 PDF(1242 KB)
PDF(1242 KB)
 PDF(1242 KB)
PDF(1242 KB)
PDF(1242 KB)
PDF(1242 KB)
基于深度学习的小目标检测基准研究进展
Research Advances on Deep Learning Based Small Object Detection Benchmarks
小目标检测是计算机视觉中极具挑战性的任务.它被广泛应用于遥感、交通、国防军事和日常生活等领域.相比其他视觉任务,小目标检测的研究进展相对缓慢.制约因素除了学习小目标特征的内在困难,还有小目标检测基准,即小目标检测数据集的稀缺以及建立小目标检测评估指标的挑战.为了更深入地理解小目标检测,本文首次对基于深度学习的小目标检测基准进行了全新彻底的调查.系统介绍了现存的35个小目标数据集,并从相对尺度和绝对尺度(目标边界框的宽度或高度、目标边界框宽高的乘积、目标边界框面积的平方根)对小目标的定义进行全面总结.重点从基于交并比及其变体、基于平均精度及其变体以及其他评估指标这3方面详细探讨了小目标检测评估指标.此外,从锚框机制、尺度感知与融合、上下文信息、超分辨率技术以及其他改进思路这5个角度对代表性小目标检测算法进行了全面阐述.与此同时,在6个数据集上对典型评估指标(评估指标+目标定义、评估指标+单目标类别)下的代表性小目标检测算法进行性能的深入分析与比较,并从小目标检测新基准、小目标定义的统一、小目标检测新框架、多模态小目标检测算法、旋转小目标检测以及高精度且实时的小目标检测这6个方面指出未来可能的发展趋势.希望该综述可以启发相关研究人员,进一步促进小目标检测的发展.
Small object detection is an extremely challenging task in computer vision. It is widely used in remote sensing, intelligent transportation, national defense and military, daily life and other fields. Compared to other visual tasks such as image segmentation, action recognition, object tracking, generic object detection, image classification, video caption and human pose estimation, the research progress of small object detection is relatively slow. We believe that the constraints mainly include two aspects: the intrinsic difficulty of learning small object features and the scarcity of small object detection benchmarks. In particular, the scarcity of small object detection benchmarks can be considered from two aspects: the scarcity of small object detection datasets and the difficulty of establishing evaluation metrics for small object detection. To gain a deeper understanding of small object detection, this article conducts a brand-new and thorough investigation on small object detection benchmarks based on deep learning for the first time. The existing 35 small object detection datasets are introduced from 7 different application scenarios, such as remote sensing images, traffic sign and traffic light detection, pedestrian detection, face detection, synthetic aperture radar images and infrared images, daily life and others. Meanwhile, comprehensively summarize the definition of small objects from both relative scale and absolute scale. For the absolute scale, it mainly includes 3 categories: the width or height of the object bounding box, the product of the width and height of the object bounding box, and the square root of the area of the object bounding box. The focus is on exploring the evaluation metrics of small object detection in detail from 3 aspects: based on IoU (Intersection over Union) and its variants, based on average precision and its variants, and other evaluation metrics. In addition, in-depth analysis and comparison of the performance of some representative small object detection algorithms under typical evaluation metrics are conducted on 6 datasets. These categories of typical evaluation metrics can be further subdivided, including the evaluation metric plus the definition of objects, the evaluation metric plus single object category. More concretely, the evaluation metrics plus the definition of objects can be divided into 4 categories: average precision plus the definition of objects, miss rate plus the definition of objects, DoR-AP-SM (Degree of Reduction in Average Precision between Small objects and Medium objects) and DoR-AP-SL (Degree of Reduction in Average Precision between Small objects and Large objects). For the evaluation metrics plus single object category, it mainly includes 2 types: average precision plus single object category, OLRP (Optimal Localization Recall Precision) plus single object category. These representative small object detection methods mainly include anchor mechanism, scale-aware and fusion, context information, super-resolution technique and other improvement ideas. Finally, we point out the possible trends in the future from 6 aspects: a new benchmark for small object detection, a unified definition of small objects, a new framework for small object detection, multi-modal small object detection algorithms, rotating small object detection, and high precision and real time small object detection. We hope that this paper could provide a timely and comprehensive review of the research progress of small object detection benchmarks based on deep learning, and inspire relevant researchers to further promote the development of this field.
小目标检测 / 深度学习 / 小目标评估指标 / 小目标数据集 / 小目标定义 / 小目标检测基准 {{custom_keyword}} /
small object detection / deep learning / evaluation metric of small objects / small object dataset / the definition of small objects / small object detection benchmark {{custom_keyword}} /
表1 国内外小目标检测综述对比 |
| 分类 | 文献 | 主要涉及的算法或技术 |
|---|---|---|
| 国内 | 文献[1] | 一阶段算法、二阶段算法、多阶段算法 |
| 文献[3] | 数据扩充、多尺度学习、上下文学习、生成对抗学习、无锚机制 | |
| 文献[4] | 特征增强、上下文信息、锚框设计、数据集差异性处理、感兴趣区域池化层设计、数据扩充、改善定位精度、尺度自适应检测 | |
| 文献[6] | 数据扩充、特征融合、超分辨率、背景建模、优化训练策略、注意力特征感知、半监督学习、背景噪声抑制 | |
| 国外 | 文献[2] | 多尺度特征学习、数据增强、训练策略、基于上下文的检测、基于生成对抗网络的检测 |
| 文献[7] | 改进小目标特征图、结合小目标上下文信息、改善小目标前景和背景类不平衡、增加小目标训练样本 | |
| 文献[8] | 多尺度表示、上下文信息、超分辨率、区域建议 | |
| 文献[5] | 超分辨率技术、基于上下文信息、多尺度表示学习、锚框机制、训练策略、数据增强、基于损失函数的策略 | |
| 国内外综述总评 | 优点:这些综述从方法分类的角度对小目标检测展开调查,以推动小目标检测领域发展 缺点:不同分类方法之间存在一定重叠,对小目标数据集和小目标定义探讨不深,缺乏对小目标检测评估指标的深入分析 | |
| 本文 | 不同于传统的技术方法分类视角,本文首次从基准(数据集和评估指标)的角度对基于深度学习的小目标检测进行全面综述 | |
表2 现有的流行小目标数据集 |
| 应用场景 | 数据集 | 发表刊物 | 年份 | 类别数 | 图片数 | 实例数 | 公开链接与否 | 链接 |
|---|---|---|---|---|---|---|---|---|
| 遥感图像 | SODA-A[9] | ECCV | 2022 | 9 | 2 510 | 800 203 | 是 | https://shaunyuan22.github.io/SODA/ |
| AI-TOD-v2[13] | ISPRS-JPRS | 2022 | 8 | 28 036 | 752 745 | 是 | https://chasel-tsui.github.io/AI-TOD-v2/ | |
| SDOTA[10] | J-STARS | 2021 | 4 | 1 508 | 227 656 | 否 | — | |
| SDD[10] | J-STARS | 2021 | 5 | 12 628 | 343 961 | 否 | — | |
| DIOR[10,11] | ISPRS-JPRS | 2020 | 20 | 23 463 | 190 288 | 是 | http://www.escience.cn/people/gongcheng/DIOR.html | |
| AI-TOD[12] | ICPR | 2020 | 8 | 28 036 | 700 621 | 是 | — | |
| UAVDT[14] | ECCV | 2018 | 3 | 80 000 | 841 500 | 是 | https://opendatalab.com/UAVDT | |
| DOTA[15] | CVPR | 2018 | 15 | 2 806 | 188 282 | 是 | https://captain-whu.github.io/DOTA | |
| SDD[16] | ECCV | 2016 | 6 | 122 897 | 20 000 | 是 | https://cvgl.stanford.edu/projects/uav_data/ | |
| DLR[17] | GRSL | 2015 | 7 | 20 | 14 235 | 是 | https://pan.baidu.com/s/1xH12NLMZtxPTlyVvzSb_Xg#list/path=%2F | |
| 交通标志与交通灯检测 | SODA-D[9] | ECCV | 2022 | 9 | 24 704 | 277 596 | 是 | https://shaunyuan22.github.io/SODA/ |
| Bosch[18] | ICRA | 2017 | 19 | 13 427 | 24 000 | 是 | https://hci.iwr.uni-heidelberg.de/content/bosch-small-traffic-lights-dataset | |
| TT100K[19] | CVPR | 2016 | 45 | 100 000 | 30 000 | 是 | http://cg.cs.tsinghua.edu.cn/traffic%2Dsign/ | |
| GTSDB[20] | IJCNN | 2013 | 4 | 900 | 1 206 | 是 | https://www.kaggle.com/datasets/safabouguezzi/german-traffic-sign-detection-benchmark-gtsdb | |
| LISA[21] | TITS | 2012 | 49 | 6 610 | 7 855 | 是 | http://cvrr.ucsd.edu/lisa/lisa-traffic-sign-dataset.html | |
| 行人检测 | TinyPerson[22] | WACV | 2020 | 5 | 1 610 | 72 651 | 是 | https://github.com/ucas-vg/TinyBenchmark |
| EuroCity Persons[23] | TPAMI | 2019 | 7 | 47 300 | 238 200 | 是 | https://eurocity-dataset.tudelft.nl/eval/overview/home | |
| CityPersons[24] | CVPR | 2017 | 30 | 5 000 | 48 188 | 是 | https://pan.baidu.com/s/1OOcNvhB6FBolD6YKh74Q4w?pwd=z1zs | |
| Caltech[26] | TPAMI | 2012 | 1 | 250 000 | 350 000 | 是 | http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/ | |
| 人脸检测 | WIDER FACE[27] | CVPR | 2016 | 60 | 32 203 | 393 703 | 是 | http://shuoyang1213.me/WIDERFACE/ |
| PASCAL FACE[28] | IVC | 2014 | 1 | 851 | 1 341 | 是 | https://paperswithcode.com/dataset/pascal-face | |
| SAR图像和红外图像 | SAR-ACD[29] | TGRS | 2022 | 20 | 11 | 4 322 | 否 | — |
| HRSID[30] | ACCESS | 2021 | 1 | 5 604 | 16 951 | 否 | — | |
| SIRST[31] | WACV | 2021 | 1 | 427 | 480 | 是 | https://github.com/YimianDai/sirst | |
| 日常生活 | Mini6KClean[32] | JVCIR | 2023 | 80 | 6 000 | 55 111 | 是 | https://github.com/graceveryear/dataquality |
| SDOD-MT[33] | ACM MM | 2019 | 13 | 16 919 | 392 969 | 是 | https://pan.baidu.com/s/1Yape24qyL8o4E2DOraT1UA | |
| Small Object Dataset[34] | ICCC | 2018 | 10 | — | 74 531 | 否 | — | |
| SOD[35] | ACCV | 2016 | 10 | 4 925 | 8 393 | 是 | http://www.merl.com | |
| MS-COCO[37] | ECCV | 2014 | 91 | 328 000 | 2 500 000 | 是 | http://cocodataset.org | |
| PASCAL-VOC[38] | IJCV | 2010 | 20 | 9 963 | 24 640 | 是 | http://host.robots.ox.ac.uk/pascal/VOC/ | |
| 其他 | Small Object Dataset[39] | Access | 2021 | 1 | 2 200 | — | 否 | — |
| USC-GRAD-STDdb[40,41] | EAAI | 2020 | 5 | >25 000 | 56 000 | 否(需求获取) | — | |
| DeepScores[42] | ICPR | 2018 | 123 | 300 000 | 80 M | 是 | https://tuggeluk.github.io/deepscores/ | |
| Lost and Found (LF)[43] | IROS | 2016 | 37 | 2 104 | — | 是 | http://shujujishi.com/dataset/6ed3302d-415f-4c2f-adc1-30c00862b78b.html |
表3 相对尺度下小目标的定义 |
| 数据集 | 相对尺度下小目标的具体定义 |
|---|---|
| UAVDT[14] | 大多数微小目标仅包含帧的0.005%像素 |
| SDD[16] | 所有目标的尺寸都不超过图像尺寸的0.2%,其中大量实例的尺寸介于图像尺寸的0.1%和0.15%之间 |
| TT100K[19] | 目标尺寸占图像尺寸20%的目标被视为小目标.若为方形形状的交通标志,那么当其边界框的宽度小于图像的20%且边界框的高度小于图像的高度时,它就被认为是一个小目标 |
| Small Object Dataset[34] | 相比于大目标,该数据集包含厨房场景中的小目标,如刀、叉、瓶子、酒杯、杯子、勺子、碗等 |
| SOD[35] | 同一类别中所有目标实例的相对面积中值介于0.08%和0.58%之间的目标被当作小目标 |
| PASCAL-VOC[5,38] | 通过计算数据集中同一类别所有目标实例的相对面积中值来定义小目标,即相对面积的中值小于5%的目标(如瓶子、汽车、盆栽、羊和船)被视为小目标 |
表4 绝对尺度下小目标的定义 |
| 定义方式 | 数据集 | 绝对尺度下小目标的具体定义 |
|---|---|---|
| 目标边界框的宽度或高度 | SDD[10],DIOR[10,11] | 将宽度或高度小于50像素的目标视为小目标 |
| SDOTA[10] | 大多是小于50像素的小目标,小型车辆类别含有许多10像素以下的小目标 | |
| DOTA[15] | 水平边界框的高度介于10到50像素的目标视为小目标 | |
| EuroCity Persons[23] | 高度介于30至60像素之间,且遮挡或截断小于40%的目标视为小目标 | |
| Caltech [26] | 高度小于30像素的目标 | |
| GTSDB[20] | 交通标志的最长边为16~128像素的视为小尺寸标志 | |
| Bosch[18] | 交通灯的宽度为1~85像素的视为小目标 | |
| SDOD-MT[33] | 水平边界框的高度为10~50像素的定义为小目标 | |
| WIDER FACE[27] PASCAL FACE[28] | 人脸高度为10~50像素的视为小尺度人脸 | |
| Lost and Found[43] | 高度低至5 cm的小障碍物视为小目标 | |
| 目标边界框宽高的 乘积(即面积) | SODA-A[9] SODA-D[9] | 面积小于2 000像素的实例被定义为小目标,具体为:极其微小目标面积小于256像素;相对微小目标面积为256~576像素;一般微小目标面积为576~1 024像素;小目标面积为1 024~2 000像素 |
| Mini6KClean[32],MS-COCO[37] | 面积小于或等于32 | |
| Small Object Dataset[39] | 不超过32×32像素的目标被视为小目标 | |
| USC-GRAD-STDdb[40,41] | 占据16 | |
| DeepScores[42] | 包含许多非常小的目标,像素面积低至几个像素 | |
| DLR[17] | 小尺寸车辆定义为小于30 | |
| LISA[21] | 小交通标志介于6 | |
| 目标边界框面积的平方根 | AI-TOD[12] AI-TOD-v2[13] | 2~8像素范围内的目标视为非常微小的目标;8~16像素范围内的目标视为微小目标;16~32像素范围内的目标视为小目标 |
| TinyPerson[22] TinyCityPersons[22] | 粗分2组:微小目标像素为2~20;小目标像素为20~32 微小目标进一步细分为3组:微小目标1的像素为2~8;微小目标2的像素为8~12;微小目标3的像素为12~20 | |
| CityPersons[22,24] | 微小目标1的像素范围为8~32;微小目标2的像素范围为32~48;微小目标3的像素范围为48~80;小目标像素范围为80~128 |
表5 小目标检测评估指标总结 |
| 评估指标分类 | 名称 | 相关描述 |
|---|---|---|
| 基于IoU及其变体 | IoU | 评估两个边界框之间位置关系最广泛使用的指标;当两个边界框无重叠或相互包容时,IoU会失效;对微小目标位置偏差很敏感 |
| IoD | 仅适用于TinyPerson中的忽略区域 | |
| GIoU,DIoU,CIoU | 它们最初被设计用于NMS和损失函数,很难在无需修改的情况下作为阈值;仅仅是对IoU施加权重的微调,未从本质上解决小目标对IoU敏感的问题 | |
| NWD | 对位置偏差的平滑性;尺度平衡;能够测量不重叠或相互包容的框之间的相似度 | |
| DR | 适合衡量小目标边界框之间的接近程度 | |
| DotD | 具有规范化的形式;关注两个边界框中心点之间的位置关系,更适合微小目标 | |
| 基于AP及其变体 | Precision,Recall,F 1 | 在为分类输出定义的分类任务中,这些是众所周知的度量标准 |
| AP,mAP | 目标检测评估中的业界标准;无法区分非常不同的PR曲线;无法推断边界框检测的紧密程度 | |
| LRP,oLRP | 解决了AP的局限性,能获得更可靠的定位性能评估 | |
| 其他评估指标 | mAR,MR,ER | 这些指标使用相对较少;MR更多会应用于行人和肿瘤检测中;ER可以帮助优化深度神经网络的训练 |
| DoR | 主要用于衡量小目标与中等或大目标之间的性能差距 | |
| FPS | 评估小目标检测算法的实时性 |
表6 不同数据集上典型评估指标与代表性小目标检测算法 |
| 数据集 | 评估指标具体描述 | 代表性小目标检测算法 |
|---|---|---|
| AI-TOD | AP+目标定义:AP,AP50,AP75,APvt,APt,APs,APm AP:在0.5和0.95之间的10个IoU阈值(间隔为0.05)上对AP取平均值 AP50和AP75分别以单个IoU阈值0.5和0.75计算 APvt:2~8像素的非常微小目标的AP APt:8~16像素的微小目标的AP APs:16~32像素的小目标的AP APm:32~64像素的中等目标的AP | M-CenterNet[12],NWD-RKA[13],DotD[48],RFLA[57],RetinaNet[69],ATSS[56],TridentNet[60] |
| AP+单目标类别:飞机、桥、储罐、船舶、游泳池、车辆、人、风力发电机 | M-CenterNet[12],TridentNet[60],RepPoints[54],Grid R-CNN[53] | |
| OLRP+单目标类别:飞机、桥、储罐、船舶、游泳池、车辆、人、风力发电机 | ||
| AI-TOD-v2 | AP+目标定义:AP,AP50,AP75,APvt,APt,APs,APm (具体说明同上述AI-TOD数据集) | ADAS-GPM[58],NWD-RKA[13],DotD[48],ATSS[56],RetinaNet[69],SPNet[66],RFLA[57],TridentNet[60],DyHead[70],SM[22],RepPoints[54],Cascade RCNN[51],Grid R-CNN[53] |
| AP+单目标类别:飞机、桥、储罐、船舶、游泳池、车辆、人、风力发电机 | ||
| TinyPerson | AP+目标定义:AP50(Tiny,Tiny1,Tiny2,Tiny3,Small),AP25(Tiny),AP75(Tiny) AP50(Tiny):2~20像素的微小目标的AP50 AP50(Tiny1):2~8像素的微小目标1的AP50 AP50(Tiny2):8~12像素的微小目标2的AP50 AP50(Tiny3):12~20像素的微小目标3的AP50 AP50(Small):20~32像素的小目标的AP50 AP25(Tiny):2~20像素的微小目标的AP25 AP75(Tiny):2~20像素的微小目标的AP75 | SM[22],RetinaNet[69],SSPNet[66],SM+[63],S- |
| MR+目标定义:MR50(Tiny,Tiny1,Tiny2,Tiny3,Small),MR25(Tiny),MR75(Tiny) MR50(Tiny):2~20像素的微小目标的MR50 MR50(Tiny1):2~8像素的微小目标1的MR50 MR50(Tiny2):8~12像素的微小目标2的MR50 MR50(Tiny3):12~20像素的微小目标3的MR50 MR50(Small):20~32像素的小目标的MR50 MR25(Tiny):2~20像素的微小目标的MR25 MR75(Tiny):2~20像素的微小目标的MR75 | SM[22],RetinaNet[69],SSPNet[66],S- | |
| MS-COCO | AP+目标定义:AP,APS,APM,APL AP:在0.5和0.95之间的10个IoU阈值(间隔为0.05)上对AP取平均值 APS:面积小于或等于322像素的小目标的AP APM面积在322和962像素之间的中等目标的AP APL面积大于962像素的大目标的AP | LocalNet[68],IMFRE[61],FDL[71],QueryDet[72],IENet[67],CPT-Matching[52],GDL[73],RHFNet[62],IPGNet[59],MTGAN[74],Focal Loss[69] |
| DoR-AP-SM,DoR-AP-SL | ||
| SODA-D | AP+目标定义:AP,AP50,AP75,APT,APeT,APrT,APgT,APS AP描述同上述MS-COCO;AP50和AP75分别以单个IoU阈值0.5和0.75计算 APT:面积小于1 024像素的微小目标的AP APeT:面积小于256像素的极其微小目标的AP APrT:面积介于256和576像素之间的相对微小目标的AP APgT:面积介于576和1 024像素之间的一般微小目标的AP APS:面积介于1 024和2000像素之间的小目标的AP | ATSS[56],RetinaNet[69],RepPoints[54],FCOS[55],Sparse RCNN[75],Deformable-DETR[76],Cascade RCNN[51] |
| AP+单目标类别:人、骑手、自行车、汽车、车辆、交通标志、交通灯、摄像头、警示锥 | ||
| SODA-A | AP+目标定义:AP,AP50,AP75,APT,APeT,APrT,APgT,APS(具体说明同上述SODA-D数据集) | Rotated RetinaNet[69],S2A-Net[77],Gliding Vertex[78],Oriented RCNN[79],DODet[80],RoI Transformer[81] |
| AP+单目标类别:飞机、直升机、小型车辆、大型车辆、船、集装箱、储罐、游泳池、风车 |
表7 不同方法在AI-TOD-v2验证集上的性能 (%) |
| 年份 | 方法 | 主干网络 | AP | AP50 | AP75 | APvt | APt | APs | APm |
|---|---|---|---|---|---|---|---|---|---|
| 2023 | Faster R-CNN w/ADAS-GPM[58] | ResNet50 | 22.3 | 53.7 | 13.5 | 7.1 | 21.9 | 27.5 | 35.1 |
| 2023 | Cascade R-CNN w/ADAS-GPM[58] | ResNet50 | 24.2 | 54.2 | 17.0 | 6.0 | 24.0 | 29.3 | 40.0 |
| 2023 | DetectoRS w/ADAS-GPM[58] | ResNet50 | 25.0 | 57.5 | 17.3 | 7.1 | 24.8 | 30.8 | 41.7 |
| 2022 | SSPNet[66] | ResNet50 | 13.1 | 30.3 | 8.8 | 0.0 | 9.7 | 27.1 | 37.6 |
| 2022 | Faster R-CNN /NWD[13] | ResNet50 | 20.5 | 51.5 | 12.4 | 5.8 | 20.3 | 25.4 | 35.7 |
| 2022 | DetectoRS /NWD[13] | ResNet50 | 24.5 | 56.4 | 17.4 | 7.6 | 24.3 | 29.9 | 41.4 |
| 2022 | RFLA[57] | ResNet50 | 20.9 | 51.8 | 11.8 | 6.0 | 20.9 | 26.0 | 35.9 |
| 2021 | Cascade RCNN[51] | ResNet50 | 14.4 | 32.7 | 10.6 | 0.0 | 9.9 | 28.3 | 39.9 |
| 2021 | DyHead[70] | ResNet50 | 14.0 | 32.0 | 9.5 | 1.7 | 10.9 | 22.9 | 37.9 |
| 2020 | SM[22] | ResNet50 | 19.8 | 46.1 | 12.7 | 5.0 | 19.9 | 26.3 | 37.1 |
| 2020 | ATSS[56] | ResNet50 | 15.5 | 36.5 | 9.6 | 1.9 | 12.7 | 24.6 | 36.2 |
| 2020 | RetinaNet[69] | ResNet50 | 7.4 | 21.1 | 3.5 | 2.5 | 6.5 | 13.1 | 22.9 |
| 2019 | RepPoints[54] | ResNet50 | 10.6 | 27.8 | 5.6 | 2.0 | 10.1 | 16.0 | 21.8 |
| 2019 | Grid R-CNN[53] | ResNet50 | 14.7 | 31.7 | 11.4 | 0.0 | 11.5 | 27.4 | 38.0 |
| 2019 | TridentNet[60] | ResNet50 | 9.7 | 23.3 | 6.5 | 0.0 | 5.2 | 20.5 | 32.7 |
表8 不同方法在AI-TOD-v2验证集上的类别AP结果 (%) |
| 年份 | 方法 | 飞机 | 桥 | 储罐 | 船舶 | 游泳池 | 车辆 | 人 | 风力发电机 |
|---|---|---|---|---|---|---|---|---|---|
| 2023 | Faster R-CNN w/ADAS-GPM[58] | 19.0 | 15.6 | 38.6 | 37.0 | 27.8 | 27.9 | 7.0 | 5.6 |
| 2023 | Cascade R-CNN w/ADAS-GPM[58] | 20.2 | 19.0 | 41.1 | 40.0 | 30.6 | 29.4 | 7.9 | 4.8 |
| 2023 | DetectoRS w/ADAS-GPM[58] | 25.9 | 18.4 | 40.9 | 42.5 | 29.6 | 28.8 | 8.2 | 5.8 |
| 2022 | SSPNet[66] | 15.5 | 3.8 | 22.8 | 20.1 | 23.4 | 15.8 | 3.5 | 0.2 |
| 2022 | Faster R-CNN /NWD[13] | 17.8 | 11.0 | 38.1 | 34.7 | 24.2 | 27.7 | 7.1 | 3.7 |
| 2022 | DetectoRS /NWD[13] | 24.2 | 17.4 | 40.5 | 42.0 | 29.5 | 28.6 | 8.3 | 5.8 |
| 2022 | RFLA[57] | 16.1 | 14.0 | 38.2 | 33.8 | 26.6 | 27.0 | 7.3 | 4.0 |
| 2021 | Cascade RCNN[51] | 13.8 | 5.5 | 22.6 | 24.5 | 28.2 | 17.4 | 3.4 | 0.0 |
| 2021 | DyHead[70] | 11.4 | 5.8 | 25.1 | 22.9 | 22.7 | 19.6 | 3.8 | 0.4 |
| 2020 | SM[22] | 13.4 | 10.2 | 38.2 | 33.8 | 25.3 | 27.4 | 7.9 | 2.3 |
| 2020 | ATSS[56] | 13.7 | 3.4 | 30.2 | 25.6 | 24.2 | 22.5 | 3.9 | 0.1 |
| 2020 | RetinaNet[69] | 2.4 | 7.5 | 13.0 | 18.8 | 2.9 | 12.3 | 2.3 | 0.1 |
| 2019 | RepPoints[54] | 0.0 | 0.6 | 26.0 | 25.4 | 9.9 | 19.6 | 3.1 | 0.0 |
| 2019 | Grid R-CNN[53] | 13.3 | 10.8 | 22.7 | 25.0 | 26.1 | 16.2 | 3.2 | 0.1 |
| 2019 | TridentNet[60] | 12.2 | 0.0 | 17.9 | 13.5 | 20.0 | 11.9 | 1.9 | 0.0 |
表9 检测器在AI-TOD-v2测试集上的性能 (%) |
| 年份 | 方法 | 主干网络 | AP | AP50 | AP75 | APvt | APt | APs | APm |
|---|---|---|---|---|---|---|---|---|---|
| 2022 | RetinaNet w/ NWD-RKA[13] | ResNet50 | 10.5 | 28.5 | 5.2 | 3.5 | 11.0 | 15.2 | 24.2 |
| 2022 | Faster R-CNN w/ NWD-RKA[13] | ResNet50 | 21.4 | 53.2 | 12.5 | 7.7 | 20.7 | 26.8 | 35.2 |
| 2022 | Faster R-CNN w/ NWD-RKA[13] | ResNet101 | 20.8 | 52.4 | 12.3 | 8.5 | 20.4 | 24.9 | 35.1 |
| 2022 | Cascade R-CNN w/ NWD-RKA[13] | ResNet50 | 22.2 | 52.5 | 15.1 | 7.8 | 21.8 | 28.0 | 37.2 |
| 2022 | DetectoRS w/ NWD-RKA[13] | ResNet50 | 24.7 | 57.4 | 17.1 | 9.7 | 24.2 | 29.8 | 39.3 |
| 2021 | DotD[48] | ResNet50 | 20.4 | 51.4 | 12.3 | 8.5 | 21.1 | 24.6 | 30.4 |
| 2020 | FR w/ ATSS[56] | ResNet50 | 12.8 | 29.6 | 9.2 | 0.0 | 9.2 | 24.9 | 36.6 |
| 2020 | RetinaNet[69] | ResNet50 | 8.9 | 24.2 | 4.6 | 2.7 | 8.4 | 13.1 | 20.4 |
| 2019 | TridentNet[60] | ResNet50 | 10.1 | 24.5 | 6.7 | 0.1 | 6.3 | 19.8 | 31.9 |
表10 检测器在AI-TOD-v2测试集上的类别AP结果 (%) |
| 年份 | 方法 | 飞机 | 桥 | 储罐 | 船舶 | 游泳池 | 车辆 | 人 | 风力发电机 |
|---|---|---|---|---|---|---|---|---|---|
| 2022 | RetinaNet w/ NWD-RKA[13] | 0.1 | 13.8 | 14.3 | 28.5 | 5.4 | 16.5 | 4.7 | 0.7 |
| 2022 | Faster R-CNN w/ NWD-RKA[13] | 26.7 | 16.9 | 35.1 | 33.6 | 12.8 | 26.0 | 10.3 | 6.0 |
| 2022 | Cascade R-CNN w/ NWD-RKA[13] | 28.5 | 17.5 | 36.9 | 38.3 | 13.7 | 26.6 | 10.4 | 5.7 |
| 2022 | DetectoRS w/ NWD-RKA[13] | 32.0 | 20.2 | 37.8 | 43.4 | 16.6 | 27.3 | 11.6 | 9.1 |
| 2021 | DotD[48] | 18.7 | 17.5 | 34.7 | 37.0 | 12.4 | 25.4 | 10.3 | 7.4 |
| 2020 | FR w/ ATSS[56] | 24.7 | 5.5 | 20.5 | 19.8 | 12.0 | 15.1 | 4.8 | 0.0 |
| 2020 | RetinaNet[69] | 1.3 | 11.8 | 14.3 | 23.6 | 5.8 | 11.4 | 2.3 | 0.5 |
| 2019 | TridentNet[60] | 19.3 | 0.1 | 17.2 | 16.2 | 12.4 | 12.5 | 3.4 | 0.0 |
表11 AI-TOD测试集上不同检测器的性能 (%) |
| 年份 | 方法 | 主干网络 | AP | AP50 | AP75 | APvt | APt | APs | APm |
|---|---|---|---|---|---|---|---|---|---|
| 2022 | RetinaNet w/ RFLA[57] | ResNet50 | 9.1 | 23.1 | 5.2 | 4.1 | 10.5 | 10.5 | 12.3 |
| 2022 | AutoAssign w/ RFLA[57] | ResNet50 | 14.2 | 37.8 | 6.9 | 6.4 | 14.9 | 17.4 | 21.8 |
| 2022 | Faster R-CNN w/ RFLA[57] | ResNet50 | 21.1 | 51.6 | 13.1 | 9.5 | 21.2 | 26.1 | 31.5 |
| 2022 | Cascade R-CNN w/ RFLA[57] | ResNet50 | 22.1 | 51.6 | 15.6 | 8.2 | 22.0 | 27.3 | 35.2 |
| 2022 | DetectoRS w/ RFLA[57] | ResNet50 | 24.8 | 55.2 | 18.5 | 9.3 | 24.8 | 30.3 | 38.2 |
| 2022 | Faster R-CNN with NWD-RKA[13] | ResNet50 | 19.5 | 49.2 | 11.7 | 8.3 | 19.6 | 24.5 | 31.9 |
| 2022 | Cascade R-CNN with NWD-RKA[13] | ResNet50 | 20.5 | 48.7 | 13.8 | 8.1 | 20.6 | 25.6 | 34.0 |
| 2022 | DetectoRS with NWD-RKA[13] | ResNet50 | 23.4 | 53.5 | 16.8 | 8.7 | 23.8 | 28.5 | 36.0 |
| 2021 | M-CenterNet[12] | DLA34 | 14.5 | 40.7 | 6.4 | 6.1 | 15.0 | 19.4 | 20.4 |
| 2021 | Cascade RPN w/ DotD[48] | ResNet50 | 13.7 | 34.0 | 8.7 | 6.9 | 14.8 | 15.8 | 24.6 |
| 2021 | Faster R-CNN w/ DotD[48] | ResNet50 | 14.9 | 38.5 | 9.3 | 7.2 | 16.1 | 17.9 | 23.7 |
| 2021 | Cascade R-CNN w/ DotD[48] | ResNet50 | 16.1 | 39.2 | 10.6 | 8.3 | 17.6 | 18.1 | 22.1 |
| 2020 | ATSS[56] | ResNet50 | 12.8 | 30.6 | 8.5 | 1.9 | 11.6 | 19.5 | 29.2 |
| 2020 | RetinaNet[69] | ResNet50 | 8.7 | 22.3 | 4.8 | 2.4 | 8.9 | 12.2 | 16.0 |
| 2019 | TridentNet[60] | ResNet50 | 7.5 | 20.9 | 3.6 | 1.0 | 5.8 | 12.6 | 14.0 |
表12 不同算法在AI-TOD测试集上的类别AP结果 (%) |
| 年份 | 方法 | 飞机 | 桥 | 储罐 | 船舶 | 游泳池 | 车辆 | 人 | 风力发电机 |
|---|---|---|---|---|---|---|---|---|---|
| 2022 | FCOS[55] | 14.30 | 4.75 | 19.77 | 22.24 | 0.65 | 12.51 | 3.98 | 0.17 |
| 2021 | Cascade RCNN[51] | 25.57 | 7.47 | 23.33 | 23.55 | 10.81 | 14.09 | 5.34 | 0.00 |
| 2021 | M-CenterNet[12] | 18.59 | 10.58 | 27.55 | 22.27 | 7.53 | 18.60 | 9.17 | 2.03 |
| 2019 | TridentNet[60] | 9.67 | 0.77 | 12.28 | 17.11 | 3.20 | 11.87 | 3.98 | 0.94 |
| 2019 | RepPoints[54] | 2.92 | 2.34 | 21.37 | 26.40 | 0.00 | 15.16 | 5.39 | 0.00 |
| 2019 | Grid R-CNN[53] | 22.55 | 8.59 | 18.93 | 21.99 | 7.28 | 12.94 | 4.81 | 0.35 |
表13 不同算法在AI-TOD测试集上的类别OLRP结果 (%) |
| 年份 | 方法 | 飞机 | 桥 | 储罐 | 船舶 | 游泳池 | 车辆 | 人 | 风力发电机 |
|---|---|---|---|---|---|---|---|---|---|
| 2022 | FCOS[55] | 86.46 | 94.83 | 82.89 | 80.97 | 98.29 | 88.10 | 95.62 | 99.57 |
| 2021 | Cascade RCNN[51] | 77.62 | 92.87 | 79.07 | 79.69 | 89.75 | 86.80 | 94.55 | 100.00 |
| 2021 | M-CenterNet[12] | 83.00 | 89.23 | 74.50 | 79.47 | 92.06 | 81.19 | 90.49 | 96.73 |
| 2019 | TridentNet[60] | 89.84 | 98.56 | 88.00 | 85.00 | 97.00 | 88.66 | 95.80 | 98.38 |
| 2019 | RepPoints[54] | 96.18 | 97.32 | 80.92 | 77.23 | 100.00 | 85.90 | 94.53 | 100.00 |
| 2019 | Grid R-CNN[53] | 78.59 | 91.46 | 82.74 | 81.21 | 92.72 | 87.68 | 94.99 | 99.28 |
表14 TinyPerson基准上不同方法的AP值 (%) |
| 年份 | 方法 | AP50 | AP25 | AP75 | ||||
|---|---|---|---|---|---|---|---|---|
| Tiny | Tiny1 | Tiny2 | Tiny3 | Small | Tiny | Tiny | ||
| 2022 | RetinaNet-SSPNet[66] | 54.66 | 42.72 | 60.16 | 61.52 | 65.24 | 77.03 | 6.31 |
| 2022 | Cascade R-CNN-SSPNet[66] | 58.59 | 45.75 | 62.03 | 65.83 | 71.80 | 78.72 | 8.24 |
| 2022 | Faster R-CNN-SSPNet[66] | 59.13 | 47.56 | 62.36 | 66.15 | 71.17 | 79.47 | 8.62 |
| 2021 | Faster RCNN-FPN-MSM+[63] | 52.61 | 34.20 | 57.60 | 63.61 | 67.37 | 72.54 | 6.72 |
| 2021 | Faster RCNN-FPN-RSM+[63] | 51.46 | 33.74 | 55.32 | 62.95 | 66.68 | 72.38 | 6.62 |
| 2021 | RetinaNet with S- | 48.34 | 28.61 | 54.59 | 59.38 | 61.73 | 71.18 | 5.34 |
| 2021 | Faster RCNN-FPN with S- | 48.39 | 31.68 | 52.20 | 60.01 | 65.15 | 69.32 | 5.78 |
| 2021 | RetinaNet+SM with S- | 52.56 | 33.90 | 58.00 | 63.72 | 65.69 | 73.09 | 6.64 |
| 2021 | RetinaNet+MSM with S- | 51.60 | 33.21 | 56.88 | 62.86 | 64.39 | 72.60 | 6.43 |
| 2021 | Faster RCNN-FPN+SM with S- | 51.76 | 34.58 | 55.93 | 62.31 | 66.81 | 72.19 | 6.81 |
| 2021 | Faster RCNN-FPN+MSM with S- | 51.41 | 34.64 | 55.73 | 61.95 | 65.97 | 72.25 | 6.69 |
| 2021 | Faster R-CNN with SFRF[64] | 57.24 | 51.49 | 64.51 | 67.78 | 65.33 | 78.65 | 6.42 |
| 2020 | RetinaNet-SM[22] | 48.48 | 29.01 | 54.28 | 59.95 | 63.01 | 69.41 | 5.83 |
| 2020 | RetinaNet-MSM[22] | 49.59 | 31.63 | 56.01 | 60.78 | 63.38 | 71.24 | 6.16 |
| 2020 | Faster R-CNN-FPN-SM[22] | 51.33 | 33.91 | 55.16 | 62.58 | 66.96 | 71.55 | 6.46 |
| 2020 | Faster R-CNN-FPN-MSM[22] | 50.89 | 33.79 | 55.55 | 61.29 | 65.76 | 71.28 | 6.66 |
| 2020 | RetinaNet[69] | 33.53 | 12.24 | 38.79 | 47.38 | 48.26 | 61.51 | 2.28 |
表15 TinyPerson基准上不同方法的MR值 (%) |
| 年份 | 方法 | MR50 | MR25 | MR75 | ||||
|---|---|---|---|---|---|---|---|---|
| Tiny | Tiny1 | Tiny2 | Tiny3 | Small | Tiny | Tiny | ||
| 2022 | RetinaNet-SSPNet[66] | 85.30 | 82.87 | 76.73 | 77.20 | 72.37 | 69.25 | 98.63 |
| 2022 | Cascade R-CNN-SSPNet[66] | 83.47 | 82.80 | 75.02 | 73.52 | 62.06 | 68.93 | 98.27 |
| 2022 | Faster R-CNN-SSPNet[66] | 82.79 | 81.88 | 73.93 | 72.43 | 61.26 | 66.80 | 98.06 |
| 2021 | RetinaNet with S- | 87.73 | 89.51 | 81.11 | 79.49 | 72.82 | 74.85 | 98.57 |
| 2021 | Faster RCNN-FPN with S- | 87.29 | 87.69 | 81.76 | 78.57 | 70.75 | 76.58 | 98.42 |
| 2021 | RetinaNet+SM with S- | 87.00 | 87.62 | 79.47 | 77.39 | 69.25 | 74.72 | 98.41 |
| 2021 | RetinaNet+MSM with S- | 87.07 | 88.34 | 79.76 | 77.76 | 70.35 | 75.38 | 98.41 |
| 2021 | Faster R-CNN-FPN+SM with S- | 85.96 | 86.57 | 79.14 | 77.22 | 69.35 | 73.92 | 98.30 |
| 2021 | Faster R-CNN-FPN+MSM with S- | 86.18 | 86.51 | 79.05 | 77.08 | 69.28 | 73.90 | 98.24 |
| 2020 | RetinaNet-SM[22] | 88.87 | 89.83 | 81.19 | 80.89 | 71.82 | 77.88 | 98.57 |
| 2020 | RetinaNet-MSM[22] | 88.39 | 87.80 | 79.23 | 79.77 | 72.18 | 76.25 | 98.57 |
| 2020 | Faster R-CNN-FPN-SM[22] | 86.22 | 87.14 | 79.60 | 76.14 | 68.59 | 74.16 | 98.28 |
| 2020 | Faster R-CNN-FPN-MSM[22] | 85.86 | 86.54 | 79.20 | 76.86 | 68.76 | 74.33 | 98.23 |
| 2020 | RetinaNet[69] | 88.31 | 89.65 | 81.03 | 81.08 | 74.05 | 76.33 | 98.76 |
表16 MS-COCO test-dev数据集上不同方法的检测结果 (%) |
| 年份 | 方法 | 主干网络 | AP | DoR-AP-SM | DoR-AP-SL | APS | APM | APL |
|---|---|---|---|---|---|---|---|---|
| 2021 | LocalNet512[68] | LN-ResNet | 34.4 | 22.0 | 26.8 | 20.3 | 42.3 | 47.1 |
| 2021 | Feedback-driven loss[71] | ResNet101-FPN | 43.9 | 21.7 | 32.6 | 25.1 | 46.8 | 57.7 |
| 2021 | IMFRE512[61] | ResNet101 | 37.3 | 21.1 | 26.3 | 22.9 | 44.0 | 49.2 |
| 2021 | QueryDet[72] | ResNet101 | 43.8 | 18.9 | 25.5 | 27.5 | 46.4 | 53.0 |
| 2021 | QueryDet[72] | ResNeXt101 | 44.7 | 18.4 | 24.0 | 29.1 | 47.5 | 53.1 |
| 2021 | IENet[67] | ResNet101 | 51.2 | 19.3 | 29.1 | 34.5 | 53.8 | 63.6 |
| 2020 | CPT-Matching[52] | VGG16 | 30.5 | 23.6 | 33.4 | 11.4 | 35.0 | 44.8 |
| 2020 | GDL[73] | ResNet50 | 34.8 | 20.7 | 12.2 | 23.5 | 44.2 | 35.7 |
| 2020 | GDL[73] | ResNet101-FPN | 39.2 | 18.0 | 10.0 | 28.8 | 46.8 | 38.8 |
| 2020 | RHFNet416[62] | DarkNet53 | 35.2 | 21.6 | 33.0 | 15.9 | 37.5 | 48.9 |
| 2020 | RHFNet512[62] | ResNet101 | 37.7 | 23.0 | 31.6 | 19.9 | 42.9 | 51.5 |
| 2020 | IPG RCNN[59] | IPG-Net101 | 45.7 | 22.0 | 31.7 | 26.6 | 48.6 | 58.3 |
| 2020 | MTGAN[74] | ResNet101 | 41.4 | 19.5 | 27.9 | 24.7 | 44.2 | 52.6 |
| 2020 | Focal loss[69] | ResNet101-FPN | 39.1 | 20.9 | 28.4 | 21.8 | 42.7 | 50.2 |
表17 SODA-D测试集上的基线结果(模型主干网络均采用ResNet50) (%) |
| 年份 | 方法 | AP | AP50 | AP75 | APT | APeT | APrT | APgT | APS |
|---|---|---|---|---|---|---|---|---|---|
| 2022 | FCOS[55] | 28.7 | 55.1 | 26.0 | 23.9 | 11.9 | 25.6 | 32.8 | 40.9 |
| 2021 | Cascade RCNN[51] | 35.7 | 64.6 | 33.8 | 31.2 | 20.4 | 32.5 | 39.0 | 46.9 |
| 2021 | Sparse RCNN[75] | 28.3 | 55.8 | 25.5 | 24.2 | 14.1 | 25.5 | 31.7 | 39.4 |
| 2021 | Deformable-DETR[76] | 23.4 | 50.6 | 18.8 | 19.2 | 10.1 | 20.0 | 26.5 | 34.2 |
| 2020 | RetinaNet[69] | 29.2 | 58.0 | 25.3 | 25.0 | 15.7 | 26.3 | 31.8 | 39.6 |
| 2020 | ATSS[56] | 30.1 | 59.5 | 26.3 | 26.1 | 17.0 | 27.4 | 32.8 | 40.5 |
| 2019 | RepPoints[54] | 32.9 | 60.8 | 30.9 | 28.0 | 16.2 | 29.6 | 36.8 | 45.3 |
表18 算法在SODA-D测试集上的类别AP(模型主干网络均采用ResNet50) (%) |
| 年份 | 方法 | 人 | 骑手 | 自行车 | 汽车 | 车辆 | 交通标志 | 交通灯 | 交通摄像头 | 警示锥 |
|---|---|---|---|---|---|---|---|---|---|---|
| 2022 | FCOS[55] | 36.5 | 16.3 | 14.9 | 22.7 | 48.0 | 44.1 | 37.3 | 11.4 | 27.3 |
| 2021 | Cascade RCNN[51] | 45.5 | 21.8 | 21.1 | 27.1 | 54.1 | 52.8 | 44.7 | 16.7 | 37.3 |
| 2021 | Sparse RCNN[75] | 38.1 | 15.5 | 11.6 | 21.3 | 46.4 | 46.9 | 37.8 | 10.1 | 27.2 |
| 2021 | Deformable-DETR[76] | 30.0 | 12.5 | 10.6 | 17.7 | 37.3 | 39.7 | 30.3 | 9.0 | 24.0 |
| 2020 | RetinaNet[69] | 36.7 | 15.1 | 12.1 | 20.1 | 47.9 | 48.3 | 39.0 | 13.8 | 29.3 |
| 2020 | ATSS[56] | 37.8 | 18.0 | 15.3 | 22.9 | 48.2 | 47.1 | 38.5 | 12.9 | 30.2 |
| 2019 | RepPoints[54] | 42.9 | 19.7 | 16.1 | 24.4 | 52.5 | 51.2 | 42.6 | 14.5 | 32.6 |
表19 SODA-A测试集上的基线结果(模型主干网络均采用ResNet50) (%) |
| 年份 | 方法 | AP | AP50 | AP75 | APT | APeT | APrT | APgT | APS |
|---|---|---|---|---|---|---|---|---|---|
| 2022 | S2A-Net[77] | 29.6 | 72.4 | 14.0 | 28.3 | 15.6 | 29.1 | 33.8 | 29.5 |
| 2022 | DODet[80] | 32.4 | 69.5 | 24.4 | 30.9 | 17.7 | 32.0 | 36.6 | 32.9 |
| 2021 | Gliding Vertex[78] | 33.2 | 73.2 | 24.1 | 31.7 | 18.6 | 32.6 | 38.6 | 33.8 |
| 2021 | Oriented RCNN[79] | 36.0 | 73.2 | 30.4 | 34.4 | 19.5 | 35.6 | 41.2 | 36.7 |
| 2020 | Rotated RetinaNet[69] | 28.1 | 66.1 | 17.4 | 26.8 | 14.9 | 28.3 | 32.8 | 28.2 |
| 2019 | RoI Transformer[81] | 37.7 | 75.5 | 32.1 | 36.0 | 20.7 | 37.3 | 43.3 | 39.5 |
表20 算法在SODA-A测试集上的类别AP(模型主干网络均采用ResNet50) (%) |
| 年份 | 方法 | 飞机 | 直升机 | 小型车辆 | 大型车辆 | 船 | 集装箱 | 储罐 | 游泳池 | 风车 |
|---|---|---|---|---|---|---|---|---|---|---|
| 2022 | S2A-Net[77] | 42.1 | 19.8 | 31.2 | 18.8 | 36.8 | 26.1 | 30.4 | 37.5 | 24.2 |
| 2022 | DODet[80] | 50.3 | 19.4 | 31.3 | 19.9 | 40.3 | 24.1 | 43.3 | 38.1 | 24.8 |
| 2021 | Gliding Vertex[78] | 48.1 | 12.4 | 33.3 | 26.9 | 43.4 | 29.8 | 44.3 | 34.8 | 25.7 |
| 2021 | Oriented RCNN[79] | 52.8 | 19.8 | 34.3 | 30.9 | 45.1 | 32.0 | 44.0 | 40.0 | 25.3 |
| 2020 | Rotated RetinaNet[69] | 42.3 | 16.6 | 30.1 | 14.1 | 35.6 | 23.1 | 35.8 | 34.3 | 20.6 |
| 2019 | RoI Transformer[81] | 54.2 | 21.7 | 26.1 | 31.7 | 46.5 | 35.7 | 45.7 | 40.8 | 26.7 |
表21 不同数据集上最优方法的分析(T和V分别为测试集和验证集的缩写) |
| 数据集 | 方法 | 具体策略 |
|---|---|---|
| AI-TOD-v2(V) | ADAS-GPM[58] | 高斯概率分布的模糊相似性度量与自适应动态锚框挖掘相结合,实现了良好的小目标检测 |
| AI-TOD-v2(T) | NWD-RKA[13] | 基于排序的分配策略结合新指标NWD,有效改善标签分配,以提高小目标检测性能 |
| AI-TOD(T) | RFLA[57] | 基于高斯感受野的标签分配策略实现对小目标性能的改善 |
| TinyPerson(T) | SSPNet[66] | 上下文注意力、尺度增强、尺度选择三个模块的有效结合,助力小目标检测 |
| MS-COCO(T) | IENet[67] | 双向特征融合、上下文推理、上下文特征增强联合使用,以提升小目标检测性能 |
| SODA-D(T) | Cascade RCNN[51] | 多阶段级联结构有效改善小目标检测性能 |
| SODA-A(T) | RoI Transformer[81] | 高质量的区域提议保证小目标的高召回率 |
| 1 |
刘颖, 刘红燕, 范九伦, 等. 基于深度学习的小目标检测研究与应用综述[J]. 电子学报, 2020, 48(3): 590-601.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
高新波, 莫梦竟成, 汪海涛, 等. 小目标检测研究进展[J]. 数据采集与处理, 2021, 36(3): 391-417.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
李红光, 于若男, 丁文锐. 基于深度学习的小目标检测研究进展[J]. 航空学报, 2021, 42(7): 024691.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
袁翔, 程塨, 李戈, 等. 遥感影像小目标检测研究进展[J]. 中国图象图形学报, 2023, 28(6): 1662-1684.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 24 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 25 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 26 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 27 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 28 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 29 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 30 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 31 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 32 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 33 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 34 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 35 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 36 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 37 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 38 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 39 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 40 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 41 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 42 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 43 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 44 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 45 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 46 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 47 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 48 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 49 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 50 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 51 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 52 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 53 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 54 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 55 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 56 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 57 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 58 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 59 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 60 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 61 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 62 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 63 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 64 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 65 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 66 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 67 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 68 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 69 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 70 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 71 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 72 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 73 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 74 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 75 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 76 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 77 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 78 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 79 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 80 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 81 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 82 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 83 |
张智, 易华挥, 郑锦. 聚焦小目标的航拍图像目标检测算法[J]. 电子学报, 2023, 51(4): 944-955.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(1242 KB)
PDF(1242 KB)
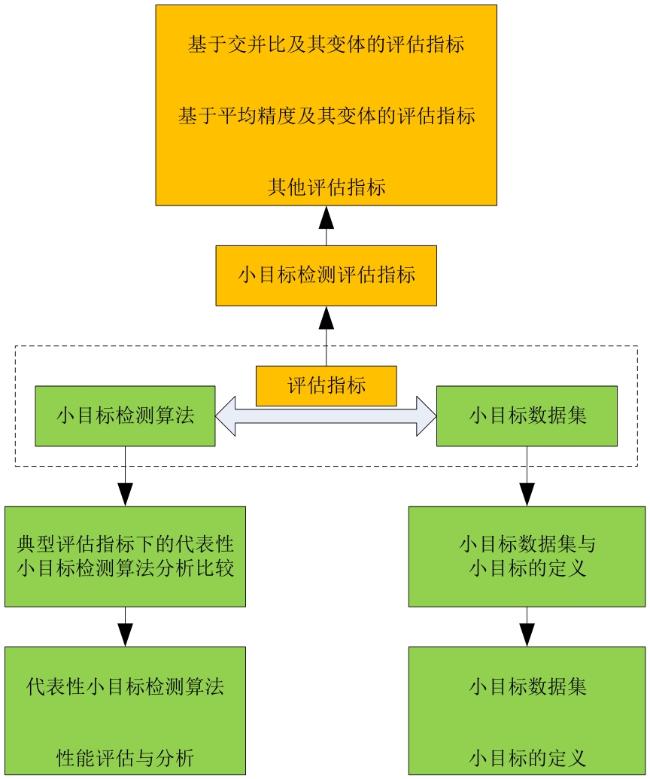
 图1 小目标检测算法在小目标数据集上的评估示意图
图1 小目标检测算法在小目标数据集上的评估示意图 表1 国内外小目标检测综述对比图2 不同应用场景中一些小目标的示例表2 现有的流行小目标数据集表3 相对尺度下小目标的定义表4 绝对尺度下小目标的定义图3 IoU及其变体评估指标的简要比较.图4 IoU对小尺寸目标(网球)和正常尺寸目标(人)的敏感性分析表5 小目标检测评估指标总结表6 不同数据集上典型评估指标与代表性小目标检测算法表7 不同方法在AI-TOD-v2验证集上的性能 (%)表8 不同方法在AI-TOD-v2验证集上的类别AP结果 (%)表9 检测器在AI-TOD-v2测试集上的性能 (%)表10 检测器在AI-TOD-v2测试集上的类别AP结果 (%)表11 AI-TOD测试集上不同检测器的性能 (%)表12 不同算法在AI-TOD测试集上的类别AP结果 (%)表13 不同算法在AI-TOD测试集上的类别OLRP结果 (%)表14 TinyPerson基准上不同方法的AP值 (%)表15 TinyPerson基准上不同方法的MR值 (%)表16 MS-COCO test-dev数据集上不同方法的检测结果 (%)表17 SODA-D测试集上的基线结果(模型主干网络均采用ResNet50) (%)表18 算法在SODA-D测试集上的类别AP(模型主干网络均采用ResNet50) (%)表19 SODA-A测试集上的基线结果(模型主干网络均采用ResNet50) (%)表20 算法在SODA-A测试集上的类别AP(模型主干网络均采用ResNet50) (%)表21 不同数据集上最优方法的分析(T和V分别为测试集和验证集的缩写)
表1 国内外小目标检测综述对比图2 不同应用场景中一些小目标的示例表2 现有的流行小目标数据集表3 相对尺度下小目标的定义表4 绝对尺度下小目标的定义图3 IoU及其变体评估指标的简要比较.图4 IoU对小尺寸目标(网球)和正常尺寸目标(人)的敏感性分析表5 小目标检测评估指标总结表6 不同数据集上典型评估指标与代表性小目标检测算法表7 不同方法在AI-TOD-v2验证集上的性能 (%)表8 不同方法在AI-TOD-v2验证集上的类别AP结果 (%)表9 检测器在AI-TOD-v2测试集上的性能 (%)表10 检测器在AI-TOD-v2测试集上的类别AP结果 (%)表11 AI-TOD测试集上不同检测器的性能 (%)表12 不同算法在AI-TOD测试集上的类别AP结果 (%)表13 不同算法在AI-TOD测试集上的类别OLRP结果 (%)表14 TinyPerson基准上不同方法的AP值 (%)表15 TinyPerson基准上不同方法的MR值 (%)表16 MS-COCO test-dev数据集上不同方法的检测结果 (%)表17 SODA-D测试集上的基线结果(模型主干网络均采用ResNet50) (%)表18 算法在SODA-D测试集上的类别AP(模型主干网络均采用ResNet50) (%)表19 SODA-A测试集上的基线结果(模型主干网络均采用ResNet50) (%)表20 算法在SODA-A测试集上的类别AP(模型主干网络均采用ResNet50) (%)表21 不同数据集上最优方法的分析(T和V分别为测试集和验证集的缩写)

/
| 〈 |
|
〉 |









{kind=link}
{kind=link}
{kind=link}
{kind=link}