 PDF(3356 KB)
PDF(3356 KB)
 PDF(3356 KB)
PDF(3356 KB)
PDF(3356 KB)
PDF(3356 KB)
基于局部异构聚合图卷积网络的跨模态行人重识别
Cross-Modality Person Re-identification Based on Locally Heterogeneous Polymerization Graph Convolutional Network
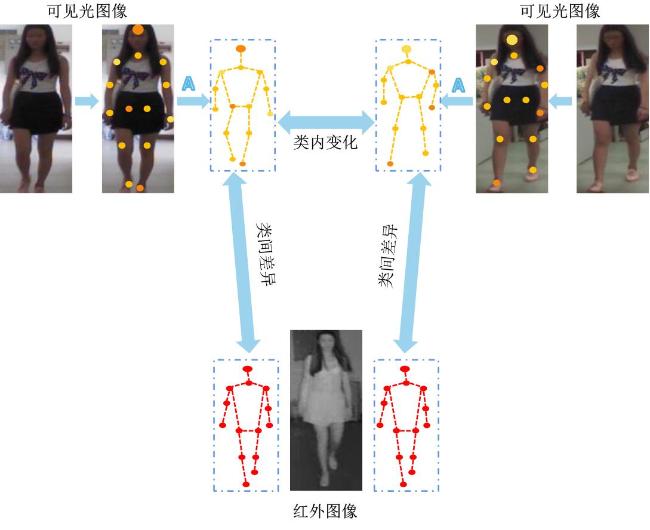
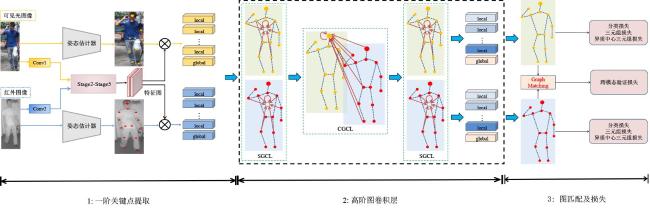
由于构建全天候视频监控系统的需要,基于可见光与红外的跨模态行人重识别问题受到学术界的广泛关注.因为类内变化和类间差异的影响,可见光与红外行人重识别是一项具有挑战性的任务.现有的工作主要集中在可见光-红外图像转换或跨模态的全局共享特征学习,而身体部位的局部特征和这些特征之间的结构关系在很大程度上被忽略了.我们认为局部关键点之间的图结构关系在模态内与模态间的变化是相对稳定的,充分挖掘与表示这种结构信息有助于解决跨模态行人重识别问题.本文提出了一种基于局部异构聚合图卷积网络的跨模态行人重识别方法,采用关键点提取网络提取图像的局部关键点特征,并构建了一种新颖的图卷积网络建模人体各部位之间的结构关系.该网络通过图内卷积层表征局部特征的高阶结构关系信息,提取具有辨别力的局部特征.网络中的跨图卷积层使两个异构图结构之间可以传递差异性特征,有助于减弱模态差异的影响.针对异构图结构的图匹配问题,设计了一种跨模态排列损失以更好地测度图结构的距离.本文方法在主流跨模态数据集RegDB和SYSU-MM01上的mAP/Rank-1为80.78%/80.55%和67.92%/66.49%,比VDCM算法的Rank-1分数高出7.58%和1.87%.
The research of cross-modality person re-identification based on visible-infrared has attracted widespread attention from the academia due to the need to build an all-day video surveillance system. Visible-infrared person re-identification is a challenging task due to intra-class variation and cross-modality discrepancy. Existing work focused on visible-infrared modal transformations or global shared feature learning across modalities, while local features of body parts and the structural relationships between these features have been largely ignored. We consider that the graph structure relationship between local key-points is relatively stable within and between modality variations, and fully mining and representing this structural information can help solve the cross-modal person re-identification problem. Therefore, this paper proposes a cross-modal person re-identification method based on local heterogeneous polymerization graph convolutional networks. A key-points extraction network is used to extract the local key-points' features of the image, and then a novel graph convolutional network is constructed to model the structural relationships between various parts of the human body. The network characterizes the higher-order structural relationship information of local features through the intra-graph convolutional layer, and finally extracts discriminative local features. The cross-graph convolutional layer in the network enables the transfer of discriminative features between two heterogeneous graph structures, which helps to reduce the effect of modal differences. Finally, a cross-modality permutation loss is designed to better measure the distance of graph structures for the graph matching problem of heterogeneous graph structures. The mAP/Rank-1 of our method on the mainstream cross-modal datasets RegDB and SYSU-MM01 is 80.78%/80.55% and 67.92%/66.49%, which is 7.58% and 1.87% higher than the Rank-1 scores of the VDCM algorithm.
行人重识别 / 跨模态 / 异构聚合 / 图卷积网络 / 关键点提取网络 {{custom_keyword}} /
person re-identification / cross-modality / hetero-polymerization / graph convolutional network / key-points extraction network {{custom_keyword}} /
| 算法1 图内卷积层(SGCL) |
|---|
| Input: key-points features resnet feature maps 1. //Initialization: A adap as zero matrix; A lim as pre-defined adjacent matrix A; 2. 3. for 4. 5. 6. 7. V←( 8. Output: fusion features{ |
| 算法2 跨图卷积层(CGCL) |
|---|
| Input: ( 1. //initialization: U ( K +1)×( K +1) as zero matrix; 2. U ←0 ( K +1)×( K +1); 3. //build U from { 4. 5. U ←GM{ 6. 7. 8. 9. Output: { |
表1 各方法在RegDB数据集上的实验结果对比 (%) |
| 方法 | Visible to Thermal | Thermal to Visible | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Rank-1 | Rank-10 | Rank-20 | mAP | mINP | Rank-1 | Rank-10 | Rank-20 | mAP | mINP | |
| BDTR[17](TIFS 19) | 33.56 | 58.61 | 67.43 | 32.76 | — | 32.92 | 58.46 | 68.43 | 31.96 | — |
| eBDTR[17](AAAI 19) | 34.62 | 58.96 | 68.72 | 33.46 | — | 34.21 | 58.74 | 68.64 | 32.49 | — |
| D2RL[16](CVPR 19) | 43.40 | 66.10 | 76.30 | 44.10 | — | — | — | — | — | — |
| AlignGAN[20](ICCV 19) | 57.90 | — | — | 53.60 | — | 56.30 | — | — | 53.40 | — |
| Xmodal[52](AAAI 20) | 62.21 | 83.13 | 91.72 | 60.18 | — | — | — | — | — | — |
| DDAG[53](ECCV 20) | 69.34 | 86.19 | 91.49 | 63.46 | — | 68.06 | 85.15 | 90.31 | 61.80 | — |
| AGW[2](TPAMI 21) | 70.05 | — | — | 66.37 | 50.19 | 70.49 | 87.12 | 91.84 | 65.90 | 51.24 |
| LbA[54](ICCV 21) | 74.17 | 87.66 | — | 67.64 | — | 72.43 | 87.37 | — | 65.46 | — |
| VDCM[56](CVPR 21) | 73.20 | — | — | 71.60 | — | 71.80 | — | — | 70.10 | — |
| CAFM[15](IEEESPL 21) | 78.62 | 91.63 | 96.32 | 71.30 | — | — | — | — | — | — |
| MCLNet[55](ICCV 21) | 80.31 | 92.70 | 96.03 | 73.07 | 57.39 | 75.93 | 90.93 | 94.59 | 69.49 | 52.63 |
| MPANet[57](CVPR 21) | 79.27 | 98.79 | 99.81 | 77.61 | — | 79.03 | 99.22 | 100.00 | 77.45 | — |
| 本文方法 | 80.78 | 94.89 | 97.60 | 80.55 | 65.76 | 80.48 | 90.33 | 94.80 | 79.26 | 61.90 |
表2 各方法在SYSU-MM01数据集上的实验结果对比 (%) |
| 方法 | All-Search | Indoor-Search | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Rank-1 | Rank-10 | Rank-20 | mAP | mINP | Rank-1 | Rank-10 | Rank-20 | mAP | mINP | |
| BDTR[17](TIFS 19) | 27.32 | 66.96 | 81.07 | 27.32 | — | 31.92 | 77.18 | 89.28 | 41.86 | — |
| D2RL[16](CVPR 19) | 28.90 | 70.60 | 82.40 | 29.20 | — | — | — | — | — | — |
| AlignGAN[20](ICCV 19) | 42.40 | 85.00 | 93.70 | 40.70 | — | 45.90 | 87.60 | 94.40 | 54.30 | — |
| Xmodal[52](AAAI 20) | 49.92 | 89.79 | 95.96 | 50.73 | — | — | — | — | — | — |
| AGW[2](TPAMI 21) | 47.50 | 84.39 | 92.14 | 47.65 | 35.30 | 54.17 | 91.14 | 95.98 | 62.97 | 59.23 |
| DDAG[53](ECCV 20) | 54.75 | 90.39 | 95.81 | 53.02 | — | 61.20 | 94.06 | 98.41 | 67.98 | — |
| CAFM[15](IEEESPL 21) | 55.23 | 90.21 | 95.66 | 52.57 | — | 61.26 | 94.19 | 98.24 | 67.94 | — |
| LbA[54](ICCV 21) | 55.41 | 91.12 | — | 54.14 | — | 58.46 | 94.13 | — | 66.33 | — |
| VDCM[56](CVPR 21) | 60.02 | 94.18 | 98.14 | 58.80 | — | 66.05 | 96.59 | 99.38 | 72.98 | — |
| MCLNet[55](ICCV 21) | 65.40 | 93.33 | 97.14 | 61.98 | 47.39 | 72.56 | 96.98 | 99.20 | 76.58 | 72.10 |
| MPANet[57](CVPR 21) | 70.28 | 96.02 | 98.73 | 57.21 | — | 75.34 | 97.87 | 99.05 | 67.85 | — |
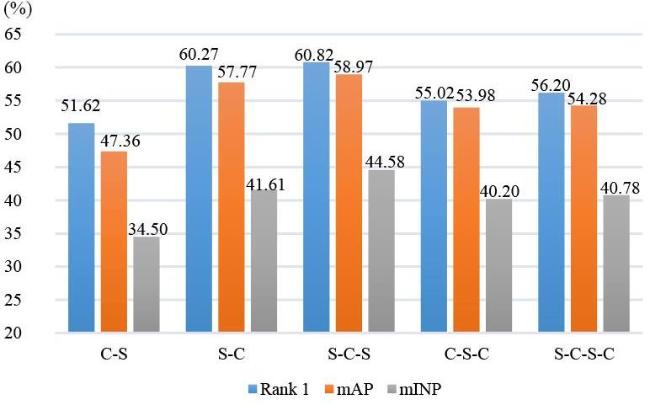
| 本文方法 | 60.82 | 94.36 | 98.88 | 58.97 | 44.58 | 67.92 | 97.01 | 99.34 | 66.49 | 62.92 |
表3 RegDB数据集上7种不同设定的消融研究 |
| Index | Settings | V to T | T to V | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Base | KE | SGCL1 | CGCL | SGCL2 | GM | Rank-1/% | mAP/% | Rank-1/% | mAP/% | |
| 1 | √ | × | × | × | × | × | 70.67 | 66.80 | 69.79 | 63.54 |
| 2 | √ | √ | × | × | × | × | 75.84 | 73.12 | 74.92 | 72.35 |
| 3 | √ | √ | √ | × | × | × | 77.64 | 76.73 | 77.33 | 75.89 |
| 4 | √ | √ | × | √ | × | × | 77.82 | 75.44 | 76.87 | 74.18 |
| 5 | √ | √ | √ | √ | × | × | 79.56 | 79.05 | 79.28 | 77.72 |
| 6 | √ | √ | √ | √ | √ | × | 80.28 | 79.97 | 80.01 | 78.65 |
| 7 | √ | √ | √ | √ | √ | √ | 80.78 | 80.55 | 80.48 | 79.26 |
表4 分析不同的组件对性能的影响 |
| Index | CONF | NORM | SGCL | CGCL | Rank-1/% | mAP/% |
|---|---|---|---|---|---|---|
| 1 | × | × | √ | √ | 77.87 | 76.76 |
| 2 | √ | × | √ | √ | 79.49 | 79.38 |
| 3 | √ | √ | × | √ | 78.98 | 76.94 |
| 4 | √ | √ | √ | × | 78.30 | 78.23 |
| 5 | √ | √ | √ | √ | 80.78 | 80.55 |
| 1 |
罗浩, 姜伟, 范星, 等. 基于深度学习的行人重识别研究进展[J]. 自动化学报, 2019, 45(11): 2032-2049.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 24 |
孙锐, 张磊, 余益衡, 等. 一种基于异构融合图卷积网络的跨模态行人重识别方法: CN113989851A[P]. 2022-01-28.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 25 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 26 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 27 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 28 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 29 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 30 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 31 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 32 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 33 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 34 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 35 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 36 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 37 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 38 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 39 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 40 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 41 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 42 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 43 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 44 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 45 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 46 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 47 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 48 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 49 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 50 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 51 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 52 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 53 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 54 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 55 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 56 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 57 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(3356 KB)
PDF(3356 KB)
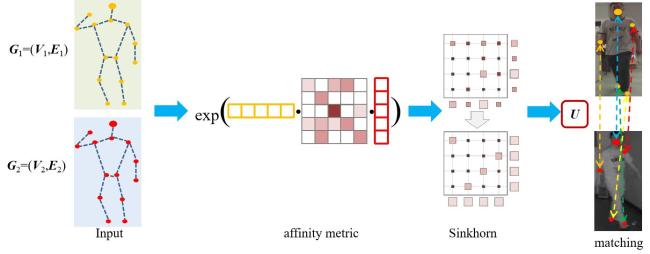
 图1 类内变化和类间差异的图示图2 本文方法网络框图图3 在跨模态数据集中姿态估计网络的可视化结果
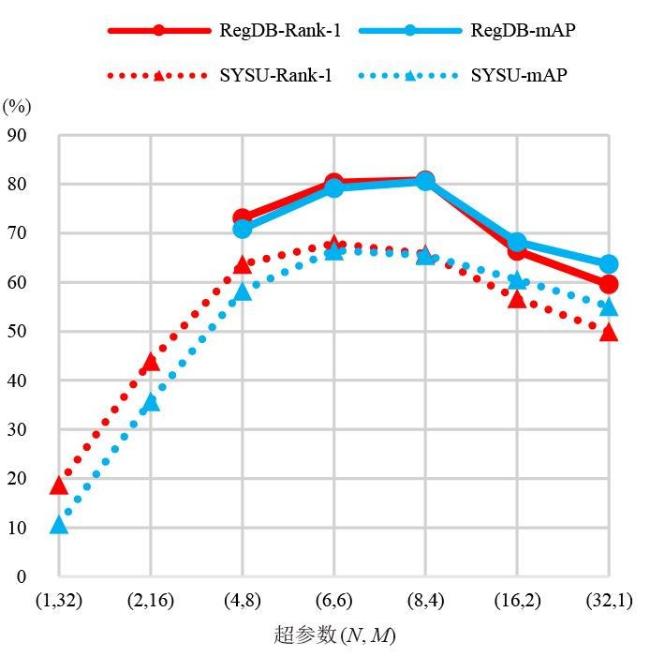
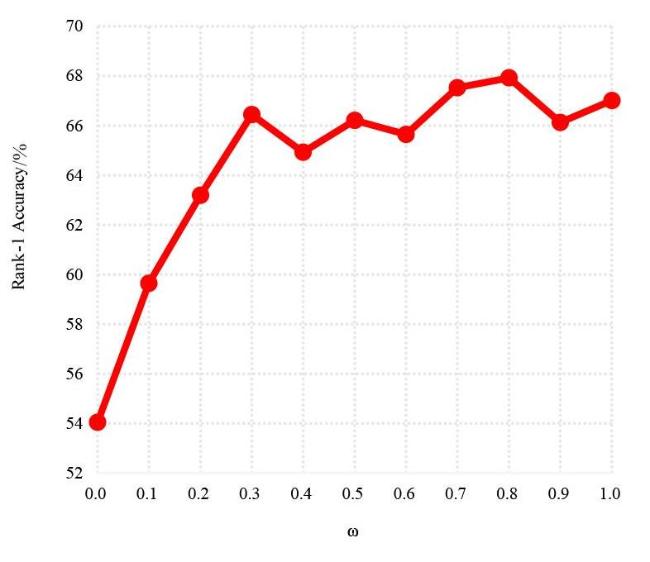
图1 类内变化和类间差异的图示图2 本文方法网络框图图3 在跨模态数据集中姿态估计网络的可视化结果 图4 图匹配算法图5 RegDB和SYSU-MM01数据集中的示例图像表1 各方法在RegDB数据集上的实验结果对比 (%)表2 各方法在SYSU-MM01数据集上的实验结果对比 (%)表3 RegDB数据集上7种不同设定的消融研究表4 分析不同的组件对性能的影响图6 在SYSU-MM01全局搜索模式下,分析不同图卷积模式的性能图7 在RegDB、SYSU-MM01数据集上超参数N和M对模型性能的影响图8 在SYSU-MM01室内搜索模式下分析超参数ω图9 本文方法检索结果的可视化
图4 图匹配算法图5 RegDB和SYSU-MM01数据集中的示例图像表1 各方法在RegDB数据集上的实验结果对比 (%)表2 各方法在SYSU-MM01数据集上的实验结果对比 (%)表3 RegDB数据集上7种不同设定的消融研究表4 分析不同的组件对性能的影响图6 在SYSU-MM01全局搜索模式下,分析不同图卷积模式的性能图7 在RegDB、SYSU-MM01数据集上超参数N和M对模型性能的影响图8 在SYSU-MM01室内搜索模式下分析超参数ω图9 本文方法检索结果的可视化

/
| 〈 |
|
〉 |












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}