 PDF(1449 KB)
PDF(1449 KB)
 PDF(1449 KB)
PDF(1449 KB)
PDF(1449 KB)
PDF(1449 KB)
边缘视频处理的细粒度划分与重组部署算法
Fine-Grained Partitioning and Reorganization Deployment Strategy of Edge Video Processing
随着视频数据的迅速增长,大规模视频处理业务需求急剧增加.如何及时处理视频数据获取有效信息,进而向用户快速提供视频分析业务是亟待解决的重要问题.针对此问题,提出一种面向大规模视频处理的边缘功能模块化及重组部署方法(EFMR).该方法将视频处理业务下沉到网络边缘,利用网络功能虚拟化,将边缘服务器中的视频业务请求根据其内在相关性进行功能细粒度划分,按需匹配并最大化复用资源,实现重组部署,从而以较小代价实现边缘视频业务处理功能的平滑扩展.实验结果表明,EFMR方法不仅降低了边缘服务器的接入与响应时延、业务的推理时间,而且还节省了大量的计算资源,提高了视频处理业务部署速度.
With the rapid growth of video data, the demand for large-scale video processing tasks increases dramatically. How to process video data in time to obtain effective information and provide users with video analysis services quickly is an important issue to be solved. Aiming at this problem, a new deployment method of Edge Functions Modularized and Reorganized (EFMR) for large-scale video processing is proposed. This method sinks video processing services to the edge of the network. Using network function virtualization, video service requests sent to the edge server are divided fine-grainedly based on their inherent process correlation, and resources are matched and redeployed on demand based on the division results. In this way, we can smoothly expand the edge video service processing capabilities at a small cost. Experimental results show that EFMR method not only greatly reduces the edge server’s access and response delay, reduces the inference time, but also saves a lot of computing resources of edge servers and speeds up the deployment of video processing services.
移动边缘计算 / 网络功能虚拟化 / 模块化 / 重组 / 细粒度 {{custom_keyword}} /
mobile edge computing / network function virtualization / modular / reorganized / fine-grained {{custom_keyword}} /
表1 AlexNet模型浮点运算量 |
| 层类型 | 浮点运算量(FLOPs) |
|---|---|
| 卷积层1(11×11, 4, 96, ReLU) | 105M |
| 卷积层2(5×5, 1, 256, ReLU) | 223M |
| 卷积层3(3×3, 1, 384, ReLU) | 149M |
| 卷积层4(3×3, 1, 384, ReLU) | 112M |
| 卷积层5(3×3, 1, 256, ReLU) | 74M |
| 全连接层1(4096, ReLU) | 37M |
| 全连接层2(4096, ReLU) | 16M |
| 全连接层3(1000) | 4M |
表2 RCNN完整检测过程时间 |
| 过程 | AlexNet | VGG16 |
|---|---|---|
| 疑似出现物体框 | 12s | 12s |
| 检测出目标 | 15s | 18s |
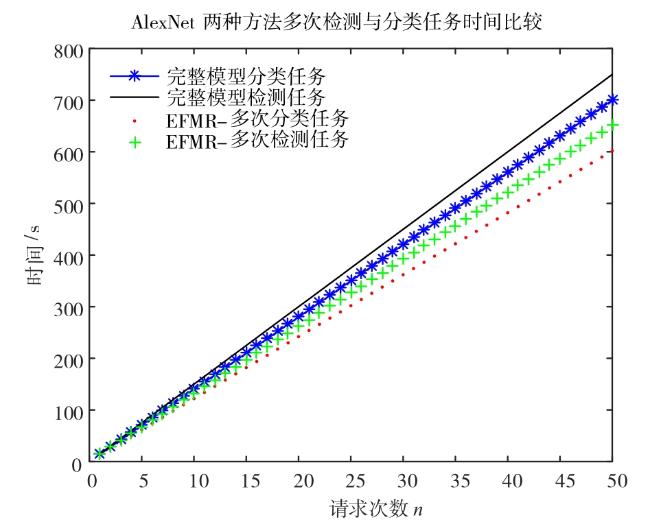
表3 多次业务请求执行时间(AlexNet) |
| 模块 | 第一次业务(分类) | 再一次业务(检测) |
|---|---|---|
| AlexNet特征提取 | 2s | 0s |
| 分类模块 | 12s | / |
| 检测模块 | / | 13s |
| 总时间 | 14s | 13s |
表4 多次业务请求执行时间(VGG16) |
| 模块 | 第一次业务(分类) | 再一次业务(检测) |
|---|---|---|
| VGG16特征提取 | 2s | 0s |
| 分类模块 | 15s | / |
| 检测模块 | / | 16s |
| 总时间 | 17s | 16s |
表5 AlexNet网络参数及每层计算量和参数数量 |
| 类型 | 卷积核/步长/通道数 | FLOPs | 参数量 |
|---|---|---|---|
| 卷积层(ReLU) | 11×11/4/96 | 105M | 35K |
| 最大值池化层 | 3×3/2 | / | / |
| 卷积层(ReLU) | 5×5/1/256 | 223M | 307K |
| 最大值池化层 | 3×3/2 | / | / |
| 卷积层(ReLU) | 3×3/1/384 | 149M | 884K |
| 卷积层(ReLU) | 3×3/1/384 | 112M | 1.3M |
| 卷积层(ReLU) | 3×3/1/256 | 74M | 442K |
| 最大值池化层 | 3×3/2 | / | / |
| 全连接层(ReLU) | 4096 | 37M | 37M |
| 全连接层(ReLU) | 4096 | 16M | 16M |
| 全连接层(1000) | 17 | 69K | 69K |
表6 VGG16网络参数及每层计算量和参数数量 |
| 类型 | 卷积核/步长/通道数 | FLOPs |
|---|---|---|
| 卷积层(ReLU) | 3×3/1/64 | 870M 1849M |
| 卷积层(ReLU) | 3×3/1/64 | |
| 最大值池化层 | 2×2/2 | / |
| 卷积层(ReLU) | 3×3/1/128 | 925M 1850M |
| 卷积层(ReLU) | 3×3/1/128 | |
| 最大值池化层 | 3×3/2 | / |
| 卷积层(ReLU) | 3×3/1/256 | 925M 1850M 1850M |
| 卷积层(ReLU) | 3×3/1/256 | |
| 卷积层(ReLU) | 3×3/1/256 | |
| 最大值池化层 | 3×3/2 | / |
| 卷积层(ReLU) | 3×3/1/512 | 925M 1850M 1850M |
| 卷积层(ReLU) | 3×3/1/512 | |
| 卷积层(ReLU) | 3×3/1/512 | |
| 最大值池化层 | 3×3/2 | / |
| 卷积层(ReLU) | 3×3/1/512 | 462M 462M 462M |
| 卷积层(ReLU) | 3×3/1/512 | |
| 卷积层(ReLU) | 3×3/1/512 | |
| 最大值池化层 | 3×3/2 | / |
| 全连接层(ReLU) | 4096 | 103M |
| 全连接层(ReLU) | 4096 | 17M |
| 全连接层 | 17 | 0.069M |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(1449 KB)
PDF(1449 KB)
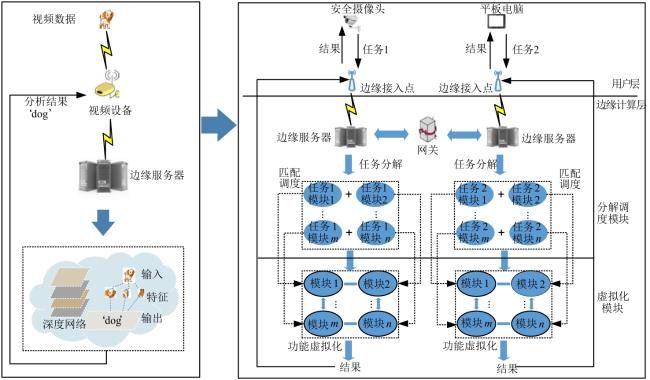
 图1 边缘服务器视频处理功能部署方法示意图
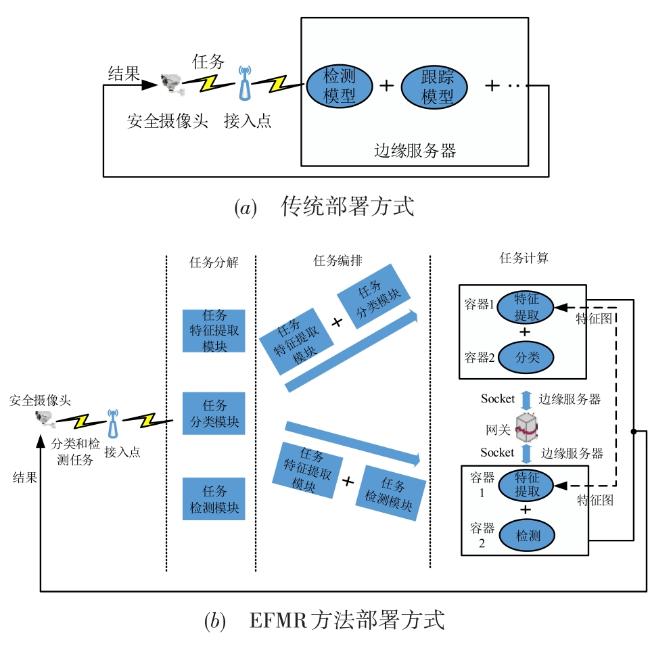
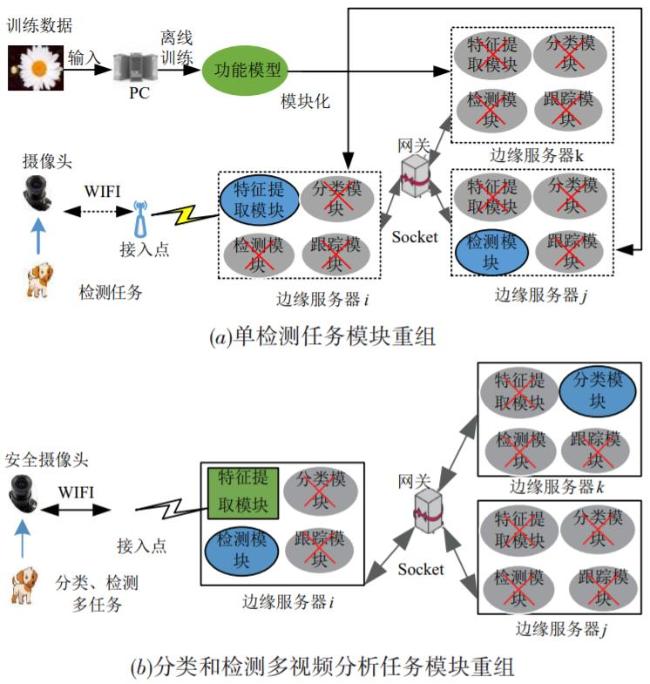
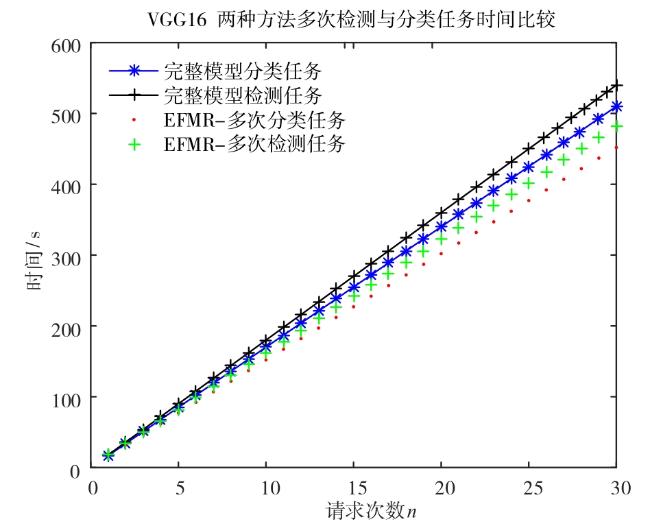
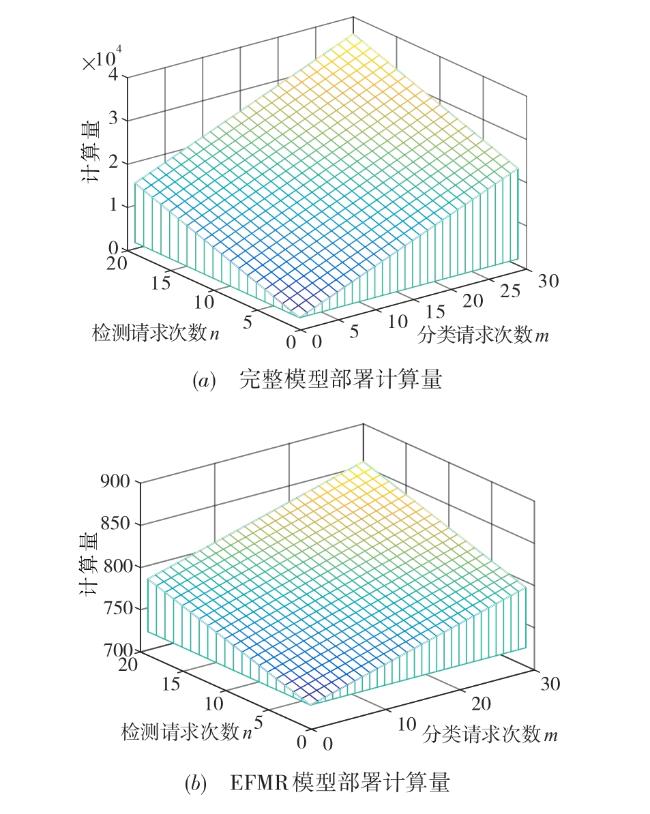
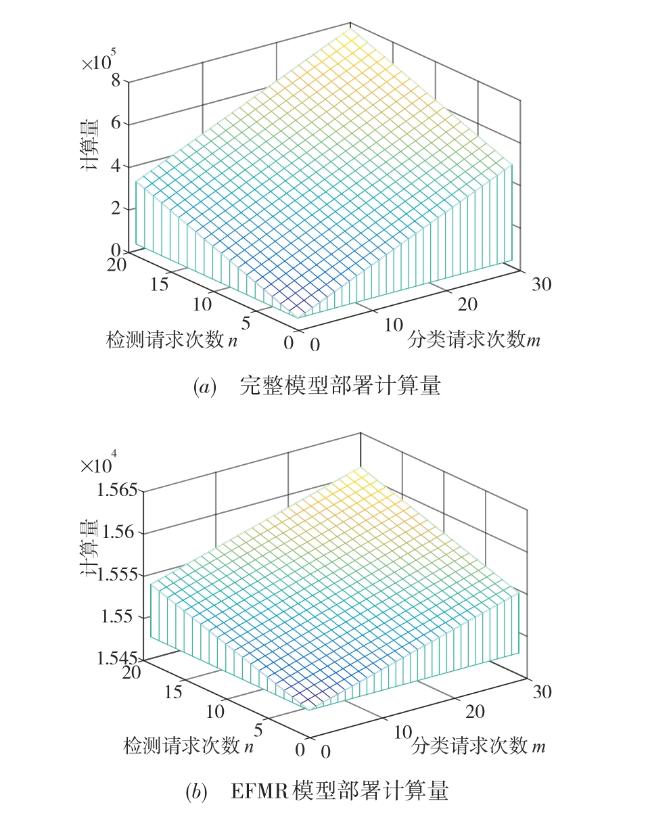
图1 边缘服务器视频处理功能部署方法示意图 表1 AlexNet模型浮点运算量图2 两种功能部署方法比较图3 EFMR方法多次视频分析任务模块资源重组情况表2 RCNN完整检测过程时间表3 多次业务请求执行时间(AlexNet)表4 多次业务请求执行时间(VGG16)图4 不同部署方式执行时间(Bone:AlexNet)图5 不同部署方式执行时间(Bone:VGG16)表5 AlexNet网络参数及每层计算量和参数数量图6 两种部署方式边缘服务器计算量(Bone:AlexNet)表6 VGG16网络参数及每层计算量和参数数量图7 两种部署方式边缘服务器计算量(Bone:VGG16)
表1 AlexNet模型浮点运算量图2 两种功能部署方法比较图3 EFMR方法多次视频分析任务模块资源重组情况表2 RCNN完整检测过程时间表3 多次业务请求执行时间(AlexNet)表4 多次业务请求执行时间(VGG16)图4 不同部署方式执行时间(Bone:AlexNet)图5 不同部署方式执行时间(Bone:VGG16)表5 AlexNet网络参数及每层计算量和参数数量图6 两种部署方式边缘服务器计算量(Bone:AlexNet)表6 VGG16网络参数及每层计算量和参数数量图7 两种部署方式边缘服务器计算量(Bone:VGG16)

/
| 〈 |
|
〉 |







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}