 PDF(1995 KB)
PDF(1995 KB)
 PDF(1995 KB)
PDF(1995 KB)
PDF(1995 KB)
PDF(1995 KB)
基于对比性视觉-文本模型的光场图像质量评估
Quality Assessment of Light Field Images Based on Contrastive Visual-Textual Model
光场图像作为一种能够捕获场景每个位置光线信息的图像类型,在电子成像、医学影像和虚拟现实等领域具有广泛的应用前景.光场图像质量评估(Light Field Image Quality Assessment,LFIQA)旨在衡量此类图像的质量,但当前方法面临视觉效果与文本模态间异构性的重要挑战.为解决上述问题,本文提出了一种基于文本-视觉的多模态光场图像质量评估模型.具体来说,在视觉模态方面,我们设计了多任务模型,结合边缘自动阈值算法有效丰富了光场图像的关键表示特征.在文本模态方面,基于输入噪声特征与预测噪声特征的对比,准确识别光场图像的噪声类别,并验证了噪声预测对优化视觉表示的重要性.基于上述研究,进一步提出了一种优化的通用噪声文本配置方法,并结合边缘增强策略,显著提升了基线模型在光场图像质量评估中的准确性和泛化能力.此外,通过消融实验,评估了各组件对整体模型性能的贡献,验证了本文方法的有效性和稳健性.实验结果表明,该方法不仅在公开数据集Win5-LID和NBU-LF1.0的实验中表现出色,还在融合数据集中展示出优秀的实验结果,与现有最优算法相比,本文所提方法在两个数据库中的性能分别提升了2%和6%.本文提出的噪声验证策略和配置方法不仅为图像质量评估中的噪声预测任务提供了有价值的参考,也可用于其它噪声预测类型的辅助任务.
Light field imaging, as an image type capable of capturing light information from every position in a scene, holds broad application prospects in fields such as electronic imaging, medical imaging, and virtual reality. Light field image quality assessment (LFIQA) aims to measure the quality of such images, yet current methods confront significant challenges arising from the heterogeneity between visual effects and textual modalities. To address these issues, this paper proposes a multi-modal light field image quality assessment model grounded in text-vision integration. Specifically, for the visual modality, we devise a multi-task model that effectively enriches the crucial representational features of light field images by incorporating an edge auto-thresholding algorithm. On the textual side, we accurately identify noise categories in light field images based on the comparison between input noise features and predicted noise features, thereby validating the importance of noise prediction in optimizing visual representations. Building upon these findings, we further introduce an optimized universal noise text configuration approach combined with an edge enhancement strategy, which notably enhances the accuracy and generalization capabilities of the baseline model in LFIQA. Additionally, ablation experiments are conducted to assess the contribution of each component to the overall model performance, thereby verifying the effectiveness and robustness of our proposed method. Experimental results demonstrate that our approach not only excels in tests on public datasets like Win5-LID and NBU-LF1.0 but also shows remarkable outcomes in fused datasets. Compared to the state-of-the-art algorithms, our method achieves performance improvements of 2% and 6% respectively on the two databases. The noise verification strategy and configuration method presented in this paper not only provide valuable insights for light field noise prediction tasks but can also be applied as auxiliary tools for other noise prediction types.
图像质量评估 / 光场图像 / 视觉-文本模型 / 多任务模式 / 噪声预测 / 图像增强 {{custom_keyword}} /
image quality assessment / light field images / visual-textual model / multi-task mode / noise prediction / image enhancement {{custom_keyword}} /
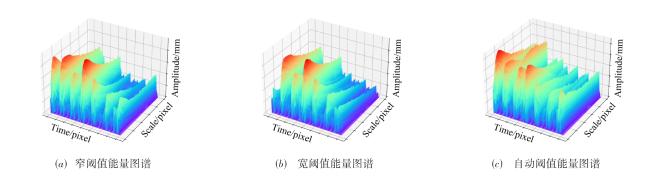
表1 阈值算法结果 |
| 阈值算法 | SROCC |
|---|---|
| 宽阈值 | 0.887 5 |
| 窄阈值 | 0.851 4 |
| 自动阈值 | 0.908 1 |
表2 噪声分类与来源 |
| 噪声名称 | 所属类别 | 所属数据集 |
|---|---|---|
| Linear | Reconstruction | Win5 |
| NN | Reconstruction | Win5、NBU |
| JPEG2000 | Compression | Win5 |
| HEVC | Compression | Win5 |
| VDSR | Reconstruction | NBU |
| Zhang et al. | Reconstruction | NBU |
| BI | Reconstruction | NBU |
| EPICNN | Reconstruction | Win5、NBU |
| USCD | Reconstruction | Win5 |
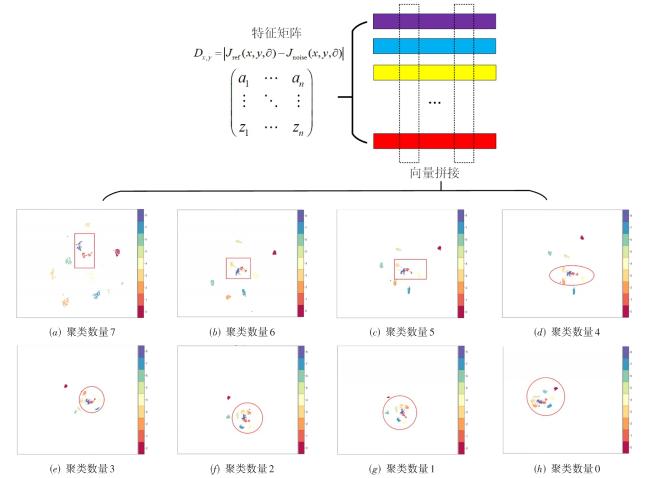
表3 不同聚类数量对应的内存应用情况和模型表现 |
| | | | SROCC | 内存/GB |
|---|---|---|---|---|
| 10 | 6 | 3 | 0.730 6 | 6.4 |
| 25 | 5 | 4 | 0.841 6 | 7.2 |
| 50 | 4 | 5 | 0.851 0 | 8.3 |
| 120 | 3 | 6 | 0.907 7 | 11.2 |
| 160 | 2 | 7 | 0.872 2 | 13.5 |
| 200 | 1 | 8 | 0.870 0 | 15.6 |
表4 与先前的方法比较结果 |
| 方法 | Win5-LID | NBU-LF1.0 | 总体(overall) | 时延/s | |||
|---|---|---|---|---|---|---|---|
| PLCC | SROCC | PLCC | SROCC | PLCC | SROCC | ||
| PSNR[57] | 0.602 6 | 0.618 9 | 0.530 9 | 0.664 8 | — | — | 0.818 8 |
| MDFM[58] | 0.768 6 | 0.733 7 | 0.800 5 | 0.758 4 | 0.723 4 | 0.694 9 | 0.853 7 |
| MP-PSNR[46] | 0.733 5 | 0.676 6 | 0.710 9 | 0.655 0 | 0.679 6 | 0.703 4 | 3.4 |
| BELIF[48] | 0.602 1 | 0.519 5 | 0.708 4 | 0.606 9 | 0.759 2 | 0.720 0 | 207.682 |
| VBLFI[50] | 0.891 0 | 0.871 9 | 0.779 2 | 0.734 9 | 0.768 5 | 0.713 7 | 65.667 |
| NSS-TD[59] | 0.896 9 | 0.878 3 | 0.839 6 | 0.816 5 | — | — | 219.21 |
| NR-LFQA[60] | 0.882 9 | 0.901 5 | 0.849 9 | 0.816 9 | 0.762 1 | 0.713 4 | 183 |
| DeeBLiF[49] | 0.842 7 | 0.818 6 | 0.837 9 | 0.820 4 | 0.891 6 | 0.847 7 | — |
| Xiang's[34] | 0.826 8 | 0.798 2 | 0.849 8 | 0.827 8 | 0.868 8 | 0.847 9 | 128.53 |
| NSTSS[61] | 0.725 8 | 0.672 8 | 0.773 7 | 0.737 7 | — | — | — |
| VIDEVAL[62] | 0.712 3 | 0.665 7 | 0.712 3 | 0.665 7 | 0.733 1 | 0.652 4 | 27.713 |
| 所提方法 | 0.911 6 | 0.908 1 | 0.878 7 | 0.861 5 | 0.890 3 | 0.875 7 | 48.367 |
表5 不同数据集中不同失真类型对视觉-文本模型的影响 |
| 方法 | Win5-LID | NBU-LF1.0 | ||||||
|---|---|---|---|---|---|---|---|---|
| 真实场景 | 合成场景 | 真实场景 | 合成场景 | |||||
| PLCC | SROCC | PLCC | SROCC | PLCC | SROCC | PLCC | SROCC | |
| BRISQUE[12] | — | 0.591 7 | — | 0.549 3 | — | 0.517 6 | — | 0.506 0 |
| NIQE[63] | 0.603 9 | 0.580 5 | 0.557 3 | 0.507 2 | 0.563 1 | 0.409 4 | 0.579 7 | 0.508 9 |
| MDFM[58] | 0.779 6 | 0.756 0 | 0.729 0 | 0.719 7 | 0.835 | 0.809 9 | 0.833 3 | 0.827 2 |
| Tensor-NLFQ[64] | 0.892 | 0.884 | 0.925 | 0.912 | 0.849 | 0.842 | 0.850 | 0.843 |
表6 多任务消融实验 |
| 任务类型 | Win5-LID | NBU-LF1.0 | ||||
|---|---|---|---|---|---|---|
| 质量 | 场景 | 噪声 | PLCC | SRCC | PLCC | SRCC |
| √ | 0.560 | 0.534 | 0.572 | 0.595 | ||
| √ | √ | 0.846 | 0.832 | 0.837 | 0.830 | |
| √ | √ | 0.810 | 0.808 | 0.773 | 0.766 | |
表7 噪声/文本组合消融实验 |
| 实验编号 | 学习率调整 | 场景文本 | 噪声文本 | Canny | Win5-LID | NBU-LF1.0 | ||
|---|---|---|---|---|---|---|---|---|
| PLCC | SROCC | PLCC | SROCC | |||||
| 1 | 否 | 9 | 6 | 否 | 0.751 7 | 0.616 5 | 0.774 0 | 0.614 5 |
| 2 | 是 | 9 | 6 | 否 | 0.810 0 | 0.808 1 | 0.772 5 | 0.765 6 |
| 3 | 是 | 9 | 6 | 是 | 0.846 1 | 0.832 2 | 0.837 2 | 0.829 9 |
| 4 | 是 | 9 | 7 | 是 | 0.871 4 | 0.881 0 | 0.852 5 | 0.838 3 |
| 5 | 是 | 12 | 5 | 是 | 0.859 6 | 0.841 6 | 0.833 5 | 0.830 1 |
| 6 | 是 | 12 | 6 | 是 | 0.831 8 | 0.851 0 | 0.831 0 | 0.831 9 |
| 7 | 是 | 12 | 7 | 是 | 0.893 1 | 0.907 7 | 0.861 2 | 0.845 0 |
| 8 | 是 | 12 | 8 | 是 | 0.877 1 | 0.872 2 | 0.855 5 | 0.834 0 |
| 9 | 是 | 12 | 7 | 是* | 0.911 6 | 0.908 1 | 0.878 7 | 0.861 5 |
| 10 | 是 | 12 | 8 | 是* | 0.900 7 | 0.887 1 | 0.861 6 | 0.858 0 |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
林华. 无人机载太赫兹合成孔径雷达成像分析与仿真[J]. 信息与电子工程, 2010, 8(4): 373-377.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
刘慧芳, 周骛, 蔡小舒, 等. 基于光场成像的三维粒子追踪测速技术[J]. 光学学报, 2020, 40(1): 0111014.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 19 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 20 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 21 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 22 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 23 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 24 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 25 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 26 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 27 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 28 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 29 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 30 |
陈琦, 徐熙平, 姜肇国, 等. 基于光场相机的四维光场图像水印及质量评价[J]. 光学学报, 2018, 38(4): 0411003.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 31 |
赵圆圆, 施圣贤. 融合多尺度特征的光场图像超分辨率方法[J]. 光电工程, 2020, 47(12): 200007.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 32 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 33 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 34 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 35 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 36 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 37 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 38 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 39 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 40 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 41 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 42 |
黄虹, 张建秋. 一个图像质量盲评估的统计测度[J]. 电子学报, 2014, 42(7): 1419-1423.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 43 |
王长淼, 李晖, 张水平, 等. 基于深度学习的光场显微像差校正[J]. 光学学报, 2024, 44(14): 90-99.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 44 |
梁丹, 张海苗, 邱钧. 基于自监督学习的光场空间域超分辨成像[J]. 激光与光电子学进展, 2024, 61(4): 172-184.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 45 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 46 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 47 |
叶佳, 张建秋, 胡波. 客观评估彩色图像质量的超复数奇异值分解法[J]. 电子学报, 2007, 35(1): 28-33.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 48 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 49 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 50 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 51 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 52 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 53 |
李季瑀, 付章杰, 王帆. Canny-Gauss通用域图像隐写算法[J]. 计算机学报, 2024, 47(1): 213-230.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 54 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 55 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 56 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 57 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 58 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 59 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 60 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 61 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 62 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 63 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 64 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 65 |
刘玉轩, 张力, 艾海滨, 等. 光场相机三维重建研究进展与展望[J]. 电子学报, 2022, 50(7): 1774-1792.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 66 |
周广福, 文成林, 高敬礼. 基于小波变换与稀疏傅里叶变换相结合的光场重构方法[J]. 电子学报, 2017, 45(4): 782-790.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
感谢福州大学计算机与大数据学院以及中国地震局工程力学研究所对本实验提供的硬件和软件支持.参考文献



 PDF(1995 KB)
PDF(1995 KB)
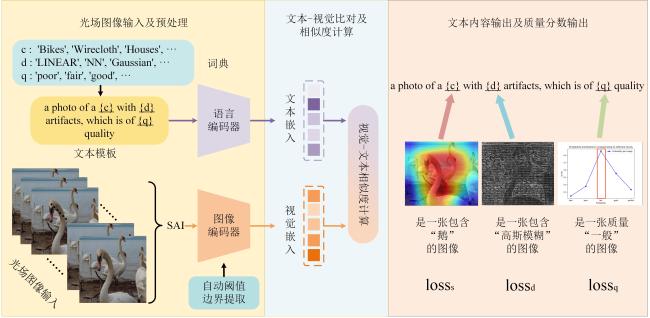
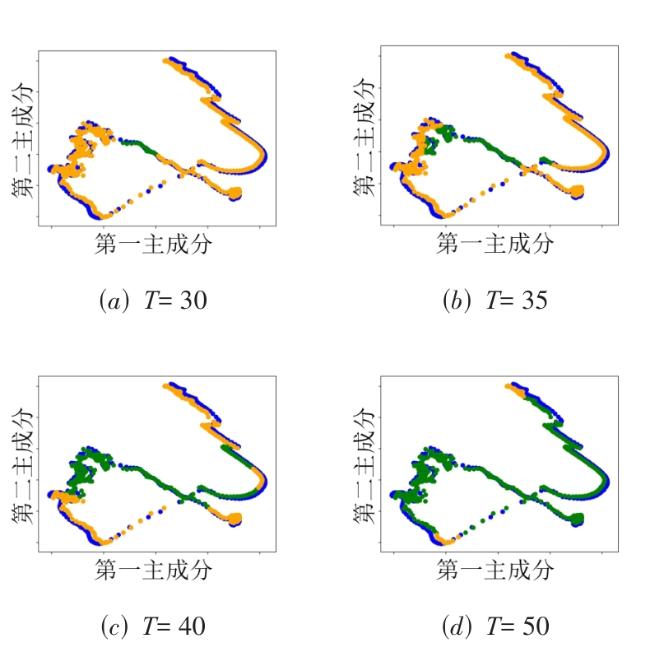
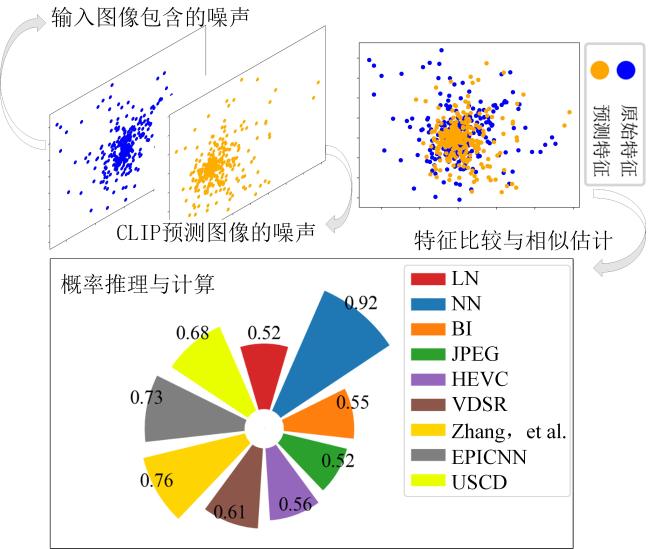
 图1 基于CLIP模型的光场图像质量评估方法概念图图2 不同边缘检测算法效果不同
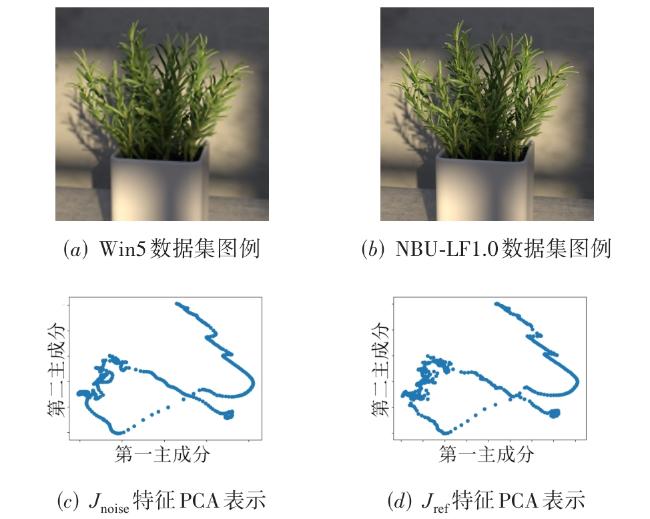
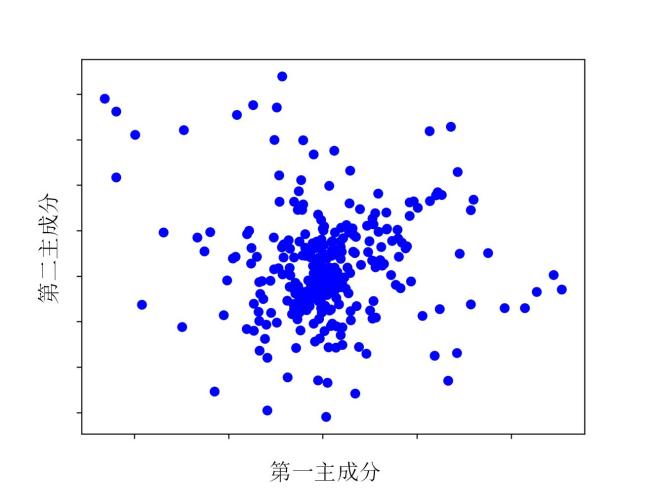
图1 基于CLIP模型的光场图像质量评估方法概念图图2 不同边缘检测算法效果不同 表1 阈值算法结果图3 宽、窄、自动阈值作用于同一个图像时的边缘效果图4 不同阈值算法的时间-小波-能量图谱图5 不同数据集中包含相同场景的图片及特征图6 J n o i s e中包含的噪声特征表示图7 阈值 T不同时噪声散点的分布情况图8 CLIP的噪声预测流程表2 噪声分类与来源图9 表3UMAP视角下的噪声聚类效果不同聚类数量对应的内存应用情况和模型表现表3 不同聚类数量对应的内存应用情况和模型表现表4 与先前的方法比较结果表5 不同数据集中不同失真类型对视觉-文本模型的影响表6 多任务消融实验表7 噪声/文本组合消融实验
表1 阈值算法结果图3 宽、窄、自动阈值作用于同一个图像时的边缘效果图4 不同阈值算法的时间-小波-能量图谱图5 不同数据集中包含相同场景的图片及特征图6 J n o i s e中包含的噪声特征表示图7 阈值 T不同时噪声散点的分布情况图8 CLIP的噪声预测流程表2 噪声分类与来源图9 表3UMAP视角下的噪声聚类效果不同聚类数量对应的内存应用情况和模型表现表3 不同聚类数量对应的内存应用情况和模型表现表4 与先前的方法比较结果表5 不同数据集中不同失真类型对视觉-文本模型的影响表6 多任务消融实验表7 噪声/文本组合消融实验

/
| 〈 |
|
〉 |











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}