 PDF(1549 KB)
PDF(1549 KB)
 PDF(1549 KB)
PDF(1549 KB)
PDF(1549 KB)
PDF(1549 KB)
基于类别扩展的广义零样本图像分类方法
Category Expansion Based Generalized Zero-Shot Image Classification
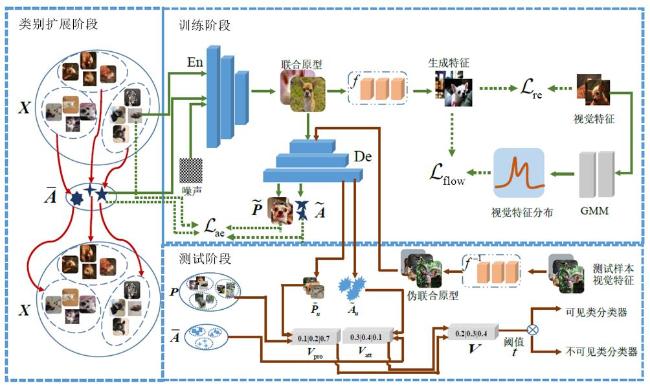
在传统的零样本图像分类方法中,语义属性通常被用作辅助信息来描述各类别的视觉特征.然而,单一的语义属性并不能对类内多样性的视觉特征进行全面的描述.为提高语义属性对类别内部多样性的表示能力,同时也为了帮助模型提高对各类别的描述能力,本文通过属性自编码器的方式在视觉以及语义空间上对类别进行扩展.此外,为了缓解传统生成性方法因无法直接计算生成空间到真实空间的变换而带来的模型次优解问题,本文采用了生成流网络作为基础网络,通过可逆变换直接计算两个空间之间的变换来开展对零样本学习任务的研究.本文使用解码器网络将逆生成流网络为测试样本生成的原型特征解耦成视觉原型及语义原型信息,然后根据这两个原型信息实现将测试样本预分类到可见类集或不可见类集中,最终在这两个子分类空间中根据样本的特点分别进行监督分类和零样本分类任务以提高模型的整体性能表现.本文在五个数据集上通过大量的实验验证了本文所提方法的有效性.
In traditional zero-shot image classification methods, semantic attributes are usually used as auxiliary information to describe the visual features of each class. However, a single semantic attribute cannot fully describe the diverse visual features within a single class. To improve the ability of semantic attributes to express the diversity within the class, and to help the model improve the description ability for each category, we use the semantic auto-encoder to expand the categories in visual and semantic space. In addition, to alleviate the suboptimal solution problem of the model caused by the inability to directly calculate the transformation from the generation space to the real space by the traditional generative methods, we employ the generative flow as the basic network in this paper to directly calculate the transformation between the two spaces. Furthermore, we exploit the decoder network to decouple the prototype features generated by the inverse generative flow network for the test samples into visual prototypes and semantic prototypes, and then realize the pre-classification of the test samples into seen or unseen classes. Finally, in the two sub-classification domains, supervised classification and zero-shot classification are performed separately to improve the overall performance. Extensive experiments are conducted on five popular datasets to verify the effectiveness of the proposed method.
生成流 / 预分类 / 广义零样本学习 / 类扩展 {{custom_keyword}} /
generative flow / pre-classification / generalized zero-shot learning / category expansion {{custom_keyword}} /
表1 各数据集在 |
| 数据集 | 语义/视觉维度 | 训练样例数量 | 可见/不可见测试样例 | 可见/不可见类别 | 属性标注方式 |
|---|---|---|---|---|---|
| AWA1 | 85/2048 | 19 832 | 5 685/4 958 | 40/10 | 专家标注 |
| AWA2 | 85/2048 | 23 527 | 5 882/7 913 | 40/10 | 专家标注 |
| CUB | 312/2048 | 7 057 | 1 440/2 580 | 150/50 | 专家标注 |
| SUN | 102/2048 | 10 320 | 7 924/1 483 | 645/102 | 专家标注 |
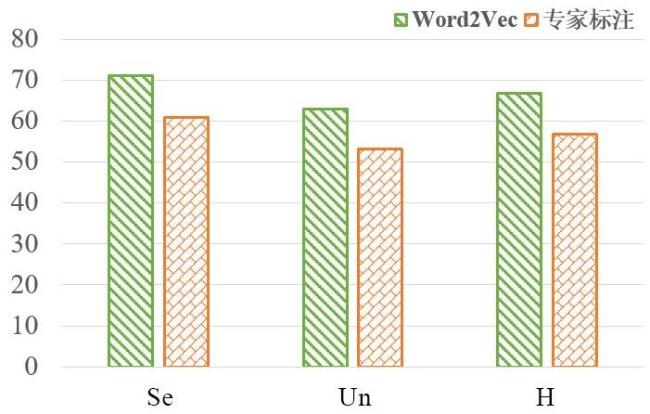
| FLO | 1 024/2048 | 5 631 | 1 403/1 155 | 82/20 | Word2Vec |
表2 在AWA1,AWA2,CUB,SUN与FLO数据集上的广义零样本分类表现 |
| 方法 | 数据集 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AWA1 | AWA2 | CUB | SUN | FLO | |||||||||||
| Se | Un | H | Se | Un | H | Se | Un | H | Se | Un | H | Se | Un | H | |
| CLSWGAN[18] | 57.9 | 61.4 | 59.6 | — | — | — | 43.7 | 57.7 | 49.7 | 42.6 | 36.6 | 39.4 | 59.0 | 73.8 | 65.6 |
| DUET[38] | 90.1 | 47.5 | 62.2 | 90.2 | 48.2 | 63.4 | 80.1 | 39.7 | 53.1 | — | — | — | — | — | — |
| COSMO[27] | 80.0 | 52.8 | 63.6 | — | — | — | 87.8 | 44.4 | 50.2 | 37.7 | 44.9 | 41.0 | 81.4 | 59.6 | 68.8 |
| RFF-GZSL[39] | 75.1 | 59.8 | 66.5 | — | — | — | 56.6 | 52.6 | 54.6 | 38.6 | 45.7 | 41.9 | 78.2 | 65.2 | 71.1 |
| LsrGAN[40] | 74.6 | 54.6 | 63.0 | — | — | — | 59.1 | 48.1 | 53.0 | 37.7 | 44.8 | 40.9 | — | — | — |
| DRN[41] | 81.4 | 50.1 | 62.1 | 85.3 | 44.9 | 58.8 | 58.8 | 46.9 | 52.2 | — | — | — | — | — | — |
| OBTL[42] | — | — | — | 73.4 | 59.5 | 65.7 | 59.9 | 44.8 | 51.3 | 42.9 | 44.8 | 43.8 | — | — | — |
| IZF-NBC[14] | 75.2 | 57.8 | 65.4 | 76.0 | 58.1 | 65.9 | 56.3 | 44.2 | 49.5 | 50.6 | 44.5 | 47.4 | — | — | — |
| GZSL-DR[43] | 72.9 | 60.7 | 66.2 | 80.2 | 56.9 | 66.6 | 58.2 | 51.1 | 54.4 | 47.6 | 36.6 | 41.4 | — | — | — |
| CEBGZSL | 75.0 | 62.6 | 68.2 | 78.3 | 61.2 | 68.7 | 60.9 | 53.3 | 56.9 | 44.6 | 56.3 | 49.7 | 90.6 | 61.3 | 73.2 |
表3 各模块对模型分类性能的影响 |
| 消融模块 | 数据集 | |||||
|---|---|---|---|---|---|---|
| AWA2 | CUB | |||||
| Se | Un | H | Se | Un | H | |
| | 78.29 | 61.21 | 68.71 | 60.89 | 53.32 | 56.85 |
| w\o | 66.66 | 50.37 | 57.38 | 54.07 | 47.49 | 50.56 |
| w\o | 65.99 | 56.05 | 60.61 | 54.53 | 49.65 | 51.98 |
| w\o | 58.06 | 42.04 | 48.77 | 47.20 | 44.43 | 45.78 |
表4 类别扩展前在语义属性空间上的有效性分析 |
| 数据集 | 扩展前 | 扩展后(V1) | 扩展后(V2) |
|---|---|---|---|
| AWA2 | 53.08 | 39.97 | 39.98 |
| CUB | 40.36 | 30.37 | 30.39 |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
程玉虎, 乔雪, 王雪松. 基于混合属性的零样本图像分类[J]. 电子学报, 2017, 45(6): 1462-1468.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
赵鹏, 汪纯燕, 张思颖, 等. 一种基于融合重构的子空间学习的零样本图像分类方法[J]. 计算机学报, 2021, 44(2): 409-421.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
冀中, 汪浩然, 于云龙, 等. 零样本图像分类综述: 十年进展[J]. 中国科学: 信息科学, 2019, 49(10): 1299-1320.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
王格格, 郭涛, 余游, 等. 基于生成对抗网络的无监督域适应分类模型[J]. 电子学报, 2020, 48(6): 1190-1197.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 24 |
席亮, 刘涵, 樊好义, 等. 基于深度对抗学习潜在表示分布的异常检测模型[J]. 电子学报, 2021, 49(7): 1257-1265.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 25 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 26 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 27 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 28 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 29 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 30 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 31 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 32 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 33 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 34 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 35 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 36 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 37 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 38 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 39 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 40 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 41 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 42 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 43 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(1549 KB)
PDF(1549 KB)
 图1 基于类别扩展的泛化零样本学习方法流程图
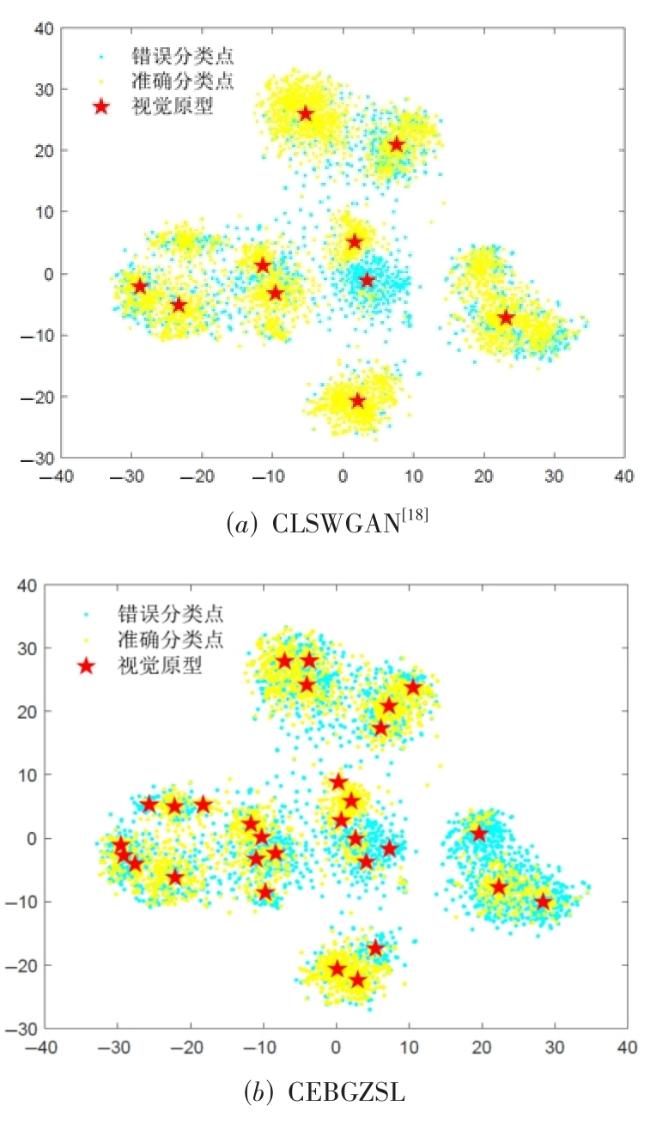
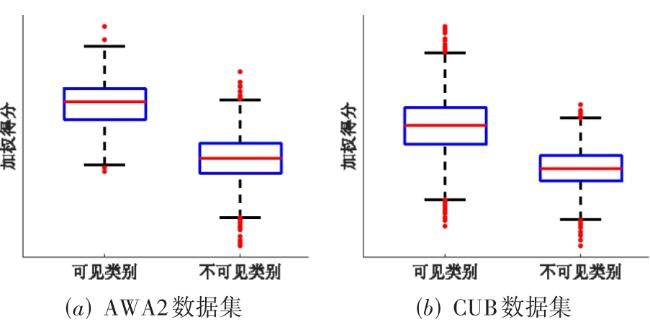
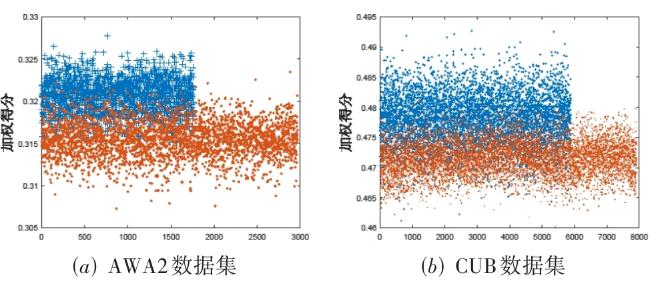
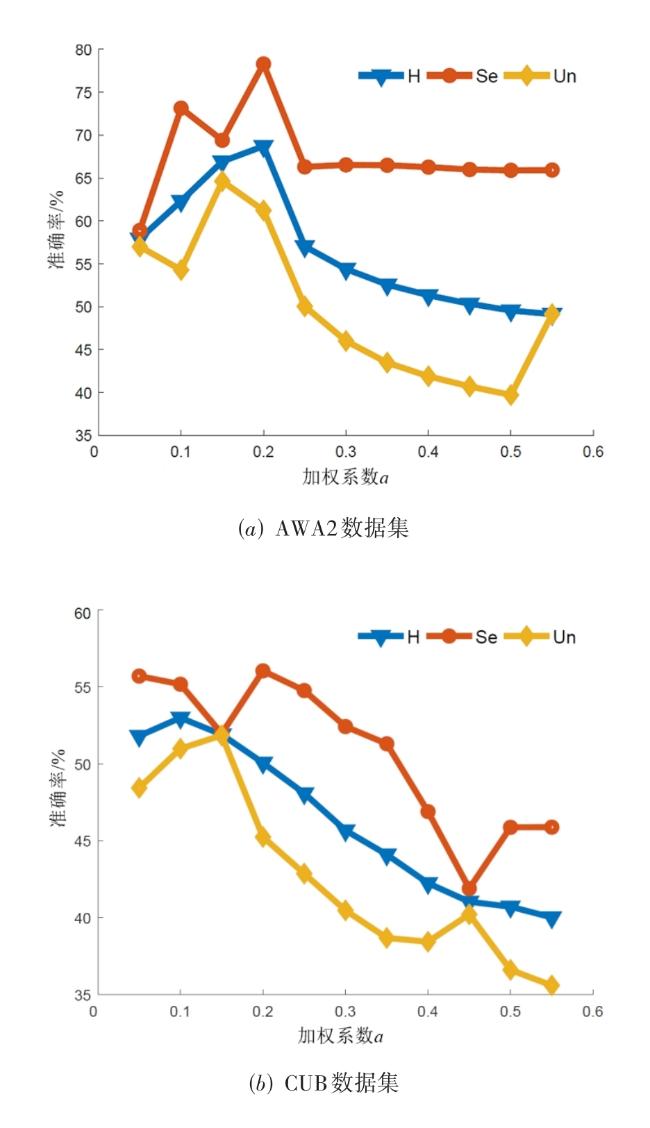
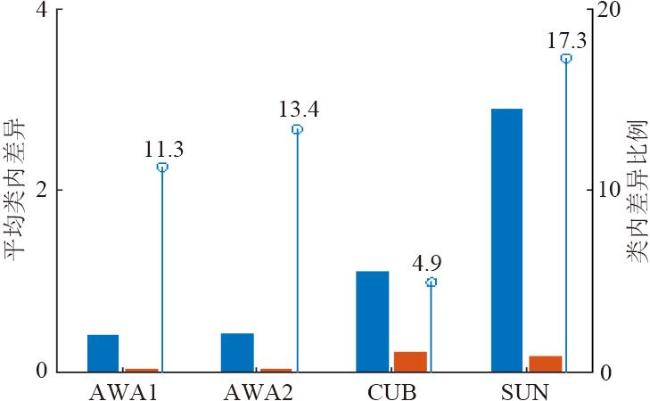
图1 基于类别扩展的泛化零样本学习方法流程图 表1 各数据集在 P S划分方式下的详细信息表2 在AWA1,AWA2,CUB,SUN与FLO数据集上的广义零样本分类表现图2 基于t-SNE所展示的模型在AWA1数据集上的分类效果图3 不同语义属性对模型在CUB数据集上的分类表现表3 各模块对模型分类性能的影响图4 预分类得分分布可视化图5 预分类得分数值可视化图6 加权系数a对准确率影响的分析图7 类扩展前后可见类别的平均类内差异及其变化率表4 类别扩展前在语义属性空间上的有效性分析
表1 各数据集在 P S划分方式下的详细信息表2 在AWA1,AWA2,CUB,SUN与FLO数据集上的广义零样本分类表现图2 基于t-SNE所展示的模型在AWA1数据集上的分类效果图3 不同语义属性对模型在CUB数据集上的分类表现表3 各模块对模型分类性能的影响图4 预分类得分分布可视化图5 预分类得分数值可视化图6 加权系数a对准确率影响的分析图7 类扩展前后可见类别的平均类内差异及其变化率表4 类别扩展前在语义属性空间上的有效性分析

/
| 〈 |
|
〉 |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}