 PDF(2117 KB)
PDF(2117 KB)
 PDF(2117 KB)
PDF(2117 KB)
PDF(2117 KB)
PDF(2117 KB)
基于多维云概念嵌入的变分图自编码器研究
Research on Variational Graph Auto-Encoder Based on Multidimensional Cloud Concept Embedding
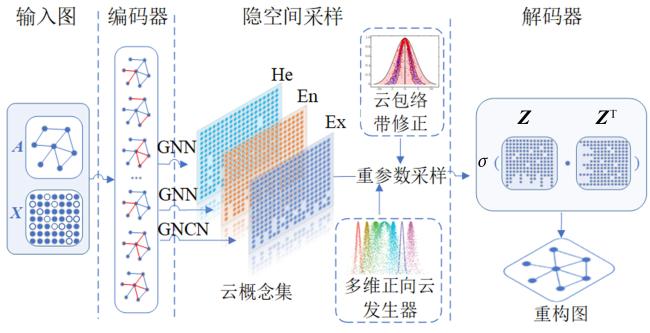
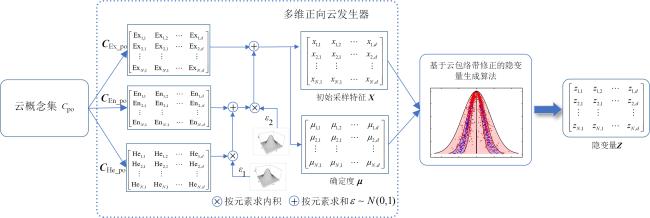
变分图自编码器是图嵌入研究中重要的深度学习模型,但存在着先验正态分布缺陷、训练过程中容易出现后验塌陷等问题.本文从建立云概念空间与隐空间的映射关系入手,引入云模型数字特征对网络中的节点进行不确定性概念表示,设计了一种基于多维云模型的变分图自编码器(Variational Graph Autoencoder based on Multidimensional Cloud Model,MCM-VGAE).该模型实现了隐空间的多维云概念嵌入及相应的漂移性损失度量,将先验分布扩展为泛正态分布,利用多维正向云发生器及云包络带修正采样算法实现了重参数化过程,有效缓解了后验塌陷现象.在应用效果上,模型在多类型数据集上的链路预测、节点聚类、图嵌入可视化实验表现均优于基准模型,进一步说明了方法的普适有效性.
Variational graph autoencoder (VGAE) is a significant deep learning model in graph embedding, but there are problems such as the normal prior distribution defect and the posterior collapse during training. Focusing on establishing the mapping relationship between cloud concept space and hidden space, the uncertain concepts of nodes in VGAE network are represented by the digital features of cloud model, and an optimized VGAE model based on multidimensional cloud model (MCM-VGAE) is reconstructed. The model implements a multidimensional cloud concept embedding in the latent space and the corresponding drift loss measure, extends the prior distribution to a generic normal distribution, and uses a multidimensional forward cloud generator and a cloud envelope with modified sampling algorithm to realize the reparameterization process and effectively mitigate the posterior collapse phenomenon. In terms of application, the model outperforms the benchmark model for link prediction, node clustering, and graph embedding visualization experiments on multi-type datasets, further illustrating the universal effectiveness of the method.
变分图自编码器 / 图嵌入 / 多维云模型 / 概念嵌入 / 链路预测 {{custom_keyword}} /
variational graph autoencoder / graph embedding / multidimensional cloud model / concept embedding / link prediction {{custom_keyword}} /
| |
|---|
| 输入:后验云概念集 输出:隐变量特征矩阵 (1) (2) (3) 对 (4) IF (5) (6) IF (7) IF (8) ELSE // 初始采样值位于期望右侧 (9) END IF (10) (11) END IF (12) END IF (13) |
| 算法2 MCM⁃VGAE模型训练算法流程 |
|---|
| 输入:图 输出:隐变量特征矩阵 Z,待学习的模型参数 (1) (2) 初始化待学习模型参数 (3) WHILE (4) (5) (6) (7) (8) END WHILE |
表1 数据集信息统计 |
| 数据集 | 节点 | 边 | 特征 | 类别 | 存在 孤立节点 |
|---|---|---|---|---|---|
| Cora | 2 708 | 10 556 | 1 433 | 7 | 否 |
| Citesser | 3 327 | 9 104 | 3 703 | 6 | 是 |
| Pubmed | 19 717 | 88 648 | 500 | 3 | 否 |
| Computers | 13 752 | 491 722 | 767 | 10 | 是 |
| Photo | 7 650 | 238 162 | 745 | 8 | 是 |
| NELL | 65 755 | 251 550 | 61 278 | 186 | 否 |
表2 对比方法及描述 |
| 方法类型 | 方法名 | 描述 |
|---|---|---|
| 基于图自编码器 | GAE[4] | 一种基于自编码器的图嵌入学习框架 |
| Linear-GAE[8] | 线性图自编码器 | |
| GNAE[7] | 图归一化自编码器 | |
| 基于vMF分布的变分图自编码器 | S-VGAE[8] | 基于超球面分布的变分图自编码器 |
| 基于先验高斯分布的变分图自编码器 | VGAE[4] | 变分图自编码器 |
| ARVGE[5] | 一种基于对抗正则化思想的变分图自编码器 | |
| Linear-VGAE[8] | 线性变分图自编码器 | |
| VGNAE[7] | 变分图归一化自编码器 | |
| 基于先验正态云概念的变分图自编码器(本文方法) | MCM-VGAE | 基于多维云模型的变分图自编码器 |
| MCM-VGAEdj | MCM-VGAE的变体,使用对称KL散度实现云概念的漂移性度量 |
表3 引文网络数据集链路预测实验结果汇总 (%) |
| Method | Cora | Citeseer | Pubmed | |||
|---|---|---|---|---|---|---|
| AUC | AP | AUC | AP | AUC | AP | |
| GAE | 92.2 | 93.0 | 92.5 | 93.4 | 96.4 | 96.5 |
| VGAE | 92.4 | 93.9 | 91.0 | 91.5 | 96.2 | 96.0 |
| ARVGE | 93.4 | 94.6 | 93.5 | 94.4 | 84.5 | 83.2 |
| Linear-GAE | 93.7 | 94.6 | 93.5 | 93.3 | 96.8 | 96.0 |
| Linear-VGAE | 91.3 | 91.5 | 92.0 | 91.5 | 95.7 | 95.3 |
| S-VGAE | 94.1 | 94.1 | 94.7 | 95.2 | 96.0 | 96.0 |
| GNAE | 94.4 | 95.1 | 94.5 | 95.5 | 97.0 | 96.8 |
| VGNAE | 95.2 | 95.4 | 95.6 | 95.8 | 97.1 | 97.0 |
| MCM-VGAE | 96.8 | 97.1 | 96.7 | 97.5 | 97.9 | 97.7 |
| MCM-VGAEdj | 96.4 | 97.0 | 96.8 | 97.5 | 97.6 | 97.3 |
表4 Amazon电商网络、NELL数据集链路预测实验结果汇总 (%) |
| Method | Computers(Amazon) | Photo(Amazon) | NELL | |||
|---|---|---|---|---|---|---|
| AUC | AP | AUC | AP | AUC | AP | |
| GAE | 93.7 | 93.7 | 92.8 | 92.3 | 94.5 | 93.8 |
| VGAE | 90.1 | 91.0 | 92.0 | 91.5 | 95.7 | 95.4 |
| ARVGE | 77.6 | 77.7 | 78.7 | 78.8 | 72.1 | 74.2 |
| Linear-GAE | 88.4 | 88.6 | 91.2 | 90.9 | 93.6 | 94.8 |
| Linear-VGAE | 87.8 | 88.1 | 89.6 | 88.6 | 94.7 | 93.9 |
| S-VGAE | 88.8 | 89.1 | 93.7 | 94.2 | 94.0 | 94.6 |
| GNAE | 96.0 | 95.9 | 96.0 | 95.5 | 96.0 | 95.6 |
| VGNAE | 94.2 | 94.6 | 96.2 | 95.5 | 96.2 | 95.5 |
| MCM-VGAE | 95.7 | 95.3 | 97.2 | 96.6 | 97.1 | 96.6 |
| MCM-VGAEdj | 95.5 | 95.0 | 96.6 | 96.0 | 96.8 | 96.4 |
表5 节点聚类实验结果(Cora数据集) (%) |
| Method | ACC | NMI | ARI | F1 |
|---|---|---|---|---|
| GAE | 0.547 | 0.402 | 0.269 | 0.561 |
| VGAE | 0.599 | 0.427 | 0.334 | 0.600 |
| ARVGE | 0.477 | 0.313 | 0.173 | 0.463 |
| Linear-GAE | 0.634 | 0.468 | 0.384 | 0.641 |
| Linear-VGAE | 0.670 | 0.489 | 0.441 | 0.648 |
| S-VGAE | 0.669 | 0.469 | 0.463 | 0.663 |
| GNAE | 0.697 | 0.502 | 0.455 | 0.682 |
| VGNAE | 0.699 | 0.501 | 0.471 | 0.690 |
| MCM-VGAE | 0.723 | 0.544 | 0.514 | 0.721 |
| MCM-VGAEdj | 0.720 | 0.522 | 0.505 | 0.713 |
表6 节点聚类实验结果(Computers数据集) (%) |
| Method | ACC | NMI | ARI | F1 |
|---|---|---|---|---|
| GAE | 0.399 | 0.406 | 0.228 | 0.338 |
| VGAE | 0.351 | 0.331 | 0.222 | 0.261 |
| ARVGE | 0.348 | 0.326 | 0.219 | 0.257 |
| Linear-GAE | 0.380 | 0.325 | 0.199 | 0.247 |
| Linear-VGAE | 0.372 | 0.314 | 0.190 | 0.241 |
| S-VGAE | 0.360 | 0.387 | 0.265 | 0.363 |
| GNAE | 0.496 | 0.482 | 0.311 | 0.405 |
| VGNAE | 0.501 | 0.485 | 0.321 | 0.405 |
| MCM-VGAE | 0.533 | 0.514 | 0.360 | 0.433 |
| MCM-VGAEdj | 0.506 | 0.503 | 0.341 | 0.418 |
| 1 |
李德毅, 刘常昱, 杜鹢, 等. 不确定性人工智能[J]. 软件学报, 2004, 15(11): 1583-1594.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
祁志卫, 王笳辉, 岳昆, 等. 图嵌入方法与应用: 研究综述[J]. 电子学报, 2020, 48(4): 808-818.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
吴博, 梁循, 张树森, 等. 图神经网络前沿进展与应用[J]. 计算机学报, 2022, 45(1): 35-68.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
李德毅, 刘常昱. 论正态云模型的普适性[J]. 中国工程科学, 2004, 6(8): 28-34.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
杨洁, 王国胤, 刘群, 等. 正态云模型研究回顾与展望[J]. 计算机学报, 2018, 41(3): 724-744.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
过江, 张为星, 赵岩. 岩爆预测的多维云模型综合评判方法[J]. 岩石力学与工程学报, 2018, 37(5): 1199-1206.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
代劲, 胡彪, 王国胤, 等. 分布轮廓与局部特征融合的云模型不确定性相似度量[J]. 电子与信息学报, 2022, 44(4): 1429-1439.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
陈昊, 龙文佳. 高斯云模型的雾化特性[J]. 湖北大学学报(自然科学版), 2015, 37(6): 560-564.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
FEY M,
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(2117 KB)
PDF(2117 KB)
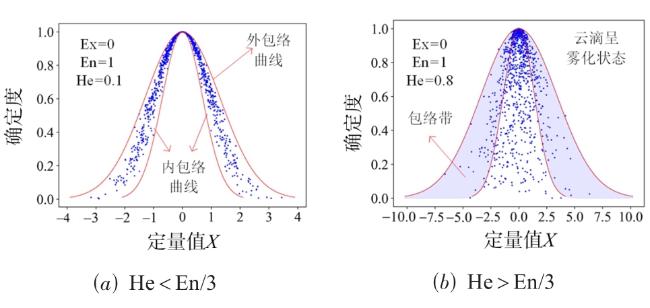
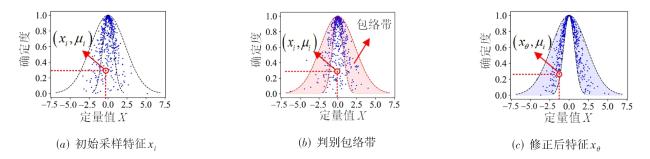
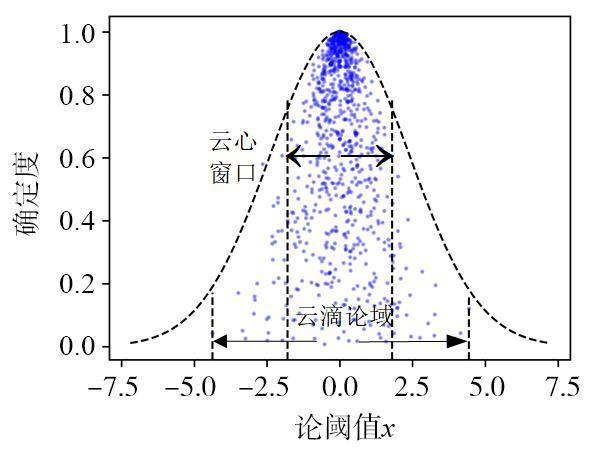
 图1 MCM-VGAE模型整体框架图2 基于多维正向云发生器以及云包络带修正的隐变量采样优化过程示意图图3 正态云在不同情形下的包络曲线示意图图4 云包络带修正采样示意图
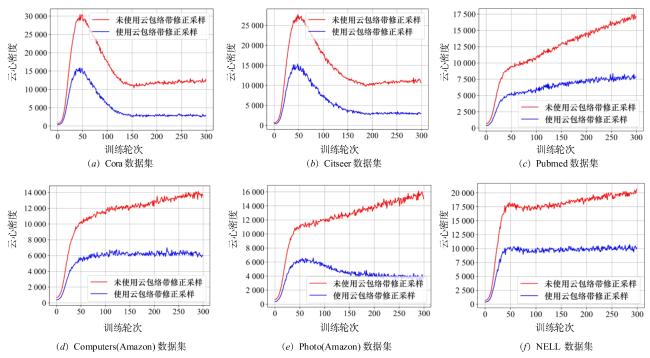
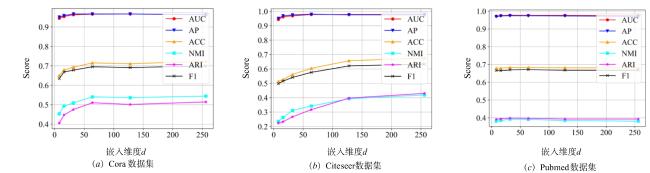
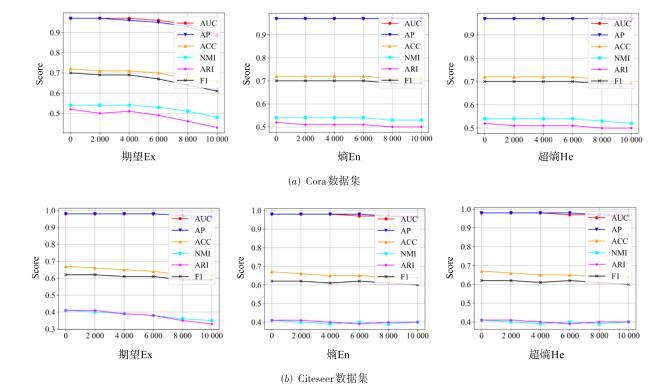
图1 MCM-VGAE模型整体框架图2 基于多维正向云发生器以及云包络带修正的隐变量采样优化过程示意图图3 正态云在不同情形下的包络曲线示意图图4 云包络带修正采样示意图 表1 数据集信息统计表2 对比方法及描述图5 云滴分布示意图图6 模型训练过程中云包络带修正采样算法对云心密度的影响表3 引文网络数据集链路预测实验结果汇总 (%)表4 Amazon电商网络、NELL数据集链路预测实验结果汇总 (%)表5 节点聚类实验结果(Cora数据集) (%)表6 节点聚类实验结果(Computers数据集) (%)图7 图嵌入可视化结果(Cora数据集)图8 图嵌入可视化结果(Computers数据集)图9 不同嵌入维度d对于链路预测、节点聚类实验结果的影响图10 不同先验云概念数字特征对于实验结果的影响
表1 数据集信息统计表2 对比方法及描述图5 云滴分布示意图图6 模型训练过程中云包络带修正采样算法对云心密度的影响表3 引文网络数据集链路预测实验结果汇总 (%)表4 Amazon电商网络、NELL数据集链路预测实验结果汇总 (%)表5 节点聚类实验结果(Cora数据集) (%)表6 节点聚类实验结果(Computers数据集) (%)图7 图嵌入可视化结果(Cora数据集)图8 图嵌入可视化结果(Computers数据集)图9 不同嵌入维度d对于链路预测、节点聚类实验结果的影响图10 不同先验云概念数字特征对于实验结果的影响

/
| 〈 |
|
〉 |












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}