 PDF(3805 KB)
PDF(3805 KB)
 PDF(3805 KB)
PDF(3805 KB)
PDF(3805 KB)
PDF(3805 KB)
RTL级可扩展高性能数据压缩方法实现
Implementation of RTL Scalable High-Performance Data Compression Method
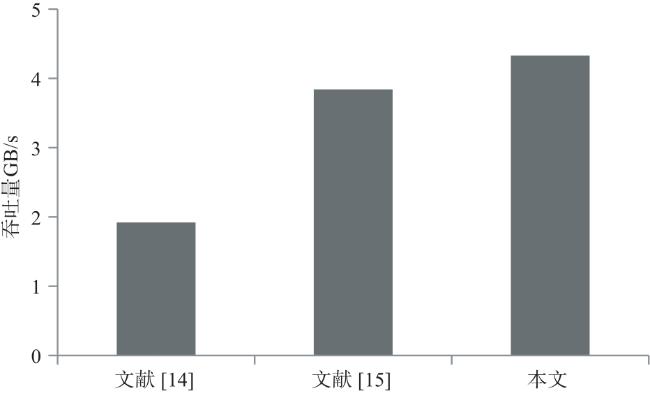
针对传统的数据压缩实现方法处理性能较低,难以满足高速网络高负载、低能耗要求,本文提出了基于FPGA(Field-Programmable Gate Array)的高性能数据压缩方法.在数据计算方面,定制化一种专用并行数据匹配方法,并对压缩算法进行子任务划分,设计细粒度的串/并混合结构实现数据压缩和数据编码;在数据存储方面,设计了面向硬件的专用高效字典处理,并采用多级缓存机制优化访存结构;基于FPGA的资源面积,设计了多通道、可扩展数据压缩结构,并采用轮询策略实现多通道的数据分配和回收;在优化过程中,采用RTL(Register Transfer Level)实现数据压缩算法.实验结果表明优化后的压缩算法与CPU相比达到了1.634的加速比,吞吐量为4.33 Gb/s.
As the low processing performance makes traditional data compression implementation methods difficult to meet the high load and low energy consumption requirements of high-speed networks, a high-performance data compression method based on field-programmable gate array is proposed. In terms of data calculation, this paper customize a dedicated parallel data matching method, divide the compression algorithm into sub-tasks, and design a fine-grained serial/parallel hybrid structure to achieve data compression and data encoding. In terms of data storage, a dedicated and efficient dictionary processing for hardware is designed, and a multi-level cache mechanism is used to optimize the memory access structure. Based on the resource area of FPGA, a multi-channel, scalable data compression structure is designed, and a polling strategy is used to realize multi-channel data allocation and recovery. In the optimization process, register transfer level is used to realize the data compression algorithm. The experimental results show that the optimized compression algorithm achieves a speedup ratio of 1.634 compared with the CPU, with a throughput of 4.33 Gb/s.
数据压缩 / FPGA / 多通道 / 并行匹配 / 多级缓存 {{custom_keyword}} /
data compression / field-programmable gate array / multi-channel / parallel matching / multi-level cache {{custom_keyword}} /
| |
|---|
| 输入:dict[hash], window 输出:match_len 1. len←0; 2. FOR i←0 to 5 /*每组数据匹配*/ 3. compare ← dict[hash] [i]; 4. FOR j←0 to 5 /*逐个字节匹配*/ 5. IF (compare[j] = = window[j])THEN 6. len← len+1; 7. ELSE 8. break; 9. END IF 10. END FOR 11. IF(match_len > len) THEN /*获取最长匹配*/ 12. match_len← match_len; 13. ELSE 14. match_len←len, len←0; 15. END IF 16. END FOR |
| |
|---|
| 输入:dict[hash], window 输出:match_len 1. GENERATE i←0 to 5 /*并行模块*/ 2. compare←dict[hash][i]; 3. FOR k←0 to 5 PAR-DO /*并行字节匹配*/ 4. IF (compare[k] = = window[k]) THEN 5. flag[k] ←1; 6. ELSE flag[k] ←0; 7. END IF 8. END FOR 9. len[i] ←function_long(flag) ;/*获取匹配长度*/ 10. END GENERATE 11. match_len←function_max(len) ;/*获取匹配长度*/ |
| |
|---|
| 输入:compare,window 输出:flag 1. FOR m←0 to 5 PAR-DO /*第1个时钟*/ 2. buff_com[m] ← compare [m]; 3. buff_win[m] ← window[m]; 4. END FOR 5. FOR n←0 to 5 PAR-DO /*第2个时钟*/ 6. flag[n] ← (buff_com[n]= =buff_win[n]) ? 1'b1:1'b0; 7. END FOR |
| |
|---|
| 输入:mutilData[255:0] ,validIn 输出:singleData[7:0],validOut 1. /* 第一部分:计数器*/ 2. count← count + 1 3. IF(count= =0) THEN 4. 获取输入值 5. END IF 6. /* 第二部分:流水线输出 */ 7. IF(validIn= =1) THEN 8. tempData[255:0] ← mutilData[255:0]; 9. tempFlag[31:0] ←32'hFFFF; 10. ELSE 11. tempData[255:0] ← tempData[255:0]>>8; 12. tempFlag[31:0] ← tempFlag[31:0]>>1; 13. END IF 14. singleData[7:0] ← tempData[7:0]; 15. validOut← tempFlag[0]; |
表1 主要模块资源占用 |
| 模块 | LUT | FF | Slice | Block RAM |
|---|---|---|---|---|
| 数据压缩 | 1 547 | 1 551 | 790 | 52 |
| 数据编码 | 351 | 535 | 156 | 2 |
| Snappy核心 | 1 898 | 2 086 | 946 | 54 |
| 顶层控制 | 1 243 | 2 709 | 553 | 13.4 |
| 数据通信 | 723 | 2 037 | 558 | 10 |
表2 不同数据压缩速度 |
| 数据类型 | 压缩速度MB/s |
|---|---|
| 网络数据包 | 146.21 |
| 字典文件 | 146.51 |
| 数据库文件 | 146.95 |
| FPGA下载文件 | 147.00 |
| Html文件 | 147.00 |
表3 四通道下Snappy算法资源占用 |
| 模块 | LUT | FF | Block RAM |
|---|---|---|---|
| Snappy0 | 2 417 | 3 861 | 54 |
| Snappy1 | 2 849 | 3 862 | 54 |
| Snappy2 | 2 793 | 3 862 | 54 |
| Snappy3 | 2 381 | 3 862 | 54 |
| 顶层控制 | 1 462 | 2 198 | 43.5 |
表4 不同板卡单核算法对比 |
| 设计 | Xilinx Snappy Streaming | 本文 |
|---|---|---|
| LUT | 3 000 | 1 898 |
| FF | 3 500 | 2 086 |
| 频率 | 300 MHz | 148 MHz |
| 吞吐量 | 260 MB/s | 148 MB/s |
| PRR | 0.087 | 0.078 |
| 芯片工艺 | 16 nm | 28 nm |
表5 不同板卡对比 |
| 设计 | 吞吐量 | 价格 | 性价比 |
|---|---|---|---|
| Alveo U200 | 8 192 MB/s | 99 500 | 0.082 |
| Zynq-7035 | 554 MB/s | 3 700 | 0.15 |
| 1 |
周俊, 沈华杰, 林中允, 等.边缘计算隐私保护研究进展[J].计算机研究与发展, 2020, 57(10): 2027-2051.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
王超, 王腾, 马翔, 周学海.基于FPGA的机器学习硬件加速研究进展[J].计算机学报, 2020, 43(6): 1161-1182.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|



 PDF(3805 KB)
PDF(3805 KB)
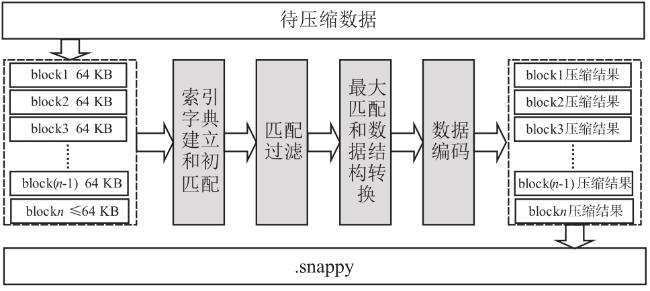
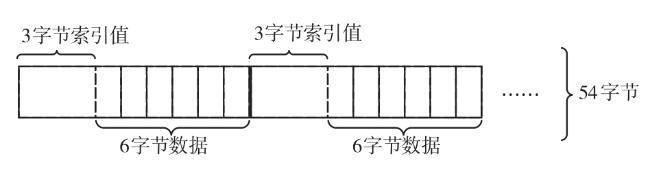
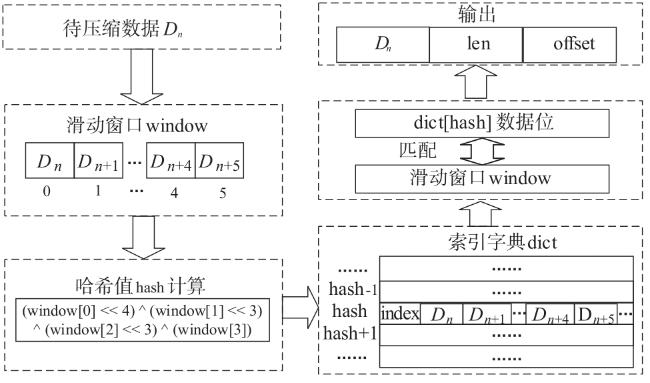
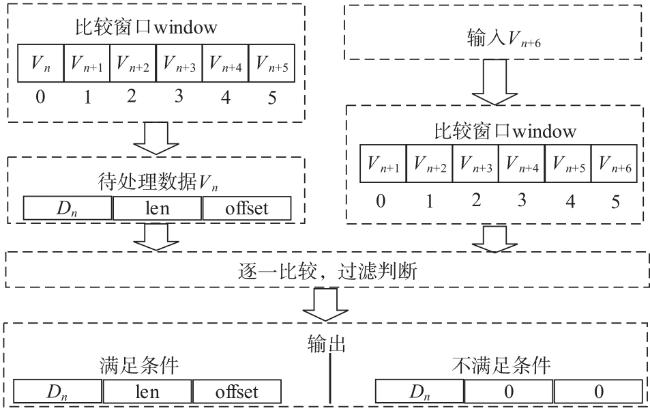
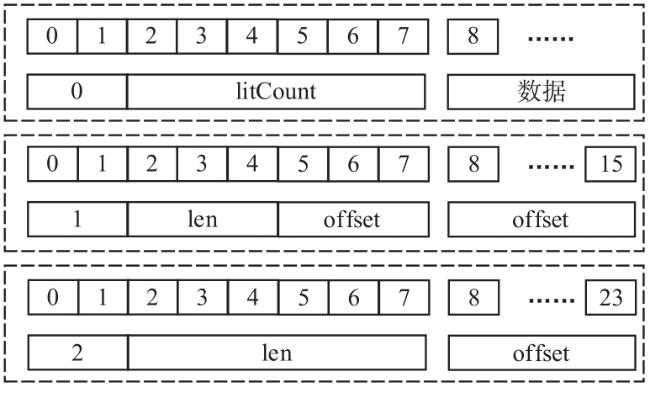
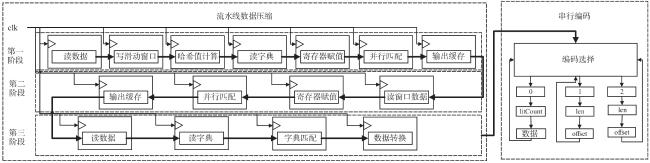
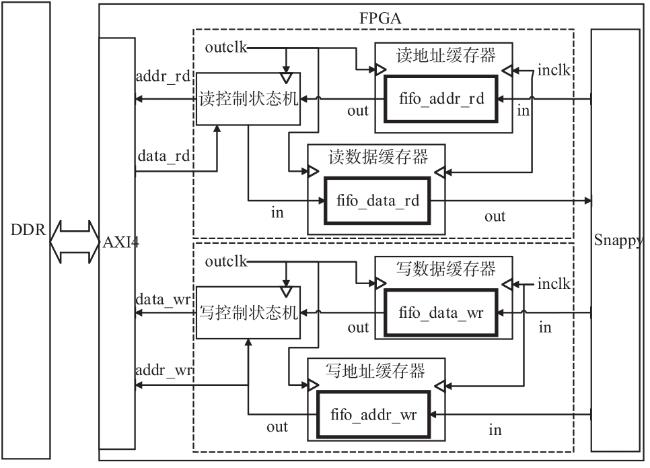
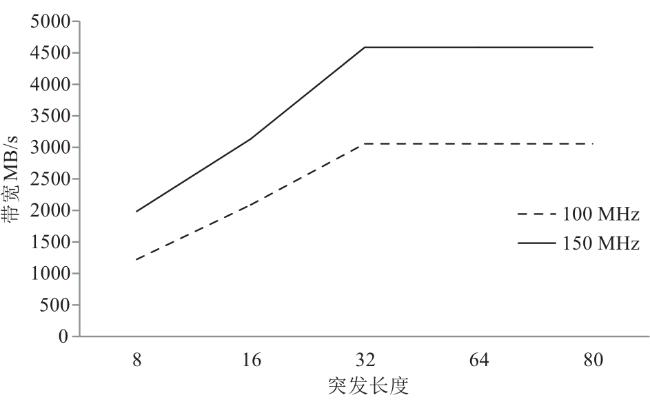
 图1 Snappy数据压缩框架图2 索引字典存储结构图3 压缩第一阶段处理结构图图4 压缩第二阶段处理结构图图5 编码格式
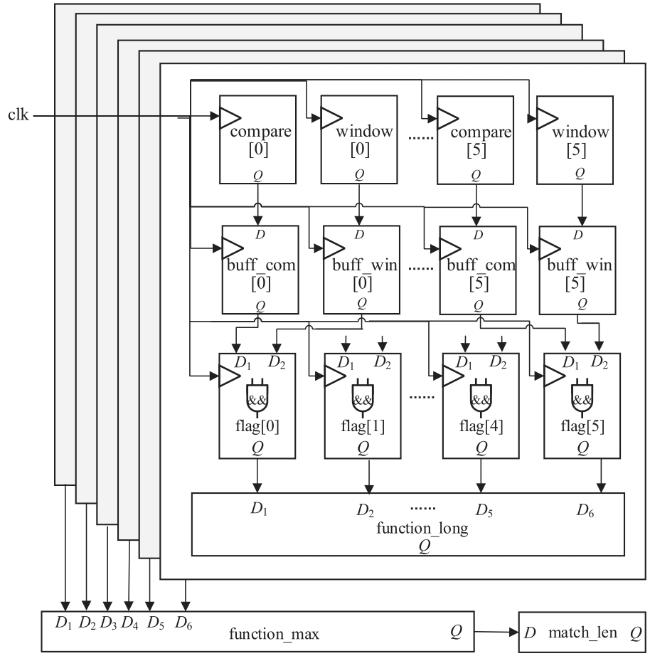
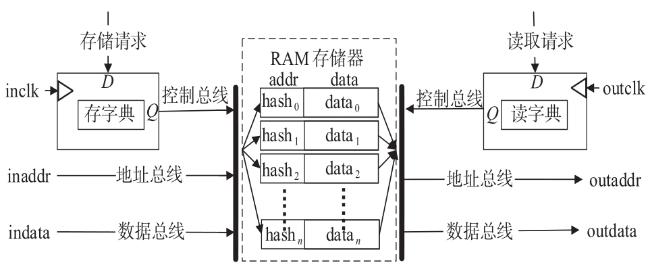
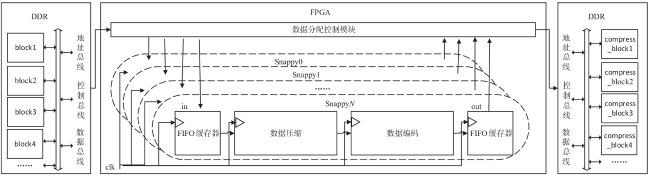
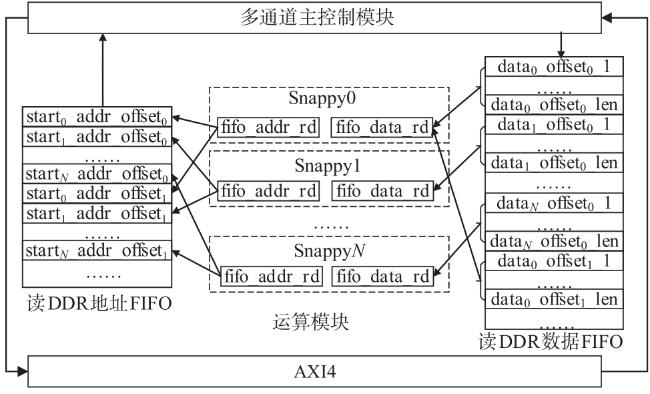
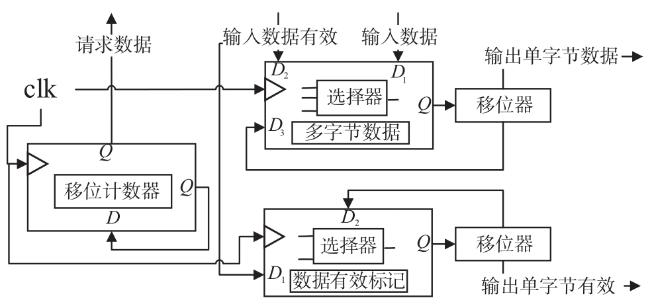
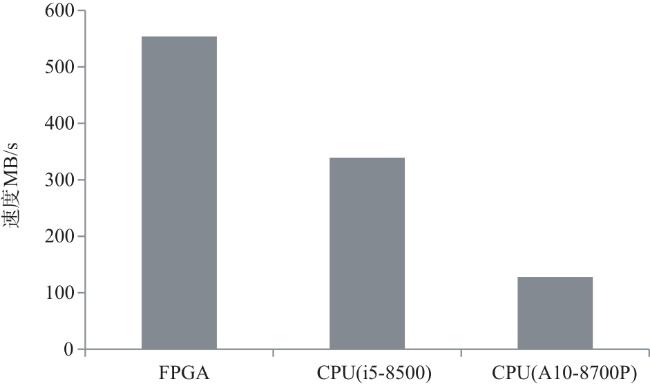
图1 Snappy数据压缩框架图2 索引字典存储结构图3 压缩第一阶段处理结构图图4 压缩第二阶段处理结构图图5 编码格式 图6 定制化并行匹配硬件实现结构图7 Snappy算法实现结构图8 字典实现及操作结构图9 访存优化结构图10 多通道并行结构图11 访存数据轮询存储结构图12 单字节转换硬件实现原理图13 在不同频率下FPGA与DDR通信带宽表1 主要模块资源占用表2 不同数据压缩速度表3 四通道下Snappy算法资源占用图14 不同芯片性能对比图15 性能对比表4 不同板卡单核算法对比表5 不同板卡对比
图6 定制化并行匹配硬件实现结构图7 Snappy算法实现结构图8 字典实现及操作结构图9 访存优化结构图10 多通道并行结构图11 访存数据轮询存储结构图12 单字节转换硬件实现原理图13 在不同频率下FPGA与DDR通信带宽表1 主要模块资源占用表2 不同数据压缩速度表3 四通道下Snappy算法资源占用图14 不同芯片性能对比图15 性能对比表4 不同板卡单核算法对比表5 不同板卡对比

/
| 〈 |
|
〉 |








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}