 PDF(1780 KB)
PDF(1780 KB)
 PDF(1780 KB)
PDF(1780 KB)
PDF(1780 KB)
PDF(1780 KB)
基于金字塔块匹配的双目场景流估计
Binocular Scene Flow Estimation Based on Pyramid Block Matching
针对现有双目场景流计算方法在大位移、运动遮挡及光照变化等复杂场景下场景流估计的准确性与鲁棒性问题,提出一种基于金字塔块匹配的双目场景流计算方法.首先对双目图像序列进行超像素分割和视差估计,得到图像初始分割结果和视差信息,然后建立基于金字塔块匹配的运动模型并采用Ransac随机一致性算法拟合刚性运动模型和最小化重投影算法估计对象运动参数.最后,本文将金字塔块匹配结果作为约束项,联合对象运动参数和超像素平面参数构建基于金字塔块匹配的双目场景流估计能量函数模型,通过最小化能量函数得到最终场景流.实验分别采用KITTI2015(Karlsruhe Institute of Technology and Toyota technological Institute 2015)和MPI-Sintel(Max-Planck Institute and Sintel)数据集测试图像对本文方法和具有代表性场景流算法进行综合对比分析,结果表明本文方法相对于其他对比方法有效提高大位移、运动遮挡以及光照变化情况下场景流估计精度和鲁棒性.
Aiming at the accuracy and robustness of existing binocular scene flow calculation methods in complex scenes such as large displacement, motion occlusion and illumination changes, this paper proposes a binocular scene flow estimation method based on pyramid block matching. Firstly, we apply the superpixel segmentation and disparity estimation to the binocular image sequence to obtain the initial image segmentation results and disparity information. Secondly, we establish a motion model based on pyramid block matching. Then we fit the rigid motion model by using Ransac stochastic consensus algorithm and estimate the object motion parameters by minimizing the reprojection algorithm. Finally, this paper takes the matching result of the pyramid block as a constraint item, then we construct a binocular scene flow estimation energy function model based on the pyramid block matching by combines the object motion parameters and the superpixel plane parameters, and obtains the final scene flow by minimizing the energy function. The image sequences provided by the KITTI2015(Karlsruhe Institute of Technology and Toyota Technological Institute 2015) and MPI-Sintel(Max-Planck Institute and Sintel) databases were adopted to compare and analyze the proposed method in this paper and the existing representative scene flow method. The experimental results show that compared with other comparison methods, the method in this paper has high accuracy and robustness of scene flow estimatin, especially in large displacement, motion occlusion and lighting changes.
双目场景流 / 金字塔块匹配 / 运动模型 / 大位移运动 / 超像素分割 {{custom_keyword}} /
binocular scene flow / pyramid block matching / motion model / large displacement motion / superpixel segmentation {{custom_keyword}} /
表1 KITTI2015数据集场景流估计误差结果统计(异常值百分比) |
| 类型 | 对比方法 | D1-bg | D1-fg | D1-all | Fl-bg | Fl-fg | Fl-all | SF-bg | SF-fg | SF-all |
|---|---|---|---|---|---|---|---|---|---|---|
| 深度学习方法 | SE[9] | 1.48 | 3.46 | 1.81 | 5.83 | 8.66 | 6.30 | 7.06 | 13.44 | 8.12 |
| PWOC-3D[10] | 4.19 | 9.82 | 5.13 | 12.40 | 15.78 | 12.96 | 14.30 | 22.66 | 15.69 | |
| SENSE[8] | 2.07 | 3.01 | 2.22 | 7.30 | 9.33 | 7.64 | 8.36 | 15.49 | 9.55 | |
| Self_Mono[11] | 20.72 | 29.41 | 22.16 | 15.51 | 17.96 | 15.91 | 31.51 | 45.77 | 33.88 | |
| 传统方法 | SSF[7] | 3.55 | 8.75 | 4.42 | 5.63 | 14.71 | 7.14 | 7.18 | 24.58 | 10.07 |
| OSF[5] | 4.54 | 12.03 | 5.79 | 5.62 | 18.92 | 7.83 | 7.01 | 26.34 | 10.23 | |
| SFF[6] | 5.12 | 13.83 | 6.57 | 10.58 | 24.41 | 12.88 | 12.48 | 32.28 | 15.78 | |
| FSF+MS[13] | 5.72 | 11.84 | 6.74 | 8.48 | 25.43 | 11.30 | 11.17 | 33.91 | 14.96 | |
| PRSF[14] | 4.74 | 13.74 | 6.24 | 11.73 | 24.33 | 13.83 | 13.49 | 31.22 | 16.44 | |
| 本文方法 | 3.25 | 9.11 | 4.22 | 5.02 | 15.23 | 6.72 | 6.15 | 21.48 | 8.70 |
表2 本文方法与对比方法场景流误差估计结果统计(异常值百分比) |
| 场景 | 序列 | SSF[7] | OSF[5] | SE[9] | 本文方法 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| D1 | D2 | Fl | SF | D1 | D2 | Fl | SF | D1 | D2 | Fl | SF | D1 | D2 | Fl | SF | ||
| 大位移 | 04 | 4.70 | 8.81 | 7.82 | 11.65 | 3.28 | 10.65 | 14.91 | 15.15 | 2.08 | 3.18 | 6.06 | 8.00 | 2.16 | 2.76 | 4.61 | 4.83 |
| 17 | 2.73 | 4.49 | 7.31 | 8.54 | 2.44 | 3.61 | 6.55 | 7.24 | 0.69 | 1.98 | 4.83 | 5.62 | 1.85 | 3.06 | 5.92 | 6.35 | |
| 运动遮挡 | 07 | 5.13 | 5.11 | 20.66 | 22.93 | 4.53 | 4.55 | 13.07 | 15.36 | 1.00 | 1.00 | 4.84 | 5.28 | 3.54 | 3.51 | 3.10 | 4.74 |
| 18 | 9.28 | 52.55 | 54.99 | 55.78 | 8.84 | 53.63 | 54.91 | 55.68 | 3.32 | 50.26 | 56.16 | 57.11 | 5.95 | 52.69 | 54.22 | 54.64 | |
| 光照变化 | 02 | 3.76 | 4.01 | 3.92 | 4.91 | 4.24 | 4.45 | 3.75 | 4.93 | 1.89 | 4.56 | 6.61 | 8.32 | 3.27 | 3.61 | 3.48 | 4.07 |
| 03 | 7.28 | 12.02 | 15.66 | 16.60 | 9.89 | 14.75 | 16.49 | 17.32 | 1.48 | 3.93 | 6.45 | 10.37 | 5.01 | 6.72 | 11.16 | 11.81 | |
表3 MPI⁃Sintel 数据集光流误差结果统计(异常值百分比) |
| 场景 | 图像序列 | PRSF[14] | OSF[5] | FSF+MS[13] | SFF[6] | SS-SF[16] | SE[9] | 本文方法 |
|---|---|---|---|---|---|---|---|---|
| 大位移 | market_2 | 5.81 | 10.08 | 5.17 | 7.11 | 5.79 | 6.06 | 5.58 |
| ambush_4 | 48.60 | 49.16 | 45.23 | 60.03 | 48.55 | 54.34 | 39.23 | |
| ambush_6 | 49.77 | 54.75 | 44.05 | 57.06 | 49.37 | 59.45 | 36.88 | |
| 平均值 | 34.73 | 38.00 | 31.48 | 41.40 | 34.57 | 39.95 | 27.23 | |
| 运动 遮挡 | temple_2 | 12.61 | 10.52 | 9.66 | 29.58 | 12.57 | 13.70 | 6.88 |
| ambush_2 | 66.22 | 87.37 | 72.68 | 90.92 | 66.33 | 76.19 | 40.39 | |
| bamboo_2 | 5.05 | 4.86 | 3.65 | 5.84 | 5.06 | 6.33 | 4.53 | |
| 平均值 | 27.96 | 34.25 | 28.66 | 42.11 | 27.99 | 32.07 | 17.27 | |
| 光照 变化 | market_5 | 41.33 | 29.58 | 26.31 | 40.77 | 41.36 | 39.83 | 23.48 |
| alley_2 | 1.62 | 1.44 | 1.20 | 2.85 | 1.61 | 1.71 | 1.19 | |
| market_6 | 22.84 | 16.39 | 13.13 | 28.92 | 22.87 | 16.97 | 10.27 | |
| 平均值 | 21.93 | 15.80 | 13.55 | 24.18 | 21.95 | 19.50 | 11.65 |
| 1 |
常侃, 张智勇, 陈诚, 等. 采用低秩与加权稀疏分解的视频前景检测算法[J]. 电子学报, 2017, 45(9): 2272-2280.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
谢佳龙, 张波涛, 吕强. 一种基于双流融合3D卷积神经网络的动态头势识别方法[J]. 电子学报, 2021, 49(7): 1363-1369.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
王伟, 于磊, 任国恒, 等. 城市建筑立面三维"线-面"结构快速重建[J]. 电子学报, 2021, 49(8): 1551-1560.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
张聪炫, 裴刘继, 陈震, 等. FRFCM聚类与深度优化的RGBD场景流计算[J]. 电子学报, 2020, 48(7): 1380-1386.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
HUR J,
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
陈震, 马龙, 张聪炫, 等. 基于语义分割的双目场景流估计[J]. 电子学报, 2020, 48(4): 631-636.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(1780 KB)
PDF(1780 KB)
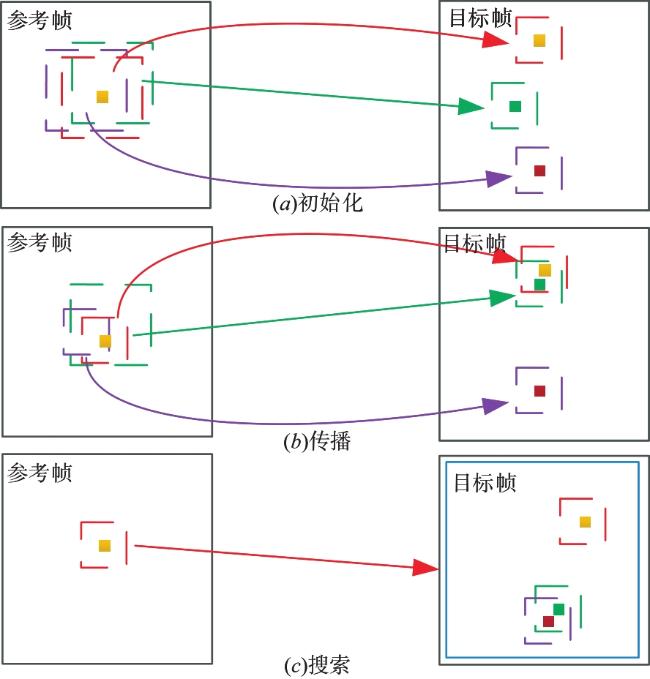
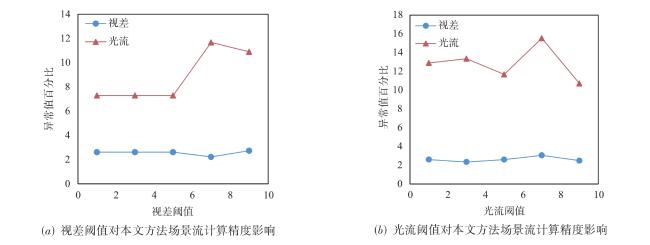
 图1 金字塔块匹配计算步骤图2 不同参数设置对本文场景流估计精度的影响
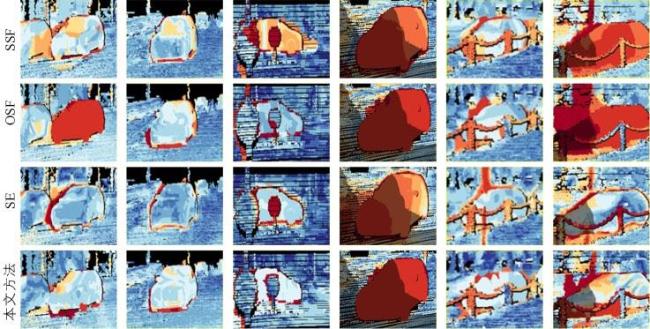
图1 金字塔块匹配计算步骤图2 不同参数设置对本文场景流估计精度的影响 表1 KITTI2015数据集场景流估计误差结果统计(异常值百分比)表2 本文方法与对比方法场景流误差估计结果统计(异常值百分比)图3 本文方法与对比方法场景流估计误差图图4 标签区域局部放大图表3 MPI⁃Sintel 数据集光流误差结果统计(异常值百分比)
表1 KITTI2015数据集场景流估计误差结果统计(异常值百分比)表2 本文方法与对比方法场景流误差估计结果统计(异常值百分比)图3 本文方法与对比方法场景流估计误差图图4 标签区域局部放大图表3 MPI⁃Sintel 数据集光流误差结果统计(异常值百分比)

/
| 〈 |
|
〉 |











{kind=link}
{kind=link}
{kind=link}
{kind=link}