 PDF(1618 KB)
PDF(1618 KB)
 PDF(1618 KB)
PDF(1618 KB)
PDF(1618 KB)
PDF(1618 KB)
采用多头注意力机制的C&RM-MAKT预测算法
C&RM-MAKT Prediction Algorithm Using Multi-Head Attention Mechanism
针对深度知识追踪模型中普遍存在知识状态向量可解释性弱、缺失历史序列数据语义特征信息、忽视历史序列数据对预测结果影响程度等问题,本文提出了一种融合认知诊断理论和多头注意力机制的预测模型C&RM-MAKT(Cognitive & Response Model- Multi-head Attention Knowledge Tracing).C&RM-MAKT采用Word2Vec和BiLSTM(Bi-directional Long Short-Term Memory)网络将时序数据变换为低维连续实值向量,引入C&RM训练出的可解释性参数来建模学生学习状态,在模型机理层面将知识状态向量扩展为知识状态矩阵.最后,C&RM-MAKT使用多头注意力机制计算出历史序列数据对预测结果的影响程度,以提高模型的可解释性与精度.预测实验结果表明:C&RM-MAKT在HNU_SYS1、HNU_SYS2、Math1和Frcsub四个数据集上都取得了最佳性能结果,尤其在HNU_SYS2中,C&RM-MAKT相较于现有知识追踪模型在AUC(Area Uder the Curve)、ACC(ACCuracy)和F 1(F 1-Measure)指标上分别提升了4.3%、3.6%和5.9%.此外,HNU_SYS2数据集上的可解释性分析表明:C&RM-MAKT模型内部参数可解释性强,一定程度上缓解了深度模型的“黑箱”特性.
To address the problems of weak interpretability of knowledge state vectors, lackness of the semantic feature of historical sequence data, and failure to consider the influence of historical sequence data on performance prediction in existing deep knowledge tracking models, this paper proposes a predictive model C&RM-MAKT (Cognitive & Response Model-Multi-head Attention Knowledge Tracing) integrating cognitive diagnostic theory with multiple attention mechanisms. C&RM-MAKT uses Word2Vec and BiLSTM (Bi-directional Long Short-Term Memory) networks to transform the time series data into low-dimensional continuous real vectors, and applies C&RM to pre-train the interpretable parameters for student state modeling, and extends the knowledge state vectors into a knowledge state matrix at the model mechanism level. C&RM-MAKT utilizes multiheaded attention mechanism to estimate the influence degree of historical exercises on the performance prediction to improve the interpretability and accuracy of the model. The prediction experiment results show that C&RM-MAKT performs the best on datasets HNU_SYS1, HNU_SYS2, Math1, and Frcsub. Especially on dataset HNU_SYS2, C&RM-MAKT improves the existing knowledge tracking models by 4.3%, 3.6%, and 5.9% in terms of AUC (Area Uder the Curve), ACC (ACCuracy), and F 1 (F 1-Measure), respectively. In addition, according to the interpretability analysis on dataset HNU_SYS2, the internal parameters of the C&RM-MAKT model are highly interpretable, which alleviates the “black box” characteristics of the deep model to a certain extent.
预测算法 / 知识追踪 / 认知诊断 / 注意力机制 / LSTM网络 / 时序数据 / 语义特征 {{custom_keyword}} /
prediction algorithm / knowledge tracking / cognitive diagnosis / attention mechanism / LSTM (Long Short-Term Memory) network / time series data / semantic features {{custom_keyword}} /
表1 C&RM中参数及含义 |
| 参数名 | 含义 |
|---|---|
| | 学习者 |
| | 学习者 |
| | 知识特性 |
| | 习题特性 |
| | 习题知识点 |
| | 学习者 |
| | 学习者 |
| | 学习者 |
| 算法1 C&RM⁃MAKT算法 |
|---|
| 输入:学生作答结果集合 输出:预测习题作答结果 随机初始化参数初始值 FOR END FOR FOR END FOR |
表2 数据集信息 |
| 数据集 | HNU_SYS1 | HNU_SYS2 | Math1 | Frcsub |
|---|---|---|---|---|
| 学生数量 | 466 | 770 | 4 209 | 536 |
| 习题数量 | 90 | 221 | 15 | 20 |
| 知识点数量 | 6 | 50 | 11 | 8 |
| 习题作答记录数 | 21 450 | 84 320 | 63 515 | 10 720 |
表3 HNU_SYS2数据集上消融实验结果 |
| 指标 | 模型 | 训练集比例 | |||||
|---|---|---|---|---|---|---|---|
| 30% | 40% | 50% | 60% | 70% | 80% | ||
| AUC | DKT | 0.720 | 0.724 | 0.729 | 0.737 | 0.744 | 0.732 |
| DKT+E | 0.726 | 0.728 | 0.739 | 0.743 | 0.749 | 0.746 | |
| DKT+CD | 0.727 | 0.731 | 0.735 | 0.742 | 0.746 | 0.747 | |
| DKT+A | 0.746 | 0.740 | 0.747 | 0.756 | 0.769 | 0.753 | |
| DKT+E+CD+A | 0.755 | 0.757 | 0.759 | 0.763 | 0.787 | 0.786 | |
| ACC | DKT | 0.768 | 0.770 | 0.764 | 0.772 | 0.777 | 0.769 |
| DKT+E | 0.772 | 0.778 | 0.779 | 0.779 | 0.782 | 0.783 | |
| DKT+CD | 0.773 | 0.777 | 0.780 | 0.779 | 0.780 | 0.782 | |
| DKT+A | 0.777 | 0.783 | 0.783 | 0.784 | 0.786 | 0.790 | |
| DKT+E+CD+A | 0.786 | 0.789 | 0.797 | 0.806 | 0.813 | 0.818 | |
| F 1 | DKT | 0.861 | 0.862 | 0.860 | 0.877 | 0.865 | 0.858 |
| DKT+E | 0.862 | 0.863 | 0.865 | 0.870 | 0.876 | 0.875 | |
| DKT+CD | 0.864 | 0.870 | 0.869 | 0.873 | 0.877 | 0.875 | |
| DKT+A | 0.886 | 0.881 | 0.872 | 0.875 | 0.896 | 0.887 | |
| DKT+E+CD+A | 0.890 | 0.901 | 0.917 | 0.923 | 0.924 | 0.917 | |
表4 C&RM⁃MAKT相比DKT的性能提升 (%) |
| 数据集 | 指标 | ||
|---|---|---|---|
| ACC | AUC | F 1 | |
| HNU_SYS1 | 3.9 | 1.5 | 2.7 |
| HNU_SYS2 | 3.6 | 4.3 | 5.9 |
| Frcsub | 2.7 | 1.8 | 1.6 |
| Math1 | 5.3 | 1.2 | 5.5 |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
王炼红, 刘畅, 周熊, 等. 基于学习者认知反应模型的认知诊断方法: CN202110122198.0[P]. 2021-05-07.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
BAG S,
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(1618 KB)
PDF(1618 KB)
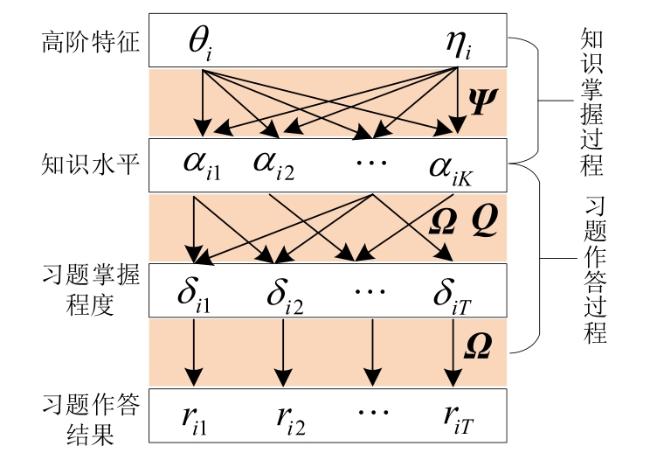
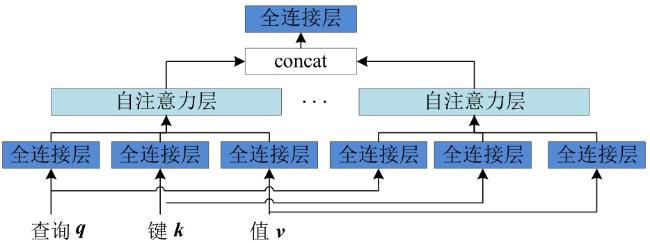
 图1 C&RM结构图
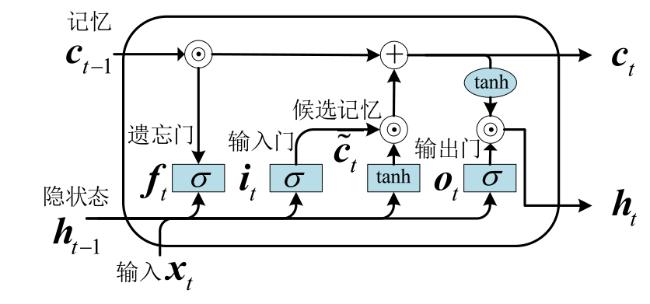
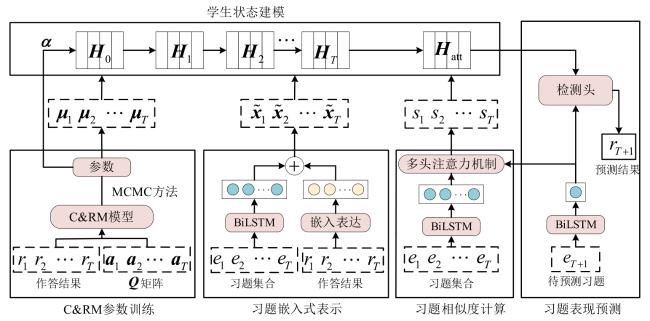
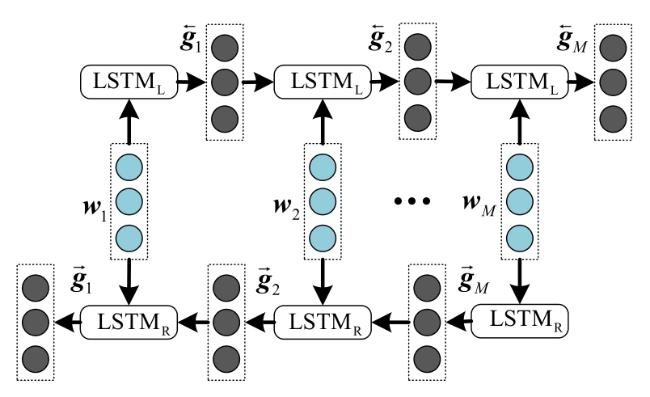
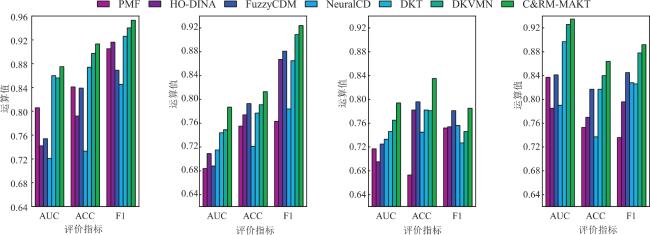
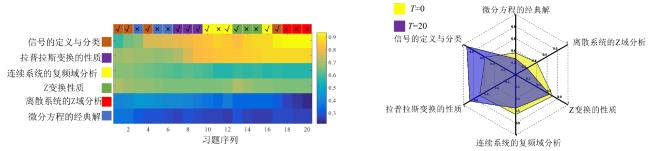
图1 C&RM结构图 表1 C&RM中参数及含义图2 LSTM模型单元结构图图3 C&RM-MAKT整体框架图4 习题嵌入式表示图5 多头注意力机制表2 数据集信息表3 HNU_SYS2数据集上消融实验结果图6 动静态知识追踪模型对比结果表4 C&RM⁃MAKT相比DKT的性能提升 (%)图7 C&RM-MAKT算法可解释性分析
表1 C&RM中参数及含义图2 LSTM模型单元结构图图3 C&RM-MAKT整体框架图4 习题嵌入式表示图5 多头注意力机制表2 数据集信息表3 HNU_SYS2数据集上消融实验结果图6 动静态知识追踪模型对比结果表4 C&RM⁃MAKT相比DKT的性能提升 (%)图7 C&RM-MAKT算法可解释性分析

/
| 〈 |
|
〉 |







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}