 PDF(1435 KB)
PDF(1435 KB)
 PDF(1435 KB)
PDF(1435 KB)
PDF(1435 KB)
PDF(1435 KB)
基于自编码器和隔离森林的水处理系统递进式异常检测方法
A Progressive Abnormal Detection Method for Water Treatment System Based on Autoencoder and Isolation Forest
集成了工业互联网技术的水处理系统随着信息化程度的加深而面临着愈加严峻的异常行为入侵挑战.针对传统异常检测方法常用单一阈值检测、检测准确率低、误报率高等问题,提出一种融合自编码器和隔离森林的水处理系统递进式异常检测方法.首先,通过降采样过滤重复数据,加快递进式异常检测模型的训练和测试效率;其次,构建自编码器隐含层神经元捕捉数据关键特征,优化自编码器的权重和偏置,设定重构误差阈值作为输入与重构之间的差异度量进行基础性检测;最后,构建以平均路径长度为异常度量阈值的隔离树并生成隔离森林,针对基础性检测发现的异常数据进一步遍历隔离树完成高级检测;基于两阶段递进式异常检测提升检测效果.实验结果表明,本文方法在安全水处理系统数据集下的异常检测准确率、F 1值均超过95%,准确率相比于传统方法平均提升31.86个百分点,特别是异常检测误报率被较大幅度降至0.30%.对配水系统数据集进行泛化性分析取得的精确率、召回率等指标均超过94%.模型的训练和测试时间相较于对比方法具有综合性能上的突出优势.
With the deepening of informatization of water treatment systems integrated industrial internet technology are facing increasingly severe challenges of abnormal behavior intrusion. Aiming at such problems as single threshold detection, low detection accuracy, high false alarm rate and so on in traditional anomaly detection methods, a progressive anomaly detection method for water treatment systems that integrates autoencoders and isolation forests is proposed. Firstly, by downsampling to filter duplicate data, the training and testing efficiency of the progressive anomaly detection model is accelerated; Secondly, the hidden layer neurons of the autoencoder are constructed to capture the key features of the data, optimize the weight and bias of the autoencoder, and set the reconstruction error threshold as the difference measurement between input and reconstruction for basic detection; Finally, construct an isolation tree with the average path length as the anomaly measurement threshold to form an isolation forest, and further traverse the isolation tree to complete advanced detection based on the anomaly data discovered by basic detection; Improving detection performance based on two-stage progressive anomaly detection. The experimental results show that the accuracy and F 1 score of the proposed method in the secure water treatment dataset exceeds 95%, compared with the traditional method, the accuracy is improved by 31.86 percentage points on average, especially, the false positive rate of anomaly detection is significantly reduced to 0.30%. The precision rate, recall rate and other indicators obtained by the generalization analysis of the water distribution dataset are all over 94%. The training and testing time of the model has outstanding advantages in terms of comprehensive performance compared to comparative methods.
水处理系统 / 异常检测 / 自编码器 / 隔离森林 / 递进式 {{custom_keyword}} /
water treatment system / abnormal detection / autoencoder / isolation forest / progressive {{custom_keyword}} /
| 算法1 隔离树训练算法 |
|---|
| 输入: 输入数据X,当前隔离树高度m,限制高度l 输出: 隔离树 1: if m ≥ l or |X| ≤ 1 then 2: return外节点{Size ← |X|} 3: else 4: 设Q是X中的一个属性列表 5: 随机选择一个属性q∈Q 6: 从X中属性q的最大值和最小值中随机选择一个分割点p 7: Xl ← 分离 (X, q < p) 8: Xr ← 分离 (X, q ≥ p) 9: return内节点{左节点 ← 隔离树(Xl, m+1, l), 10: 右节点 ← 隔离树(Xr, m+1, l), 11: 分割属性←q, 12: 分割值←p} 13: end for |
| 算法2 路径长度算法 |
|---|
| 输入: 实例x,隔离树T,当前路径长度s 输出: x的路径长度 1: if T是一个外节点then 2: return s+c(T.size) 3: end if 4: a←T.分割属性 5: if xa < T.分割值then 6: return路径长度(x, T.left, s+1) 7: else {x ≥ T.分割值} 8: return路径长度(x, T.right, s+1) 9: end for |
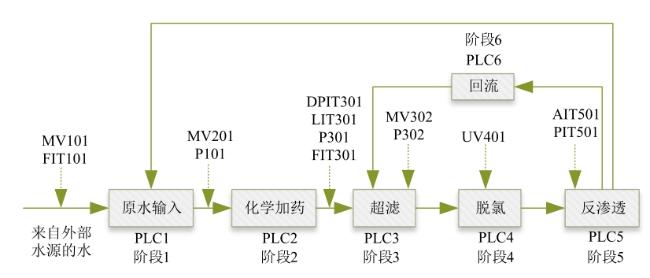
表1 SWaT水处理试验台各个阶段传感器与执行器型号 |
| 阶段 | 传感器型号 | 执行器型号 |
|---|---|---|
| 阶段1 | FIT101 LIT101 | MV101 P101 P102 |
| 阶段2 | AIT201 AIT202 AIT203 FIT201 | MV201 P201 P202 P203 P204 P205 P206 |
| 阶段3 | DPIT301 FIT301 LIT301 | MV301 MV302 MV303 MV304 P301 P302 |
| 阶段4 | AIT401 AIT402 FIT401 LIT401 | P401 P402 P403 P404 UV401 |
| 阶段5 | AIT501 AIT502 AIT503 AIT504 FIT501 FIT502 FIT503 FIT504 PIT501 PIT502 PIT503 | P501 P502 |
| 阶段6 | FIT601 | P601 P602 P603 |
表2 SWaT和WADI数据集样本类别分布 |
| 数据集 | 训练集样本数 | 测试集样本数 | 维度 |
|---|---|---|---|
| SWaT | 99 360 | 89 984 | 51 |
| WADI | 241 921 | 172 801 | 123 |
表3 自编码器实验参数 |
| 实验参数名称 | 解释说明 | 参数设置 |
|---|---|---|
| activation | 激活函数 | Relu |
| batch_size | 每个训练批次 中的样本数量 | 64 |
| epochs | 迭代次数 | 50 |
| learning_rate | 学习率 | 0.001 |
| loss | 损失函数 | MSE |
| optimizer | 优化器 | Adam |
表4 隔离森林实验参数 |
| 实验参数名称 | 解释说明 | 参数设置 |
|---|---|---|
| n_estimators | 隔离森林中隔离树的数量 | 100 |
| max_samples | 每棵隔离树使用的样本数 | auto |
| contamination | 预期的异常样本比例 | 0.1 |
| max_features | 每棵隔离树使用的特征数 | 1.0 |
| bootstrap | 是否在构建隔离树时使用自助采样 | False |
| random_state | 控制随机数生成 | 42 |
表5 基线模型实验参数 |
| 模型 | 实验参数 名称 | 解释说明 | 参数设置 |
|---|---|---|---|
| LOF | n_neighbors | 最近邻样本数量 | 3 |
| p | 距离度量的幂参数 | 2 | |
| algorithm | 计算最近邻的算法 | auto | |
| leaf_size | 叶子节点的大小 | 30 | |
| contamination | 预期的异常点比例 | auto | |
| OCSVM | kernel | 核函数类型 | rbf |
| degree | 多项式核函数度数 | 3 | |
| nu | 异常点的比例 | 0.05 | |
| cache_size | 缓存的数据大小 | 200 | |
| tol | 控制算法的收敛性 | 0.001 |
表6 单一网络检测模型对比 (%) |
| 模型 | 准确率 | 漏报率 | 误报率 | F 1 |
|---|---|---|---|---|
| LOF | 33.11 | 75.60 | 2.96 | 39.11 |
| OCSVM | 78.72 | 21.01 | 23.27 | 86.73 |
| Single-IF | 95.02 | 5.23 | 1.83 | 97.24 |
| Single-AE | 46.25 | 0 | 81.74 | 56.00 |
| AE-IF | 95.13 | 5.22 | 0.30 | 97.31 |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
孙海丽, 龙翔, 韩兰胜, 等. 工业物联网异常检测技术综述[J]. 通信学报, 2022, 43(3): 196-210.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
尚文利, 石贺, 赵剑明, 等. 基于SAE-LSTM的工艺数据异常检测方法[J]. 电子学报, 2021, 49(8): 1561-1568.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
席亮, 王瑞东, 樊好义, 等. 基于样本关联感知的无监督深度异常检测模型[J]. 计算机学报, 2021, 44(11): 2317-2331.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
施媛波.变分自编码器和注意力机制的异常入侵检测方法[J]. 重庆邮电大学学报(自然科学版), 2022,34(6):1071-1078.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
胡向东, 李之涵. 基于胶囊网络的工业互联网入侵检测方法[J]. 电子学报, 2022, 50(6): 1457-1465.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
胡向东, 吕高飞, 白银. 基于优化支持向量回归的工业互联网安全态势预测方法[J]. 电子学报, 2023, 51(2): 446-454.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
杨晓晖, 张圣昌. 基于多粒度级联孤立森林算法的异常检测模型[J]. 通信学报, 2019, 40(8): 133-142.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
袁非牛, 章琳, 史劲亭, 等. 自编码神经网络理论及应用综述[J]. 计算机学报, 2019, 42(1): 203-230.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
GOH J,
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(1435 KB)
PDF(1435 KB)
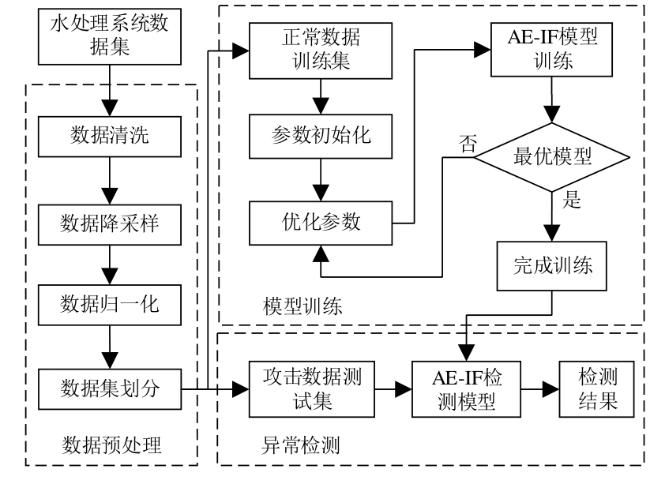
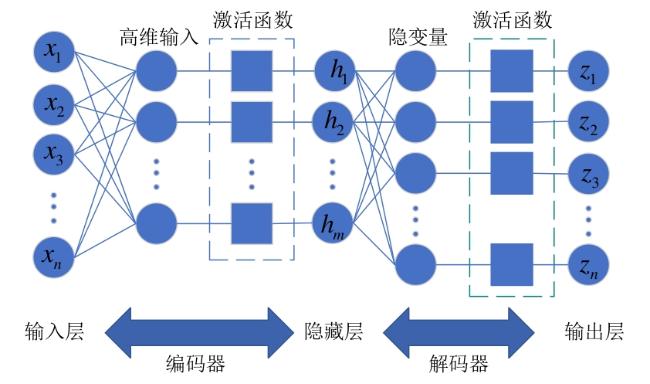
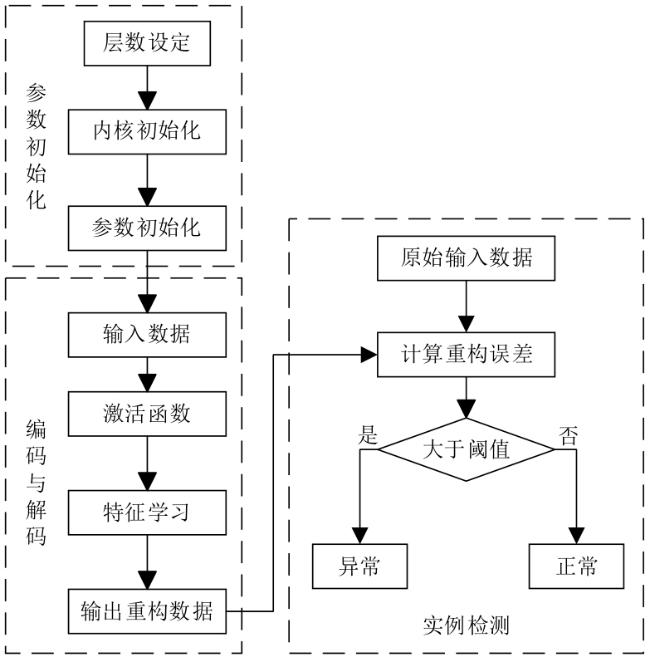
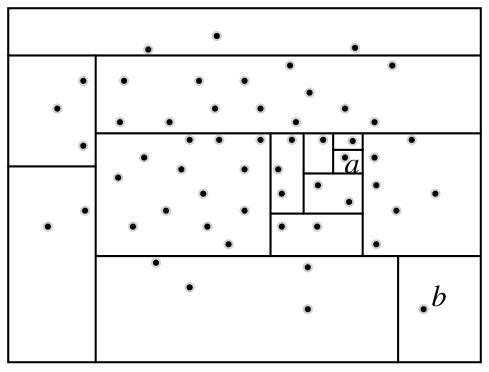
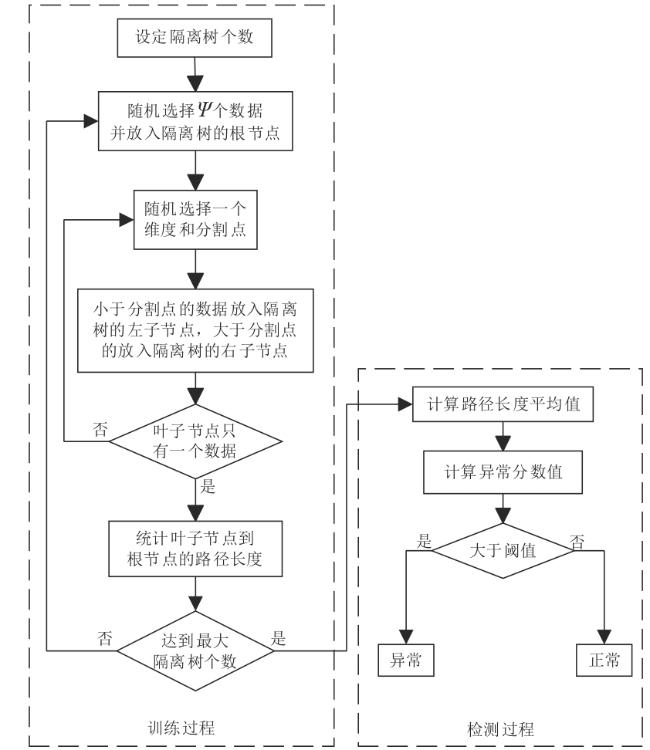
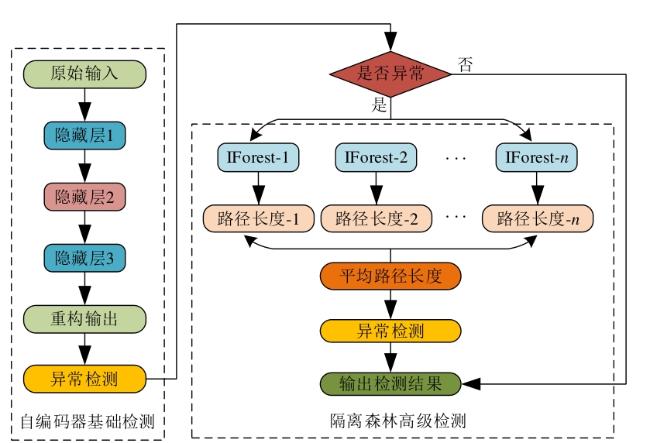
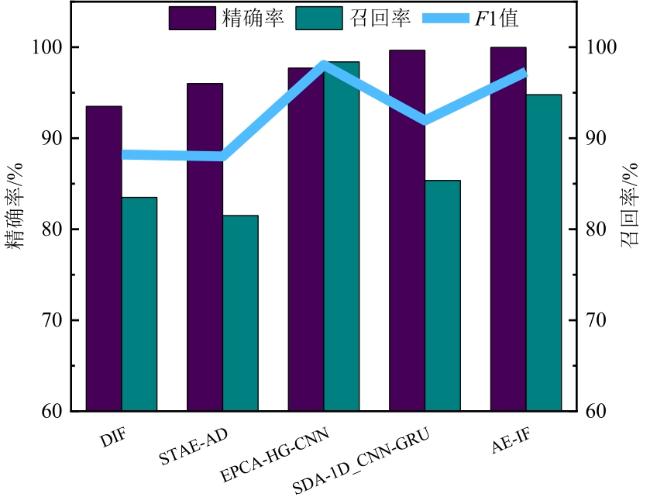
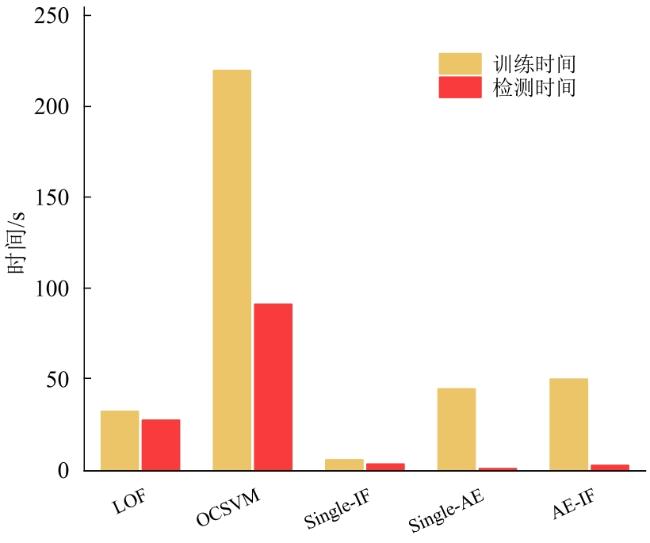
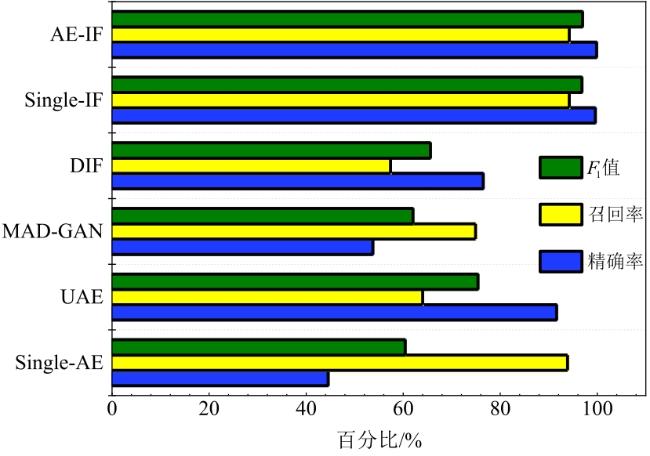
 图1 水处理系统异常检测框架图2 自编码器网络结构图3 自编码器检测流程图4 隔离森林算法的分裂隔离过程图5 隔离森林算法流程
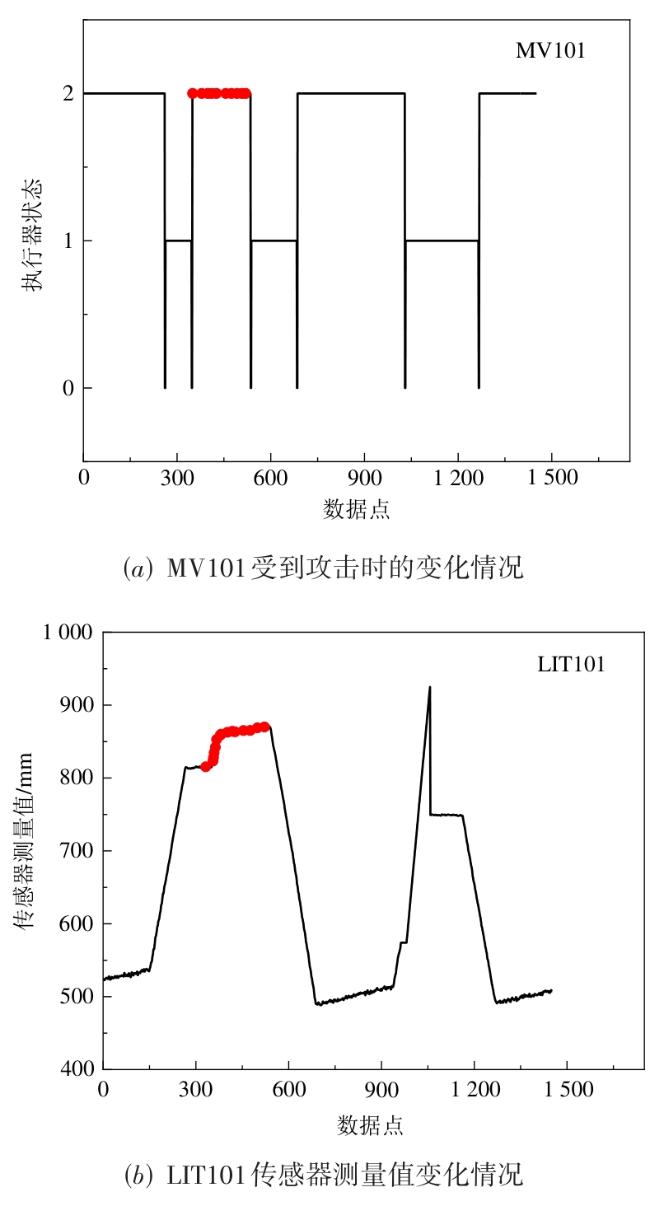
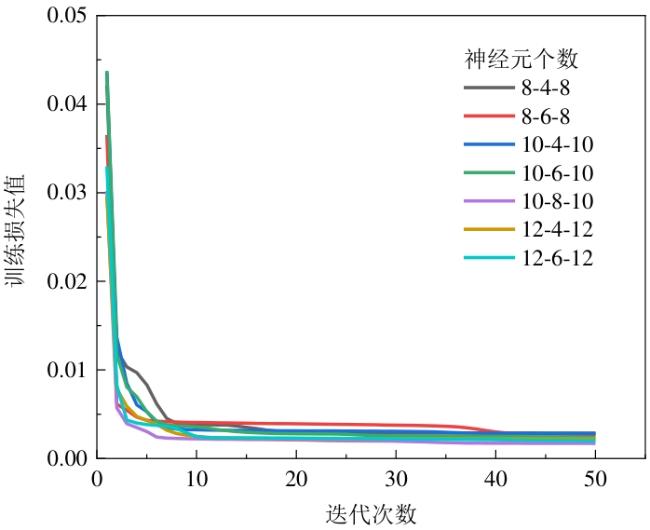
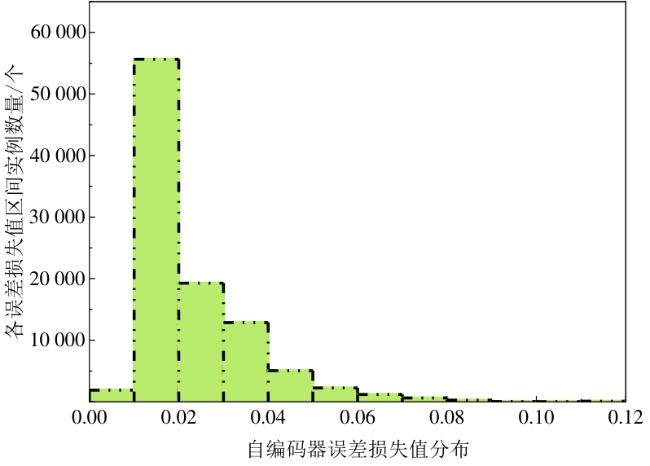
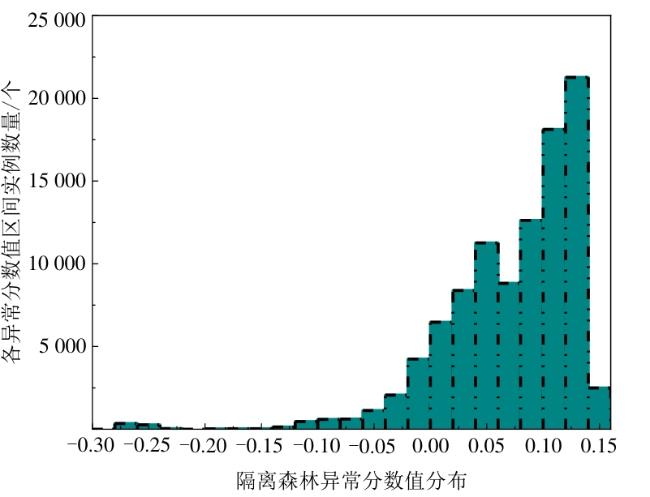
图1 水处理系统异常检测框架图2 自编码器网络结构图3 自编码器检测流程图4 隔离森林算法的分裂隔离过程图5 隔离森林算法流程 图6 AE-IF两阶段异常检测流程图7 SWaT试验台水处理过程表1 SWaT水处理试验台各个阶段传感器与执行器型号图8 WADI试验台配水过程图9 MV101受到攻击时LIT101的变化情况表2 SWaT和WADI数据集样本类别分布表3 自编码器实验参数图10 隐藏层神经元个数训练损失值变化曲线图11 自编码器训练数据误差损失值分布表4 隔离森林实验参数图12 隔离森林训练数据异常分数值分布表5 基线模型实验参数表6 单一网络检测模型对比 (%)图13 检测结果对比图14 模型训练与检测时间对比图15 模型泛化性指标对比
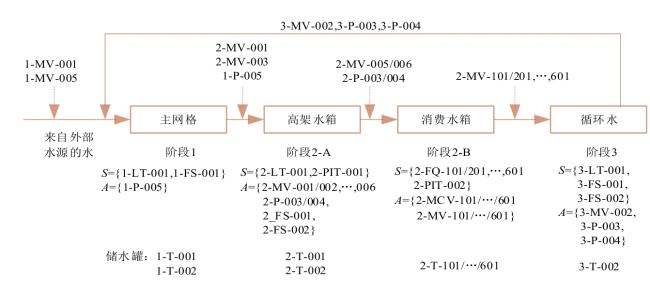
图6 AE-IF两阶段异常检测流程图7 SWaT试验台水处理过程表1 SWaT水处理试验台各个阶段传感器与执行器型号图8 WADI试验台配水过程图9 MV101受到攻击时LIT101的变化情况表2 SWaT和WADI数据集样本类别分布表3 自编码器实验参数图10 隐藏层神经元个数训练损失值变化曲线图11 自编码器训练数据误差损失值分布表4 隔离森林实验参数图12 隔离森林训练数据异常分数值分布表5 基线模型实验参数表6 单一网络检测模型对比 (%)图13 检测结果对比图14 模型训练与检测时间对比图15 模型泛化性指标对比

/
| 〈 |
|
〉 |







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}