 PDF(1356 KB)
PDF(1356 KB)
 PDF(1356 KB)
PDF(1356 KB)
PDF(1356 KB)
PDF(1356 KB)
面向公平性数据采集和能量补充的无人机路径规划算法研究
Research on UAV Path Planning Algorithm for Fairness Data Collection and Energy Supplement
针对无人机(Unmanned Aerial Vehicle,UAV)辅助WSN(Wireless Sensor Networks)数据采集和能量补充工作中存在的数据来源单一和能量补充不均衡现象,本文首先提出数据采集和能量补充公平性问题并进行数学建模.其次,本文设计一种DPDQN(Double Parametrized Deep Q-Networks)强化学习算法,规划无人机的飞行路线和悬停位置,优化数据采集和能量补充效果.DPDQN学习离散动作与多种连续动作相混合的动作选择策略,算法网络模型包括离散动作网络和连续动作网络两部分.前者规划无人机访问数据采集节点的顺序,后者优化无人机在数据采集节点周围的悬停位置.仿真实验结果显示,本文算法在数据采集公平性、能量补充公平性、飞行距离和四种影响公平性的因素比较中均优于三种现有对比算法,并具有良好的鲁棒性和稳定性.
UAV (Unmanned Aerial Vehicle)-assisted WSN (Wireless Sensor Networks) suffers from single-source data collection and uneven energy supplement. In this article, we first investigate and develop a mathematical model for the problem of fairness for data collection and energy supplement. Then, a novel deep reinforcement learning algorithm, named DPDQN (Double Parametrized Deep Q-Networks), is designed to resolve the proposed problem. The DPDQN algorithm incorporates a hybrid discrete-continuous action strategy, which consists of two components, namely, discrete action network and continuous action network. The former schedules the UAV's visiting order to sensors in WSN, and the latter optimizes the UAV’s hover position around each visited sensor. Numerical results demonstrate that the DPDQN algorithm outperforms three existing solutions in data collection fairness, energy replenishment fairness, flying distance, and four factors that influence fairness. Furthermore, the results validate our algorithm is robust and stable.
公平性数据采集和能量补充 / 无人机路径规划 / 深度强化学习 / 无线传感器网络 {{custom_keyword}} /
fairness data collection and energy supplement / unmanned aerial vehicle path planning / deep reinforcement learning / wireless sensor networks {{custom_keyword}} /
| 算法1 DPDQN算法 |
|---|
| Input: UAV’s energy Initialize network weights: 1: FOR i = 0 to 2: 3: WHILE 4: Compute continuous action 5: Select action 6: 7: Take action 8: next state 9: Store transition 10: Simple 11: from Memory pool. 12: Define the target 13: 14: Use data 15: gradient 16: Update the weights by 17: 18: 19: END 20: Update the target networks by 21: 22: END |
表1 仿真参数 |
| 参数 | 取值 | 参数 | 取值 |
|---|---|---|---|
| 传感器数据缓存区大小 | | 无人机初始能量 | |
| 传感器初始能量 | | 带宽 | |
| 传感器感知能耗系数 | 0.001 | 信道功率 | |
| 传感器传输 | | LoS和NLoS依赖常数 | 10, 0.6 |
| 随传输距离增加的额外能耗 | | 噪声功率 | |
| 无人机飞行高度 | | 单位信道功率增益 | |
| 无人机飞行速度 | | 通径损失指数 | 2.3 |
| 无人机最大连通半径 | | 非视距信道额外衰减系数 | 0.2 |
表2 网络参数 |
| 参数 | 取值 | 参数 | 取值 |
|---|---|---|---|
| 训练轮数 | 5 000 | 学习率 | |
| 探索率 | 0.9 | 奖励折扣因子 | 0.9 |
| 批次大小 | 64 | 软拷贝参数 | 0.001 |
表3 数据采集公平性对比 ( |
| DPDQN | MODDPG | DQN | Random | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | L | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 |
| 50 | 181 | 159 | 117 | 177 | 143 | 89 | 156 | 135 | 108 | 153 | 107 | 99 | |
| 100 | 261 | 208 | 158 | 193 | 130 | 121 | 189 | 130 | 109 | 202 | 146 | 114 | |
| 150 | 252 | 209 | 180 | 191 | 149 | 116 | 231 | 156 | 120 | 230 | 181 | 97 | |
| 200 | 260 | 223 | 180 | 227 | 214 | 146 | 218 | 170 | 138 | 252 | 185 | 112 | |
表4 能量补充公平性对比 ( |
| DPDQN | MODDPG | DQN | Random | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | L | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 |
| 50 | 26 | 14 | 12 | 25 | 10 | 4 | 26 | 29 | 8 | 24 | 11 | 5 | |
| 100 | 101 | 66 | 40 | 98 | 39 | 23 | 97 | 50 | 28 | 97 | 41 | 24 | |
| 150 | 228 | 150 | 98 | 220 | 110 | 41 | 223 | 132 | 73 | 226 | 120 | 34 | |
| 200 | 403 | 264 | 162 | 366 | 237 | 92 | 400 | 212 | 121 | 366 | 215 | 76 | |
表5 无人机飞行距离 ( |
| DPDQN | MODDPG | DQN | Random | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | L | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 |
| 50 | 7.625 | 8.621 | 9.142 | 8.612 | 8.846 | 9.514 | 9.408 | 9.878 | 9.941 | 8.865 | 9.121 | 9.698 | |
| 100 | 7.598 | 8.464 | 8.951 | 8.560 | 8.762 | 9.325 | 9.324 | 9.564 | 9.917 | 8.856 | 9.105 | 9.610 | |
| 150 | 7.445 | 8.448 | 8.901 | 8.487 | 8.635 | 9.245 | 9.322 | 9.504 | 9.863 | 8.625 | 8.986 | 9.458 | |
| 200 | 7.169 | 8.347 | 8.785 | 8.336 | 8.601 | 9.021 | 9.235 | 9.463 | 9.745 | 8.602 | 8.712 | 9.254 | |
表6 数据采集量 ( |
| DPDQN | MODDPG | DQN | Random | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | L | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 |
| 50 | 448.6 | 375.4 | 158.4 | 446.2 | 333.1 | 53.6 | 377.3 | 292.9 | 236.3 | 372.8 | 251.0 | 86.1 | |
| 100 | 532.6 | 423.8 | 328.9 | 504.2 | 323.4 | 287.6 | 426.2 | 273.3 | 226.7 | 439.4 | 308.1 | 230.5 | |
| 150 | 502.7 | 407.5 | 364.9 | 511.3 | 367.4 | 262.1 | 469.6 | 324.2 | 250.0 | 489.2 | 371.8 | 195.8 | |
| 200 | 530.9 | 477.8 | 342.3 | 518.6 | 470.5 | 313.4 | 442.3 | 353.5 | 272.4 | 521.9 | 360.2 | 220.8 | |
表7 参与数据采集的传感器数量 |
| DPDQN | MODDPG | DQN | Random | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | L | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 |
| 50 | 50 | 50 | 40 | 50 | 42 | 29 | 47 | 40 | 37 | 44 | 38 | 34 | |
| 100 | 82 | 69 | 53 | 45 | 31 | 27 | 61 | 47 | 40 | 65 | 48 | 39 | |
| 150 | 84 | 67 | 58 | 41 | 32 | 30 | 75 | 48 | 44 | 71 | 56 | 40 | |
| 200 | 85 | 65 | 54 | 47 | 46 | 38 | 73 | 51 | 47 | 81 | 57 | 47 | |
表8 能量补充量 ( |
| DPDQN | MODDPG | DQN | Random | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | L | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 |
| 50 | 526 | 335 | 300 | 517 | 268 | 142 | 534 | 345 | 221 | 498 | 285 | 201 | |
| 100 | 1 019 | 742 | 521 | 990 | 501 | 349 | 990 | 592 | 374 | 990 | 555 | 359 | |
| 150 | 1 527 | 1 105 | 829 | 1 507 | 891 | 413 | 1 501 | 1 041 | 653 | 1 527 | 939 | 358 | |
| 200 | 2 022 | 1 456 | 1 032 | 1 849 | 1 360 | 701 | 2 017 | 1 298 | 859 | 1 869 | 1 270 | 585 | |
表9 WSN中传感器节点的能量分布 |
| DPDQN | MODDPG | DQN | Random | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | L | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 |
| 50 | 50 | 36 | 31 | 47 | 30 | 18 | 50 | 34 | 24 | 48 | 31 | 22 | |
| 100 | 99 | 82 | 58 | 91 | 57 | 39 | 96 | 66 | 43 | 95 | 62 | 39 | |
| 150 | 149 | 120 | 94 | 146 | 99 | 51 | 149 | 112 | 76 | 148 | 106 | 53 | |
| 200 | 200 | 163 | 116 | 196 | 131 | 87 | 197 | 142 | 92 | 196 | 135 | 89 | |
表10 WSN中传感器节点的能量分布 |
| DPDQN | MODDPG | DQN | Random | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | L | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 |
| 50 | 50 | 33 | 31 | 46 | 27 | 13 | 50 | 33 | 20 | 47 | 30 | 22 | |
| 100 | 98 | 74 | 49 | 90 | 53 | 30 | 93 | 55 | 35 | 93 | 54 | 31 | |
| 150 | 145 | 114 | 81 | 144 | 95 | 40 | 145 | 101 | 62 | 145 | 82 | 45 | |
| 200 | 197 | 155 | 106 | 182 | 117 | 69 | 194 | 132 | 80 | 183 | 119 | 70 | |
表11 WSN中传感器节点的能量分布 |
| DPDQN | MODDPG | DQN | Random | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | L | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 |
| 50 | 50 | 32 | 28 | 45 | 23 | 12 | 50 | 32 | 19 | 47 | 27 | 20 | |
| 100 | 98 | 65 | 45 | 90 | 51 | 26 | 93 | 53 | 34 | 92 | 53 | 27 | |
| 150 | 144 | 106 | 69 | 142 | 84 | 35 | 143 | 92 | 54 | 144 | 76 | 37 | |
| 200 | 194 | 136 | 87 | 173 | 110 | 54 | 193 | 110 | 70 | 180 | 109 | 60 | |
表12 WSN中传感器节点的能量分布 |
| DPDQN | MODDPG | DQN | Random | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | L | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 | 200 | 300 | 400 |
| 50 | 48 | 30 | 26 | 45 | 20 | 11 | 50 | 32 | 19 | 45 | 25 | 18 | |
| 100 | 96 | 62 | 44 | 90 | 50 | 25 | 93 | 50 | 34 | 90 | 51 | 26 | |
| 150 | 139 | 103 | 66 | 120 | 75 | 31 | 143 | 92 | 54 | 134 | 75 | 32 | |
| 200 | 184 | 130 | 84 | 156 | 99 | 46 | 193 | 110 | 70 | 171 | 100 | 50 | |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
黄晓舸, 何勇, 陈前斌, 等. 无人机群辅助的数据采集能耗优化方法[J]. 电子与信息学报, 2023, 45(6): 2054-2062.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
刘全, 翟建伟, 章宗长, 等. 深度强化学习综述[J]. 计算机学报, 2018, 41(1): 1-27.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 24 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 25 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 26 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 27 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(1356 KB)
PDF(1356 KB)
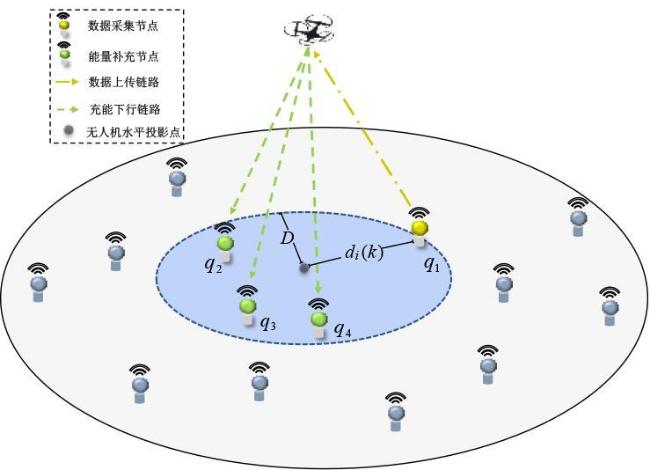
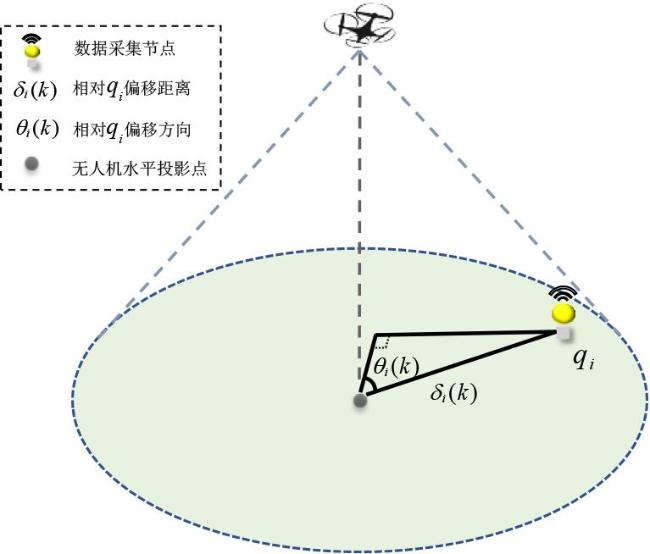
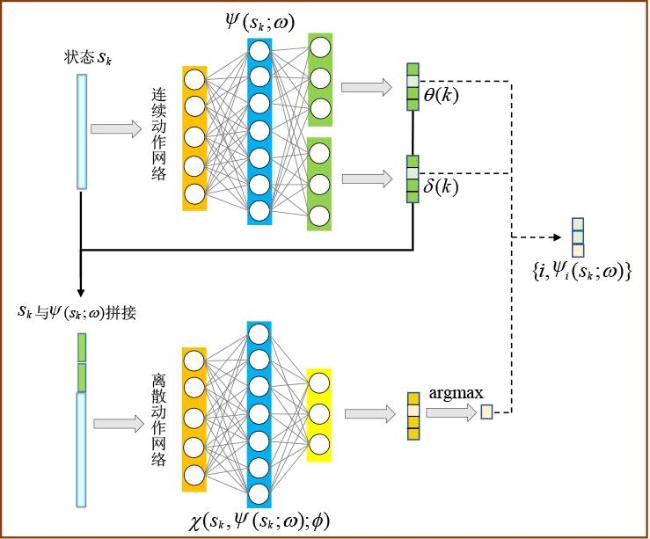
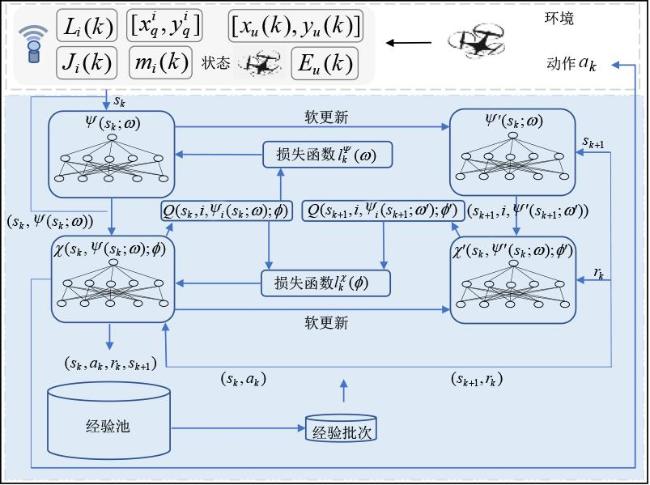
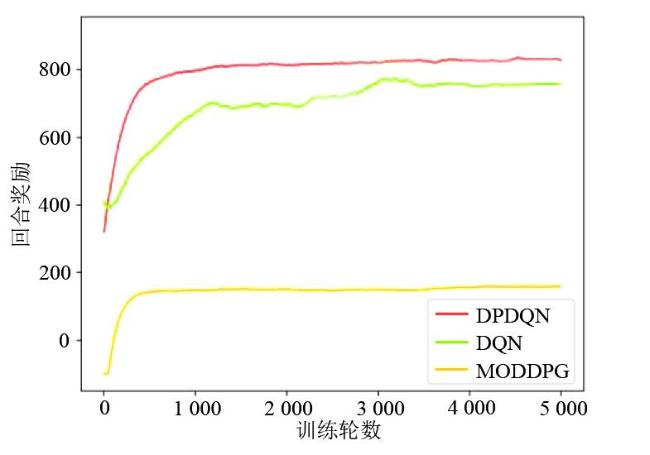
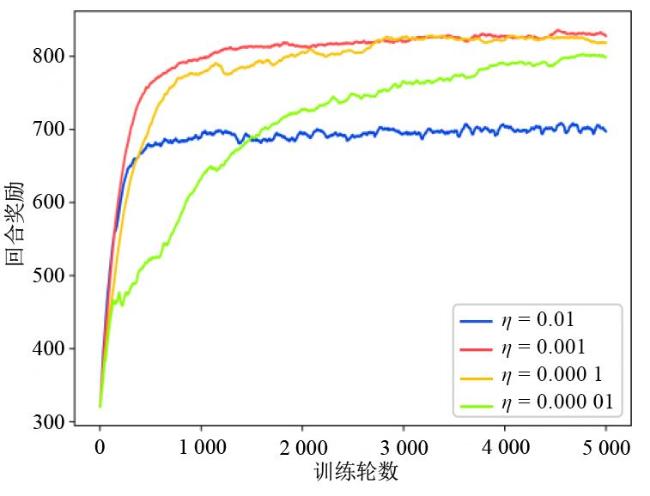
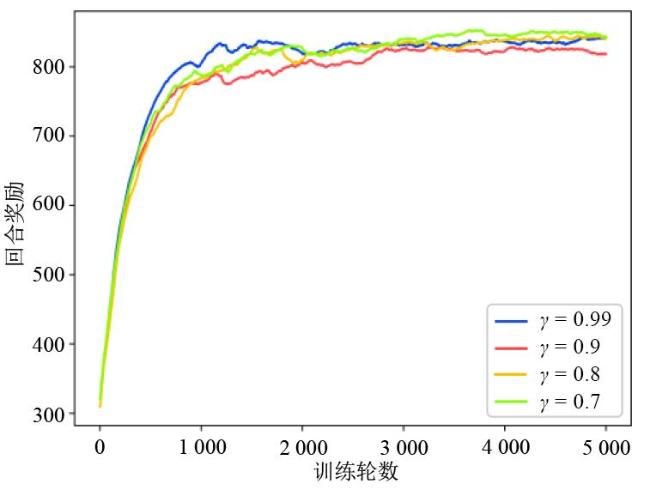
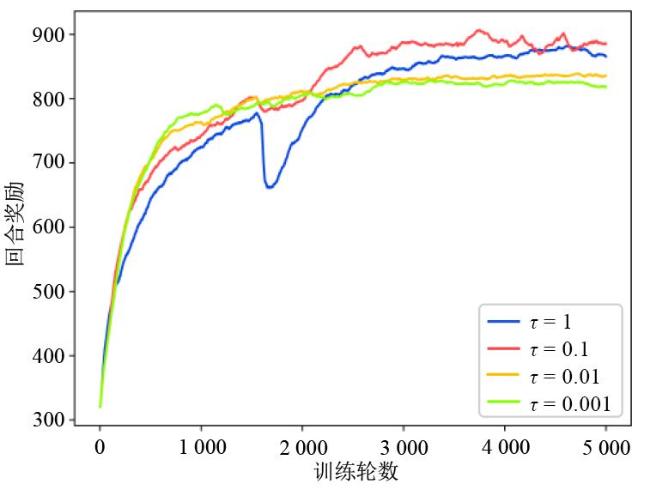
 图1 数据采集与充能图2 无人机动作表示图3 DPDQN网络结构图4 DPDQN训练流程
图1 数据采集与充能图2 无人机动作表示图3 DPDQN网络结构图4 DPDQN训练流程 表1 仿真参数表2 网络参数图5 DPDQN奖励收敛效果图表3 数据采集公平性对比 ( × 10 3)表4 能量补充公平性对比 ( × 10 3)表5 无人机飞行距离 ( k m)表6 数据采集量 ( K B)表7 参与数据采集的传感器数量表8 能量补充量 ( J)表9 WSN中传感器节点的能量分布 υ = 0.2表10 WSN中传感器节点的能量分布 υ = 0.4表11 WSN中传感器节点的能量分布 υ = 0.6表12 WSN中传感器节点的能量分布 υ = 0.8图6 不同学习率下的奖励收敛情况图7 不同奖励折扣因子下的奖励收敛情况图8 不同软拷贝下的奖励收敛情况
表1 仿真参数表2 网络参数图5 DPDQN奖励收敛效果图表3 数据采集公平性对比 ( × 10 3)表4 能量补充公平性对比 ( × 10 3)表5 无人机飞行距离 ( k m)表6 数据采集量 ( K B)表7 参与数据采集的传感器数量表8 能量补充量 ( J)表9 WSN中传感器节点的能量分布 υ = 0.2表10 WSN中传感器节点的能量分布 υ = 0.4表11 WSN中传感器节点的能量分布 υ = 0.6表12 WSN中传感器节点的能量分布 υ = 0.8图6 不同学习率下的奖励收敛情况图7 不同奖励折扣因子下的奖励收敛情况图8 不同软拷贝下的奖励收敛情况

/
| 〈 |
|
〉 |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}