 PDF(4060 KB)
PDF(4060 KB)
 PDF(4060 KB)
PDF(4060 KB)
PDF(4060 KB)
PDF(4060 KB)
复杂噪声环境下基于轻量化模型的车内交互语音增强和识别方法
An In-Vehicle Interaction Speech Enhancement and Recognition Method Based on Lightweight Models in Complex Environment
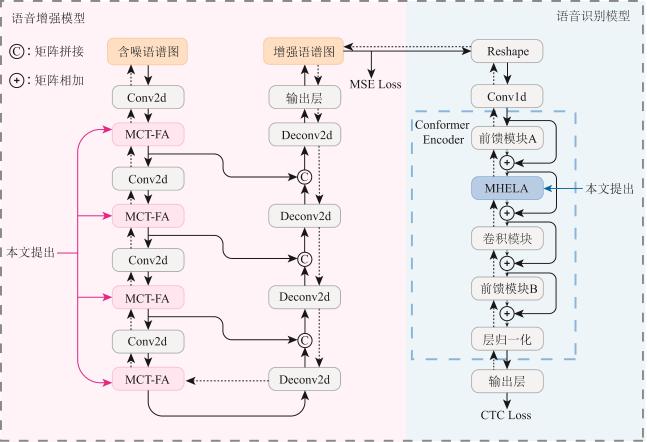
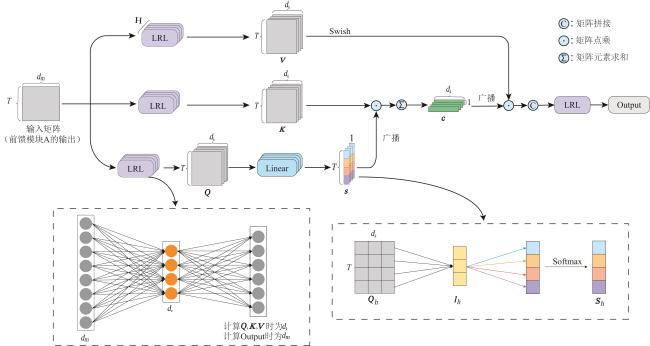
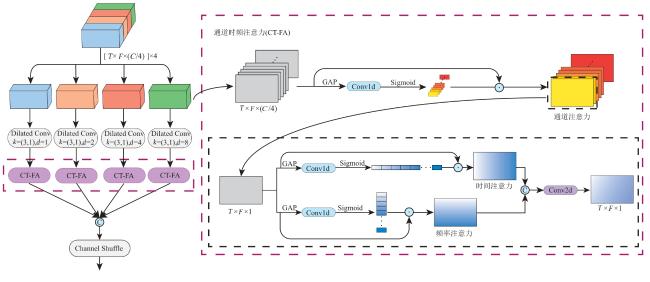
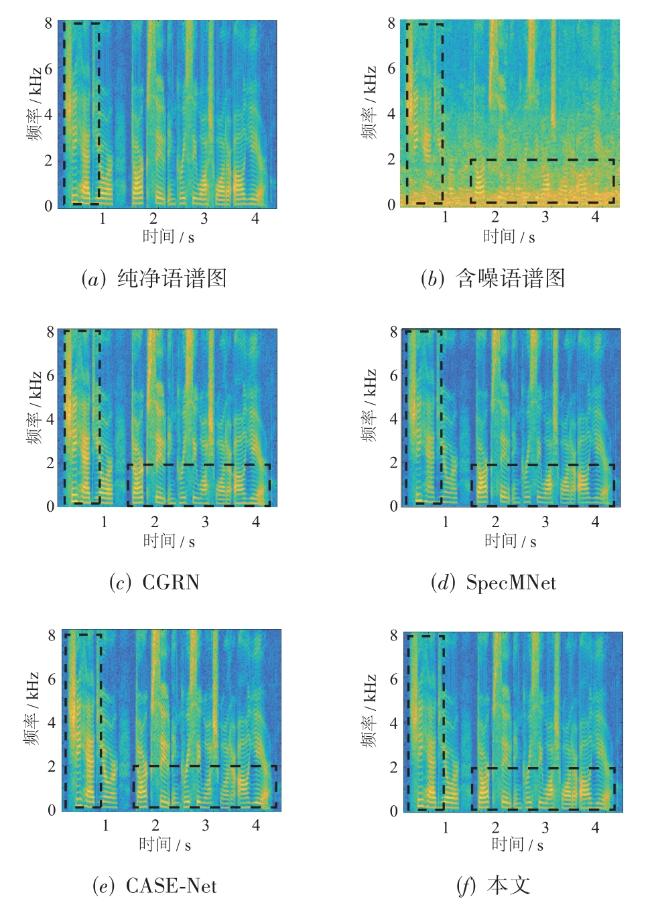
针对车内语音交互在复杂噪声环境下识别率低以及难以在有限计算资源设备上部署问题,本文设计了轻量化的语音增强模型和语音识别模型并进行联合训练.语音增强模型引入多尺度通道时频注意力模块来提取多尺度时频特征和各个维度上的关键信息.在语音识别模型中提出了多头逐元素线性注意力,显著降低了注意力模块所需的计算复杂度.实验表明,在自制数据集上这一联合训练模型表现出良好的噪声鲁棒性.
In order to solve the problem of low recognition rate of in-vehicle voice interaction in complex noise environment and difficult deployment on devices with limited computing resources, this article proposes a lightweight and robust voice recognition method based on joint training framework in the noisy environment. The speech enhancement model introduces a multi-scale channel time-frequency attention module to extract multi-scale time-frequency features and key information in various dimensions. In the speech recognition model, multi-head element-wise linear attention is proposed, which significantly reduces the computational complexity required for the attention module. Experiments show that the joint training model shows good noise robustness on the self-made dataset.
深度学习 / 语音增强 / 语音识别 / 注意力机制 / 联合训练 {{custom_keyword}} /
deep learning / speech enhancement / speech recognition / attention mechanism / joint training {{custom_keyword}} /
表1 不同信噪比下的语音识别模型字错误率对比(T为时间帧数) |
| 对比方法 | 注意力复杂度 | 参数量/M | 信噪比/dB | |||||
|---|---|---|---|---|---|---|---|---|
| | 0 | 5 | 10 | 20 | 平均 | |||
| Conformer | O(T 2) | 30.71 | 21.02 | 10.13 | 6.36 | 2.18 | 0.76 | 8.09 |
| LAC | O(T) | 22.83 | 21.58 | 10.64 | 6.98 | 2.52 | 0.95 | 8.53 |
| GLAC | O(T) | 19.83 | 20.96 | 10.82 | 6.25 | 2.51 | 0.61 | 8.23 |
| 本文 | O(T) | 9.73 | 8.54 | 4.33 | 3.53 | 1.52 | 0.73 | 3.73 |
表2 不同时间帧数下GPU/CPU推理时长对比 (ms) |
| 对比方法 | 时间帧数/个 | |||
|---|---|---|---|---|
| 256 | 512 | 768 | 1 024 | |
| Conformer | 10.51/105.03 | 18.70/210.37 | 29.68/328.56 | 45.74/478.95 |
| LAC | 9.12/115.34 | 12.13/161.86 | 14.75/201.14 | 17.39/291.40 |
| GLAC | 7.63/90.09 | 10.32/124.73 | 13.65/147.96 | 15.39/254.39 |
| 本文方法 | 3.91/41.34 | 5.82/55.68 | 8.28/93.48 | 10.98/159.44 |
| 1 |
袁文浩, 胡少东, 时云龙, 等. 一种用于语音增强的卷积门控循环网络[J]. 电子学报, 2022, 50(12): 2945-2956.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
李宜亭, 屈丹, 杨绪魁, 等. 一种改进的线性注意力机制语音识别方法[J]. 信号处理, 2023, 39(3): 516-525.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|


/
| 〈 |
|
〉 |















{kind=link}
{kind=link}
{kind=link}
{kind=link}