893-901.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
裴小兵, 于秀燕, 王尚磊. 混合帝国竞争算法求解旅行商问题[J]. 浙江大学学报(工学版), 2019, 53(10): 2003-2012.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(1027 KB)
PDF(1027 KB)
 表1 符号表
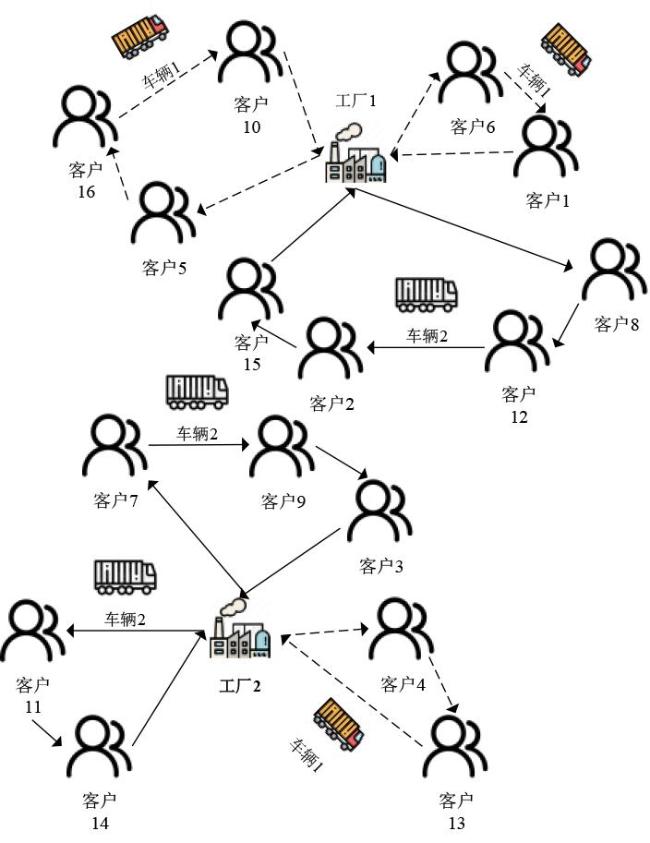
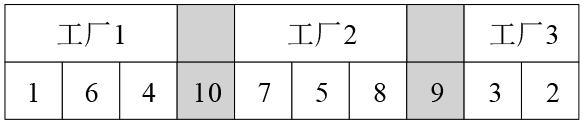
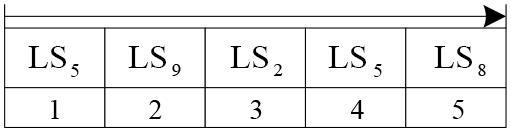
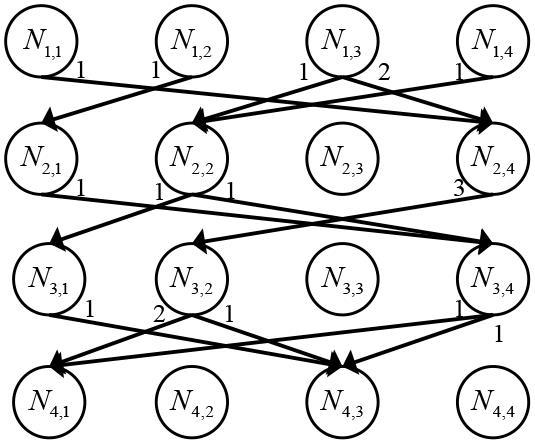
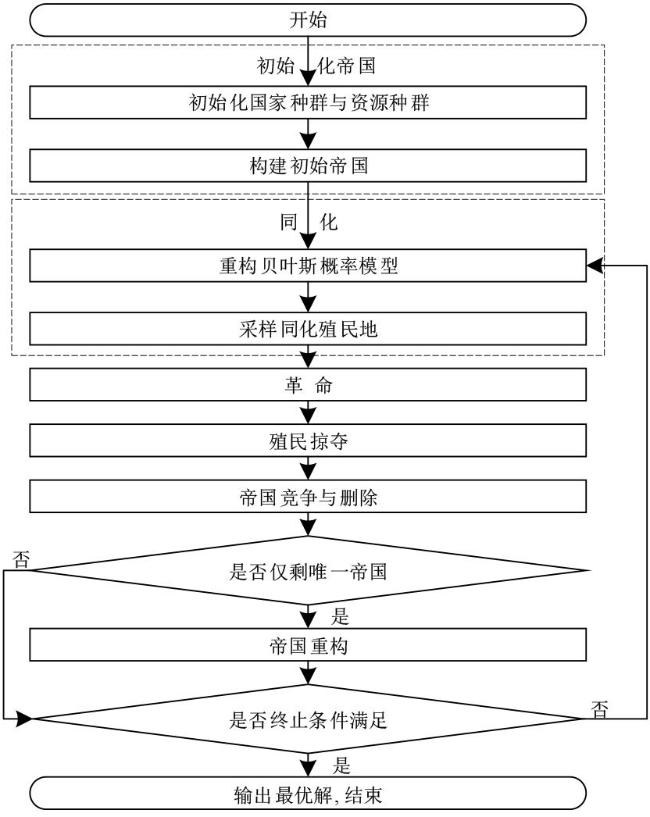
表1 符号表 图1 MFISP_MTBD示意图图2 编码示意图图3 资源个体示意图图4 精英国家贝叶斯网络图图5 HBICA流程图表2 ICA、ED_ICA、B_ICA与HBICA的有效性对比结果表3 HBICA与3种有效算法的对比结果
图1 MFISP_MTBD示意图图2 编码示意图图3 资源个体示意图图4 精英国家贝叶斯网络图图5 HBICA流程图表2 ICA、ED_ICA、B_ICA与HBICA的有效性对比结果表3 HBICA与3种有效算法的对比结果

/
| 〈 |
|
〉 |










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}